《泡池子》专题
-
java Fork / Join池,ExecutorService和CountDownLatch
问题内容: 我们在Java中使用了三种不同的多线程技术 -Fork / Join pool,Executor Service和CountDownLatch 叉子/加入池 (http://www.javacodegeeks.com/2011/02/java-forkjoin-parallel- programming.html ) Fork / Join框架旨在使分治算法易于并行化。这种类型的算法非
-
Java整数池。为什么?
问题内容: 我到处都读到过,当您在Java中定义介于-128到127之间的Integer时,它不会创建新对象,而是返回已经创建的对象。 除了让新手程序员比较Integer对象以查看它们是否具有相同的数字外,我看不到这样做的任何意义,但是我认为这很糟糕,因为确保他们认为可以将任何Integer对象与进行比较,并且还在教学在任何编程语言中都不好的做法:将两个“不同”对象的内容与进行比较。 这样做有其他
-
什么是数据库池?
问题内容: 我只是想知道数据库连接池的概念以及如何实现。 问题答案: 数据库 连接 池是一种用于保持数据库连接打开以便其他人可以重用的方法。 通常,打开数据库连接是一项昂贵的操作,尤其是在数据库是远程的情况下。您必须打开网络会话,进行身份验证,检查授权等。池化使连接保持活动状态,以便在以后请求连接时,优先使用活动的连接之一,而不必创建另一个连接。 请参阅下图,了解以下几段: 以最简单的形式,它只是
-
JDBC / Connectorj:了解连接池
问题内容: 我想我需要更好地了解连接池的概念。我正在使用Java与ConnectorJ一起工作,并将servlet部署在Apache Tomcat服务器上。我一直在关注该文档,因此我的Tomcat context.xml如下所示: 我使用推荐的方式从数据源获得连接: 我的问题是:为什么我必须在context.xml中为我的数据源指定用户和密码。如果我错了,请纠正我,但我认为连接池的重点是重用拥有相
-
Goroutines阻止了连接池
问题内容: 查询1打开15个连接,执行后将关闭它们。但是将永远不会执行,因为它包含等待自由连接的内容。 如何解决这个问题呢? 问题答案: 你有一个僵局。在最坏的情况下,您有15个goroutine持有15个数据库连接,而所有这15个goroutine都需要一个新的连接才能继续。但是要获得新的连接,就必须前进并释放一个连接:死锁。 链接的维基百科文章详细介绍了防止死锁的方法。例如,代码执行仅在拥有需
-
Spring池与MySQL的连接
我有(假设)以下服务器为我的应用程序;我的工作与MySQL。 1) 应用程序使用的数据库(服务器位于日本) 2)数据库备份(服务器位于秘鲁) 3)紧急数据库(服务器位于美国) 关于Spring的功能,我有几个问题: A) 如何在所有数据源中同时持久化? 如何在Spring中创建连接池,以便如果我的第一个数据源没有响应,系统会自动与第二个数据源一起工作? 这是我实际的 问候
-
Spring Boot连接池理解
在Spring boot application.properties文件中,我们有以下选项: 这是我的存储库类 这是服务类 问题是,userRepository如何创建到DB的连接,以及它是否会使用我的应用程序属性文件中的连接池。我来自JDBC和hibernate,在那里我使用DataManager、DataSource、Connection类来使用连接池,但是在spring boot中,我没有
-
光连接池已耗尽
我有使用hikari池创建连接池的Spring启动应用程序。我们正在使用postgres sql用于db。当我以低qps命中系统时,请求需要大约200毫秒来执行。当部署一个pod并且qps为15时,事情保持良好状态。但是一旦我将qps增加到20,请求就开始需要大约10秒来处理,连接池变空(java.sql.SQLTransientConntion异常:菲尼克斯-连接不可用,请求在30183毫秒后超
-
Kafka客户端连接池
执行kafka客户端的生产者/消费者连接池有意义吗? kafka是否在内部维护已初始化并准备好使用的连接对象列表? 我们希望最小化连接创建的时间,这样在发送/接收消息时就不会有额外的开销。 目前,我们正在使用apache共享池库来保持连接。 任何帮助都将不胜感激。
-
Python多处理池超时
问题内容: 我想使用multiprocessing.Pool,但是multiprocessing.Pool不能在超时后中止任务。我找到了解决方案,并对其进行了一些修改。 主要修改-使用 sys.exit(1) 退出工作进程。它杀死了工作进程并杀死了工作线程,但是我不确定这个解决方案是否很好。当进程因正在运行的作业而终止时,我会遇到哪些潜在的问题? 问题答案: 停止正在运行的作业没有隐含的风险,操作
-
JDBC连接池管理器
我们正在用Java重写来自PHP的web应用程序。我认为,但我不是很确定,我们可能会在连接池方面遇到问题。应用程序本身是多租户的,是“独立数据库”和“独立模式”的组合。 对于每个Postgres数据库服务器实例,可以有一个以上的数据库(命名为schemax_XXX),其中包含一个以上的模式(模式是租户)。注册时,可能会发生以下两种情况之一: 在编号最高的schema_XXX数据库中创建新的租户模式
-
Android M startActivity电池优化
-
 如何创建线程池 ?
如何创建线程池 ?本文向大家介绍如何创建线程池 ?相关面试题,主要包含被问及如何创建线程池 ?时的应答技巧和注意事项,需要的朋友参考一下 在《阿里巴巴 Java 开发手册》“并发处理”这一章节,明确指出线程资源必须通过线程池提供,不允许在应用中自行显示创建线程。 为什么呢? 使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源开销,解决资源不足的问题。如果不使用线程池,有可能会造成系统创建大量同类线程而
-
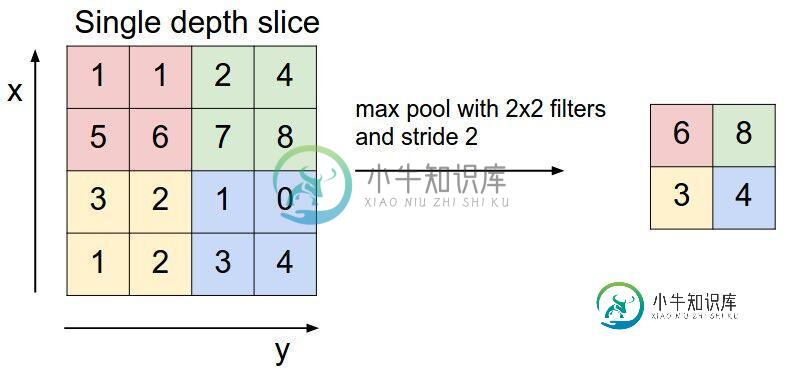 什么是CNN的池化
什么是CNN的池化本文向大家介绍什么是CNN的池化相关面试题,主要包含被问及什么是CNN的池化时的应答技巧和注意事项,需要的朋友参考一下 池化,简言之,即取区域平均或最大,如下图所示(图引自cs231n) 上图所展示的是取区域最大,即上图左边部分中 左上角2x2的矩阵中6最大,右上角2x2的矩阵中8最大,左下角2x2的矩阵中3最大,右下角2x2的矩阵中4最大,所以得到上图右边部分的结果:6 8 3 4。
-
在dbcp中使用PreparedStatement池
问题内容: 有人可以解释如何使用完全准备好的使用dbcp的连接池吗?(如果可能,请提供一些示例代码)。我已经弄清楚了如何打开它- 将KeyedObjectPoolFactory传递给PoolableConnectionFactory。但是,那之后如何定义特定的准备好的语句呢?现在,我仅使用PoolingDataSource从池中获取连接。如何使用池中准备好的语句? 问题答案: 在谈论从池中获得连接