《满帮集团》专题
-
通过字段“springSecurityFilterChain”表示的未满足的依赖关系
正在尝试测试我的。。。编译器请求注入,但在为创建bean后,它返回通过字段 代码: 错误:
-
Azure cloudblockblobs存储对该大小下的文件使用满4MB?
谢谢
-
 度小满商业/经营分析师(信贷方向)面经
度小满商业/经营分析师(信贷方向)面经笔试 8.31 选择题考了一些逻辑推断和概率论,两道问答印象比较深刻,一个是用户画像,一个是如何确定样本量。 一面 9.18 本来约好2点45开始,2点18收到HR电话问可不可以提前开始,面试官已经在等着了,于是我兵荒马乱就进会议室了,都没来得及准备录音和调试设备。面试也比我想象中要短很多,就自我介绍,然后问了上一段实习的主要工作和产出,介绍上上一段实习的工作,然后对比两份工作,问我更喜欢哪一个,
-
 度小满运营数据分析师一面大约凉经
度小满运营数据分析师一面大约凉经基本不问简历,偏业务和基础知识 1.认为数据分析在行业中的作用 2.sort by和order by的差别 3.采用调研的方式效率低、成本高,怎么从数据角度分析 用户画像哪些维度(结合信贷业务) 4.对abtest有什么了解 5.为什么会产生过拟合的情况如何解决 #度小满##面试##数分#
-
2.9 随机图形属性:绘制开满鲜花的原野
本节,我们通过绘制色彩缤纷的鲜花,来拥抱我们内心的嬉皮士。 图2-10 绘制开满鲜花的原野 绘制步骤 按照以下步骤,绘制随机的鲜花遍布整个画布: 1. 定义Flower对象的构造函数: //定义Flower对象的构造函数 function Flower(context, centerX, centerY, radius, numPetals, color){ this.context =
-
 度小满一面:自然语言处理(对话生成)凉
度小满一面:自然语言处理(对话生成)凉1.主要问的是项目(大模型相关的) 2.然后问了写基础知识,chatglm架构,3.Tokenizer的分词方法 4.llama介绍一下 5.在transformer中哪个部分最占显存 6.分析一下空间复杂度 7.在模型训练过程中,会有那些东西存储在显存中 8.lora微调 9.手撕牛客hard,最大升序子序列(三)
-
 大数据面试题—包含真实面经(压力拉满)
大数据面试题—包含真实面经(压力拉满)从事数据开发,手写面试题5W字,涉及hadoop、zookeeper、kafka、spark、flink、clickhouse等常见的大数据中间件,文档可以后台踢我 1、Hadoop特点 hadoop是一个分布式计算平台,能够允许使用编程模型在集群上对大型数据集进行分布式处理 hadoop的三大组件:HDFS(分布式文件存储平台)、MR(计算引擎)、YARN(资源调度平台) 特点: 高扩容:had
-
 大数据面试题—包含真实面经(压力拉满)
大数据面试题—包含真实面经(压力拉满)从事数据开发,手写面试题5W字,涉及hadoop、zookeeper、kafka、spark、flink、clickhouse等常见的大数据中间件,文档可以后台踢我 1、Hadoop特点hadoop是一个分布式计算平台,能够允许使用编程模型在集群上对大型数据集进行分布式处理hadoop的三大组件:HDFS(分布式文件存储平台)、MR(计算引擎)、YARN(资源调度平台)特点:高扩容:hadoop在
-
Java中的列表vs队列vs集合集
问题内容: 列表,队列和集合之间有什么区别? 问题答案: 简单来说: 一个 列表 是一个对象,在同一个对象可能出现不止一次的有序列表。例如:[1,7,1,3,1,1,1,5]。谈论列表中的“第三要素”是有意义的。您可以在列表中的任何位置添加元素,在列表中的任何位置更改元素,或从列表中的任何位置删除元素。 一个 队列 也定购,但你永远只触摸元件的一端。所有元素都在队列的“结尾”处插入,并从队列的“开
-
Java垃圾收集器-什么时候收集?
问题内容: 是什么决定了垃圾收集器何时真正收集?它是在一定时间之后还是在一定数量的内存用完之后发生的吗?还是还有其他因素? 问题答案: 它在确定是时候运行时运行。在世代垃圾收集器中,一种常见的策略是在第0代内存分配失败时运行收集器。也就是说,每次你分配一小块内存(大块通常直接放置在“旧”代中)时,系统都会检查gen-0堆中是否有足够的可用空间,如果没有,则运行GC释放空间以使分配成功。然后将旧数据
-
在Apache上集成PHP,在Tomcat上集成Java
1)我正在使用 2)这两种语言不需要集成Tomcat就可以在Apache服务器上运行。 3)但是,为了增强网站的逻辑性,我们使用Java作为另一种后端编程语言。 4)目前,该Java需要与网站的JSP和PHP页面进行集成。 5)因此,在一个JSP文件中,一部分代码可以是Java的,一部分代码可以是PHP的。 6)理想情况下,如果部分PHP代码运行在Apache服务器上,Java代码运行在Tomca
-
使用共享Zookeeper集合创建Solr集合
我建立了一个具有两个节点和外部Zookeper集合的SOLR集群。该ZK集合有3个节点。我使用参数启动solr实例: 这意味着,我希望SOLR配置在/solr5下,而不是默认情况下的/下。 文件夹 /solr5在ZK中创建: 我还可以毫无问题地将SOLR配置上传到/solr5中。 我的问题是,在创建集合时,如何将生成的文件置于/solr5之下? 我用来创建集合的命令是: 我查看了本页上的文档,但没
-
Docker1.12 Worker无法加入集群(集群:待定)
问题内容: 管理员版本, 工人版本。 创建了Swarm管理器: 然后创建工人 我已经检查了工人的日志 在中,我看到了“虫群:待定” 我也做到了!尽管如此,该工作人员仍无法加入集群。所以,我该怎么爱 更新1 卸载并删除配置文件,然后再次安装docker 1.12版本。 仍然面临着相同的问题(无法加入和中的“ Swarm:Pending” ),其中存在DIFFERENT错误 谢谢。 问题答案: 问题是
-
Spring Boot 2集成Brave MySQL-集成到Zipkin中
我正在尝试将Brave MySql检测集成到Spring Boot2.x服务中,以自动地让它的拦截器通过涉及MySql查询的范围来丰富我的跟踪。 当前的Gradle-依赖关系如下 你有什么建议给我如何正确地连接东西吗?
-
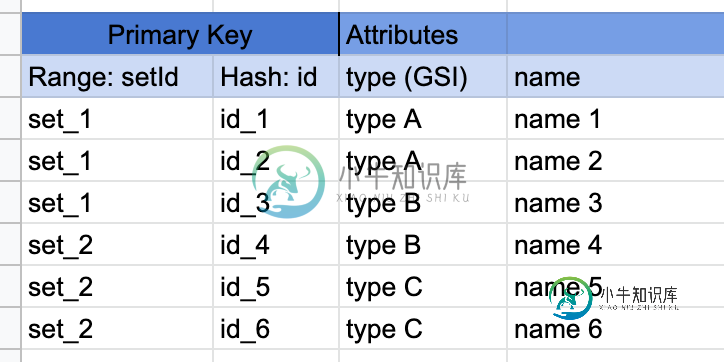 (DynamoDB集合)集合查询是否需要sortKey?
(DynamoDB集合)集合查询是否需要sortKey?我正在制作一些lambda来从dynamoDB表中获取数据。 DynamoDB表具有 复合主键 'setId'作为分区键(范围键)(我用这个词'set'作为名词,就像'group'一样) 'id'作为排序键(散列键) 如果我理解正确, 我可以使用setId来查询,因为DynamoDb通过分区键进行集合。 所以我尝试了这个参数。 但它返回错误 Q. 获取集合是否需要排序键? 提前谢谢! 仅供参考)我