《泡池子》专题
-
具有有限队列的线程池
问题内容: 我已经看到了线程池执行程序的实现及其所提供的拒绝执行策略。但是,我有一个自定义要求- 我想拥有一个回调机制,在该机制中,当达到队列大小限制时,我会收到通知,并说何时队列大小减少到最大允许队列大小的80%。 我觉得可以通过子类化线程池执行程序来实现,但是已经有一个实现的版本吗?我很乐意在需要时提供更多详细信息和我的工作,以便提供清晰的信息。 问题答案: 我希望有一个回调机制,当达到队列大
-
Java中的字符串池是什么?
问题内容: 我对Java中的StringPool感到困惑。我在阅读Java中的String一章时遇到了这个问题。用外行的术语,请帮助我了解StringPool的实际作用。 问题答案: 打印(即使我们不使用方法:比较字符串的正确方法) 当编译器优化你的字符串文字时,它会看到两者s和t具有相同的值,因此你只需要一个字符串对象。这是安全的,因为在中是不可变的。 结果,两者和都t指向同一个对象,节省了一些
-
为什么需要无状态EJB池
我知道: 对于无状态会话bean,服务器可以在池中维护数量可变的实例。每次客户端请求这样一个无状态bean时(例如通过一个方法),都会选择一个随机实例来服务该请求。 我的问题是:为什么需要游泳池?EJB无状态bean的一个实例不应该足以服务所有请求吗? 另外,如果给定无状态bean的服务器使用的是10个实例的池,那么10是它可以在这样一个bean上处理的最大请求数吗? 你能帮我消除疑虑吗? 编辑:
-
HikariCP连接池-“活动”-如何调试?
此刻我被困住的一点是调试处于“活动”状态的连接,以及它们正在做什么或它们当前被困的原因。 当我运行“10个同时用户”时,它基本上可以转换成2或3倍于此的查询,因此,当我打开HikariCP调试日志时,它会挂在类似的位置-上,而“active”连接并没有真正释放连接,这正是我试图找出的原因,因为查询相当简单,表本身只有4个字段(包括主键)。 HikariCP人员的最佳实践通常也是,增加连接池不是实现
-
自定义连接池速度慢(JAVA)?
对于我的项目,我们被要求实现我们自己的连接池。我们不允许使用来自jdbc的PGPoolingDataSource。当我使用jdbc池时,我的程序运行得非常快,而我自己的连接池运行得不可预测,速度也慢得多。我的连接使一些任务等待了很长时间,这是jdbc池所没有的。 我正在使用Arrayblockingqueue实现连接池,我只是创建一个预先说过的连接数,然后让客户机借用并放回。 我是说这对我来说似乎
-
SonarQube中的连接池配置/错误
我不时在日志中出现以下错误: 查询数据库时出错。原因:组织。阿帕奇。平民dbcp。SQLNestedException:无法获取连接,池错误等待空闲对象超时 该错误可能存在于组织中。声纳。果心问题db。ActionPlanMapper 错误可能涉及组织。声纳。果心问题db。ActionPlanMapper。芬德比克斯 执行查询时发生错误 我应该如何调整我的连接池设置,以便不再发生这种情况?
-
Java恒定池的目的是什么?
我目前正试图深入研究Java虚拟机的规范。我一直在网上阅读JVM书籍,其中有一个令人困惑的抽象我似乎无法理解:常量池。以下是这本书的摘录: 对于加载的每种类型,Java虚拟机都必须存储一个常量池。常量池是类型使用的一组有序常量,包括文本(字符串、整数和浮点常量)以及对类型、字段和方法的符号引用。常量池中的条目由索引引用,很像数组的元素。因为常量池包含对类型使用的所有类型、字段和方法的符号引用,所以
-
如何监视Spring-data-redis池度量?
我想监视spring-data-redis中的池度量。JedisconnectionFactory的游泳池是私人的。我怎么才能拿到?我搜索谷歌,但我找不到很好的方法做到这一点。
-
字符串文字池如何工作
问题内容: 通常,我在互联网上的许多文章中都读到,当我们编写上面的语句时,会创建两个对象。在堆上创建一个String对象,在Literal Pool上创建一个字符串对象。并且堆对象还引用在Literal Pool上创建的对象。(如果我的陈述是错误的,请更正。) 请注意,以上解释是根据我阅读互联网上一些文章后的理解得出的。 所以我的问题是..有什么方法可以停止在文字池中创建字符串对象。怎么做? [请
-
如何在线程池中使用MDC?
问题内容: 在我们的软件中,我们广泛使用MDC来跟踪Web请求的内容,例如会话ID和用户名。在原始线程中运行时,这可以正常工作。但是,有很多事情需要在后台处理。为此,我们使用java.concurrent.ThreadPoolExecutor和java.util.Timer类以及一些自卷式异步执行服务。所有这些服务都管理自己的线程池。 这是Logback手册关于在这样的环境中使用MDC的内容: 映
-
Java中的线程池有什么用?
问题内容: 线程池有什么用?现实世界中有一个很好的例子吗? 问题答案: 线程池是最初创建的一组线程,它们等待作业并执行它们。这个想法是让线程始终存在,这样我们就不必每次都花时间来创建它们。当我们知道有大量工作要处理时,它们是合适的,即使可能有一段时间没有工作。 这是Wikipedia的一个不错的图表:
-
 TensorFlow tf.nn.max_pool实现池化操作方式
TensorFlow tf.nn.max_pool实现池化操作方式本文向大家介绍TensorFlow tf.nn.max_pool实现池化操作方式,包括了TensorFlow tf.nn.max_pool实现池化操作方式的使用技巧和注意事项,需要的朋友参考一下 max pooling是CNN当中的最大值池化操作,其实用法和卷积很类似 有些地方可以从卷积去参考【TensorFlow】 tf.nn.conv2d实现卷积的方式 tf.nn.max_pool(value
-
带有迭代器的多处理池
问题内容: 我想将多处理池与迭代器一起使用,以便在将迭代器拆分为N个元素的线程中执行函数,直到迭代器完成为止。 我的问题是,此脚本是正确的方法吗?有没有更好的办法? 该脚本可能出了点问题,因为我在 问题答案: 如果我不得不猜测代码的主要问题,那是因为将您的代码传递给了流程函数-工作方式是解压缩传递给它的参数,因此您的函数实际上是获取参数,而不是列出一个参数的元素。这会在过程功能甚至没有机会启动之前
-
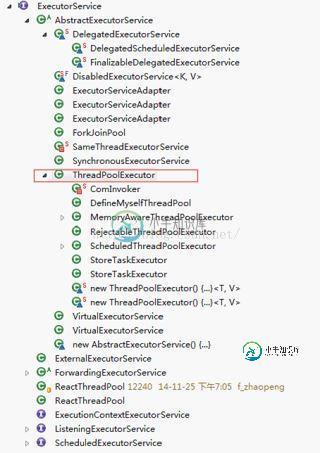 jdk自带线程池实例详解
jdk自带线程池实例详解本文向大家介绍jdk自带线程池实例详解,包括了jdk自带线程池实例详解的使用技巧和注意事项,需要的朋友参考一下 二、简介 多线程技术主要解决处理器单元内多个线程执行的问题,它可以显著减少处理器单元的闲置时间,增加处理器单元的吞吐能力,但频繁的创建线程的开销是很大的,那么如何来减少这部分的开销了,那么就要考虑使用线程池了。线程池就是一个线程的容器,每次只执行额定数量的线程,线程池就是用来管理这些额定
-
Python实现线程池代码分享
本文向大家介绍Python实现线程池代码分享,包括了Python实现线程池代码分享的使用技巧和注意事项,需要的朋友参考一下 原理:建立一个任务队列,然多个线程都从这个任务队列中取出任务然后执行,当然任务队列要加锁,详细请看代码