《满帮集团》专题
-
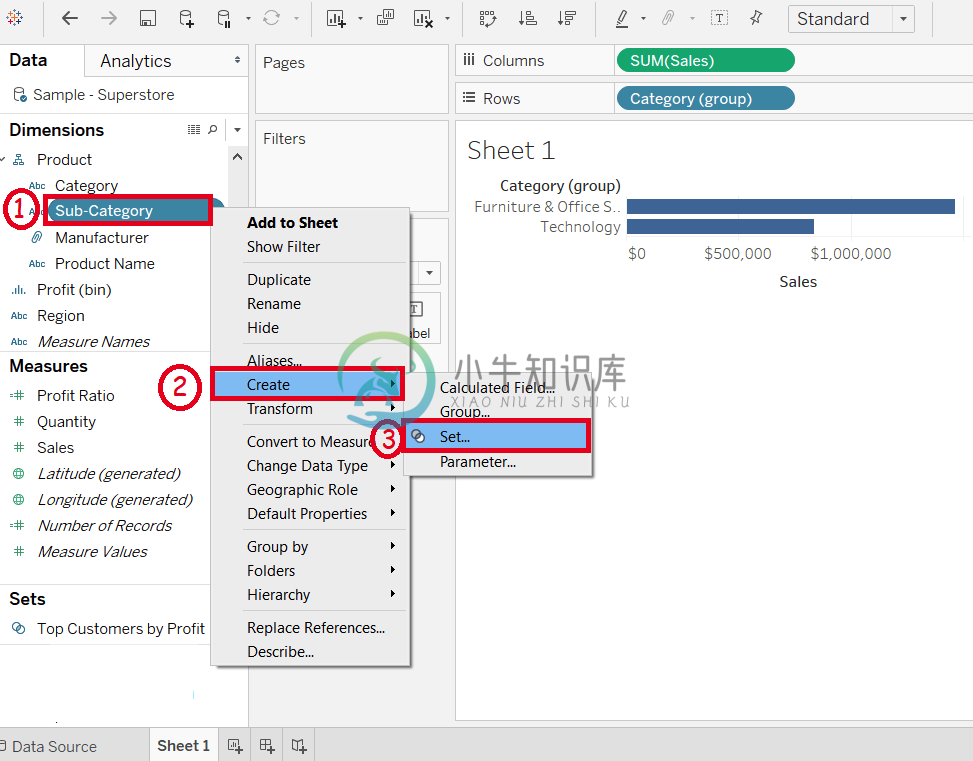 Tableau构建集合
Tableau构建集合集合是自定义字段,它根据某些条件定义数据子集合。集合在数据集中存在的字段外创建一组成员。 它充当单独的字段或维度,构建集的过程如下逐步给出。 例如,考虑Sample-Superstore等数据源,并使用其维度和度量来构建集合。 第1步:转到工作表。然后, 右键单击维度子类别。 选择“创建(Create)”选项。 然后单击下图中显示的“集合(Set)”选项。 第2步:打开“创建集(Create Se
-
OrientDB删除集群
命令用于删除集群及其所有相关内容。 这个操作是永久的并且回滚。 以下语句是命令的基本语法。 其中定义要移除的群集的名称,定义要移除的群集的ID。 示例 尝试使用以下命令删除群集。 如果上述查询成功执行,您将得到以下输出。
-
OrientDB截断集群
截断群集(命令)删除群集的所有记录。 以下语句是命令的基本语法。 其中是集群的名称。 示例 尝试以下查询以截断名的集群。 如果上述查询成功执行,您将得到以下输出。
-
OrientDB修改集群
更改集群(命令)是更新现有集群上的属性。 在本章中,将学习如何添加或修改集群的属性。 以下语句是命令的基本语法。 以下是有关上述语法中选项的详细信息。 - 定义集群名称。 - 定义您想要更改的属性。 - 定义您要为此属性设置的值。 以下表中提供了可与命令一起使用的属性列表。 名称 类型 描述 NAME 字符串 更改群集名称。 STATUS 字符串 更改群集状态。允许的值是和。 默认情况下,群集在线
-
OrientDB创建集群
OrientDB中的集群是一个重要的概念,用于存储记录,文档或顶点。 简而言之,群集是存储一组记录的地方。 默认情况下,OrientDB将为每个类创建一个群集。 一个类的所有记录都存储在同一个簇中,它与该类名称相同。最多可以在数据库中创建个群集。 是用于创建具有特定名称的集群的命令。 创建群集后,可以使用群集通过在创建任何数据模型期间指定名称来保存记录。 如果要将新群集添加到类中,请使用命令和命令
-
 Apache Ant IDE集成
Apache Ant IDE集成IDE(集成开发环境)是一个设计和开发软件应用程序的平台。 有各种现代Java IDE,它们很受欢迎并且被广泛使用。 常用的一些如下面列出。 JDEE(Emacs的Java开发环境) IDEA NetBeans jEdit Eclipse Virtual Ant 以上所有IDE都支持Apache Ant,并提供编写构建文件的便利环境。 在这里,将演示如何在Eclipse IDE中使用Ant。 Ec
-
Java 集合排序
主要内容:1 集合元素的排序,2 Collections sort方法,3 字符串正序排序,4 字符串倒序排序,5 包装类型排序,6 自定义对象排序1 集合元素的排序 我们可以对以下元素进行排序: 字符串对象 包装类对象 用户自定义对象 Collections类提供用于对集合的元素进行排序的静态方法。如果集合元素为Set类型,则可以使用TreeSet。但是,我们无法对List的元素进行排序。Collections类提供用于对List类型元素的元素进行排序的方法。 2 Collections so
-
 Struts2和Hibernate集成
Struts2和Hibernate集成主要内容:数据库设置:,Hibernate的配置:,环境设置:,Hibernate 类:,动作类:,创建视图文件:,Struts 配置:Hibernate是一个高性能的对象/关系持久性和查询服务许可下的开源GNU通用公共许可证(LGPL),并免费下载。在这一章中,我们要学习如何实现Struts2与Hibernate集成。如果你不熟悉与Hibernate,那么可以查看我们的Hibernate教程。 数据库设置: 在本教程中,我会使用“struts2_tutorial”MySQL数据库。我连接到我的
-
 Struts2和Tiles集成
Struts2和Tiles集成在本章中,让我们通过Struts2的集成Tiles框架所涉及的步骤。 Apache的Tiles是一个内置的模板框架来简化Web应用程序用户界面的开发。 首先,我们需要从Apache Tiles 网站下载的files jar文件。需要添加下面的jar文件添加到项目的类路径。 tiles-api-x.y.z.jar tiles-compat-x.y.z.jar tiles-core-x.y.z.jar
-
 Struts2和Spring集成
Struts2和Spring集成Spring是一个流行的Web框架,它提供易于集成与很多常见的网络任务。所以,问题是,为什么我们需要Spring,当我们有Struts2?Spring是超过一个MVC框架 - 它提供了许多其它好用的东西,这是不是在Struts。例如:依赖注入可以是有用的任何框架。在本章中,我们将通过一个简单的例子来看看如何集成Spring和Struts2一起。 首先,需要添加下列文件到项目的构建路径从Spring
-
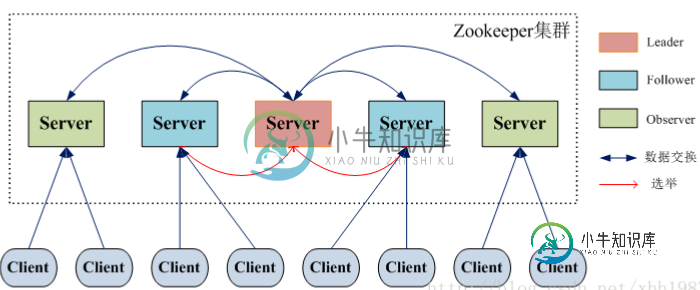 ZooKeeper 集群角色 ?
ZooKeeper 集群角色 ?本文向大家介绍ZooKeeper 集群角色 ?相关面试题,主要包含被问及ZooKeeper 集群角色 ?时的应答技巧和注意事项,需要的朋友参考一下 但是,在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了 Leader、Follower 和 Observer 三种角色。如下图所示 ZooKeeper 集群中的所有机器通过一个 Leader 选举过程 来选定一台称为
-
Storm 集成 HDFS/HBase
一、Storm集成HDFS 1.1 项目结构 本用例源码下载地址:storm-hdfs-integration 1.2 项目主要依赖 项目主要依赖如下,有两个地方需要注意: 这里由于我服务器上安装的是 CDH 版本的 Hadoop,在导入依赖时引入的也是 CDH 版本的依赖,需要使用 <repository> 标签指定 CDH 的仓库地址; hadoop-common、hadoop-client、
-
1.19 集成学习
现在要讲的方法可以来整合训练模型的输出。这里要用到偏差-方差(Bias-Variance)分析,以及决策树的样本来探讨一下每一种方法所做的妥协权衡。 要理解为什么从继承方法推导收益函数(benefit),首先会议一些基本的概率论内容。加入我们有n个独立同分布(independent, identically distributed,缩写为i.i.d.) 的随机变量$X_i$,其中的$0\le i<
-
BIOS 资源集锦
全球主要 BIOS 生产公司网站 Award BIOS 公司 (美国) Award BIOS 公司 (台湾) Award 技术咨询中心 (只限email) AMI BIOS 公司 Microid Research Micro Firmware , 开发并发行Phoenix BIOS及升级BIOS数据文件 Phoenix BIOS 公司 Unicore :提供BIOS升级数据文件 (只限Award
-
4. 持续集成
虽然以下示例中使用在Travis CI,但原则上应该,也可以直接转移到其他持续集成提供商. 以下是Travis CI的.travis.yml示例,确保配置了mdbook build和mdbook test运行成功。加快CI运转时间的关键是缓存mdbook的安装,以便您可以不用每次CI运行就编译一次mdbook。 language: rust sudo: false cache: - carg