《亿道集团》专题
-
写一个程序从10亿个数组中找出100个最大的数
我只能给出一个强力解决方案,即以O(nlogn)时间复杂度对数组进行排序,并取最后100个数字。 面试官在寻找一个更好的时间复杂性,我尝试了几个其他的解决方案,但都没能回答他。有更好的时间复杂性解决方案吗?
-
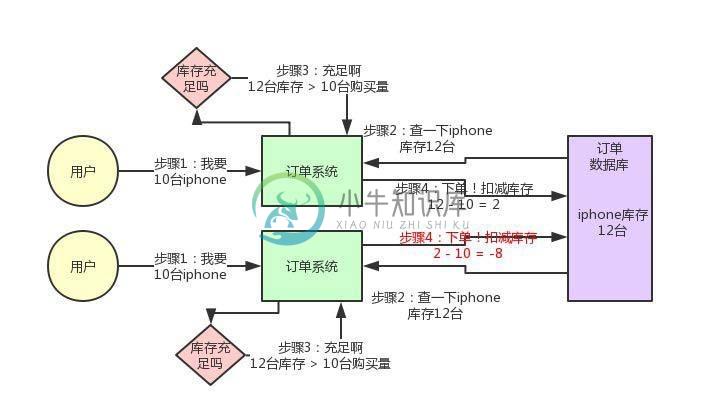 一文带你了解亿级流量下的分布式锁优化方案!
一文带你了解亿级流量下的分布式锁优化方案!主要内容:背景引入,库存超卖现象是怎么产生的?,用分布式锁如何解决库存超卖问题?,如何对分布式锁进行高并发优化?今天给大家聊一个有意思的话题:每秒上千订单场景下,如何对分布式锁的并发能力进行优化? 背景引入 首先,我们一起来看看这个问题的背景? 前段时间有个朋友在外面面试,然后有一天找我聊说:有一个国内不错的电商公司,面试官给他出了一个场景题: 假如下单时,用分布式锁来防止库存超卖,但是是每秒上千订单的高并发场景,如何对分布式锁进行高并发优化来应对这个场景? 他说他当时没答上来,因为没做过没什么
-
性能优化 - 前端如何绘制能容纳亿级别的折线图?
前端如何绘制能容纳亿级别的折线图? 项目需要绘制一个折线图,这个折线图要容纳亿级数据量,并且是实时更新的,就是这个统计图一直在绘画,每秒都在更新,然后并且能支持查看很久之前的统计图,比如说我点到之前的某个点,这个点就会放大,以前的数据不删除。 已经使用的方式是highcharts,引入, 实时更新是使用 数据是批量过来的,通过websocked, highcharts好像没有addPoints这种
-
采集帮助 - 了解采集 - 采集流程
采集流程: 采集一般可以分为3个过程:1.设置采集规则;2.采集数据内容;3.导出内容,这3个内容是可以独立分开来的。 设置采集规则:这个就是在操作中的添加采集节点,并对这个节点规则进行设置,比如:设置采集内容列表的地址、指定采集标题或者内容的位置(规则)、设置采集内容过滤规则。这个规则是采集最根本最基础的东西,采集规则可以导入导出,方便对这个采集规则进行分享。 采集数据内容:根据不同情况对数据采
-
采集帮助 - 了解采集 - 关于采集
关于采集: 什么是采集呢?我们可以这样理解,我们打开一个网站,看到有一篇文章很不错,于是将文章的标题和内容复制,然后将这篇文章转到我们的网站上,这个过程就可以称作采集,将别人网站上对自己有用的信息转到自己网站上。 采集器也是这样,不过整个过程是由电脑来完成的,我们复制人家的标题和内容,是在知道什么地方是内容,什么地方是标题前提下进行操作的,但电脑是不知道的,所以我们要告诉电脑怎么识别怎么采,这就是
-
空结果集的集合
问题内容: 我希望将空结果集的总计设置为0。我尝试了以下方法: 结果: 子问题:上面的工作在Oracle中行不通吗? 问题答案: 在有关聚合函数的文档页面中: 应该注意的是,除了这些函数, 当没有选择任何行时 ,这些函数将 返回空值 。特别是,没有行返回空值,而不是预期的零值。必要时,该函数可用于将零替换为null。 所以,如果你想保证返回的值,适用于 结果 的,而不是它的参数: 至于Oracle
-
列表子集的子集
在R中,我有一个列表,由12个子列表组成,每个子列表本身由5个子发布者组成,如下所示 列表和子列表 在本例中,我想为每个子列表提取信息“MSD”。 我可以提取每种使用方法的级别“统计信息” 这很有效。它给了我子列表“statistics”中包含的所有值,但是,对于每个列表,我想向下一级,因为我对其他数据(如MSerror、Df等)不感兴趣。。。。。只有MSD 我试过了 还有许多人没有成功。 如果我
-
ignite集群与kubernetes集成
我是新点燃的。 步骤1:我在两个VM(ubuntu)中安装了Ignite 2.6.0,在一个VM中启动了节点。下面有COMAND。bin/ignite.sh examples/config/example-ignite.xml 步骤2:我的所有配置都在example-default.xml中 步骤3:在其他VM中执行包含datagrid逻辑的client.jar(该VM既是客户机也是节点)。 步骤
-
从集群收集度量
有人能建议从节点集群收集指标的最佳模式吗(每个节点都是带有Java应用程序的Tomcat Docker容器)? 我们计划使用ELK堆栈(ElasticSearch、Logstash、Kibana)作为可视化工具,但我们的问题是如何将指标交付给Kibana? 我们使用DropWizard度量库,它提供每个实例的度量(量表、计时器、直方图)。 显然,应该收集每个实例的一些指标(例如,cpu、内存等..
-
1.8.3 集群&集群发现
Cluster Cluster.EdsClusterConfig Cluster.OutlierDetection Cluster.LbSubsetConfig Cluster.LbSubsetConfig.LbSubsetSelector Cluster.LbSubsetConfig.LbSubsetFallbackPolicy (Enum) Cluster.RingHashLbConfig C
-
JS实现的集合去重,交集,并集,差集功能示例
本文向大家介绍JS实现的集合去重,交集,并集,差集功能示例,包括了JS实现的集合去重,交集,并集,差集功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS实现的集合去重,交集,并集,差集功能。分享给大家供大家参考,具体如下: 1. js 实现数组的集合运算 为了方便测试我们这里使用nodejs,代码如set_operation.js 2. 测试 我们这里使用nodejs来测试 测试
-
 东软集团 C++
东软集团 C++1、面向对象三大特性 2、static的用法和作用 3、介绍下引用 4、常用的STL容器(vector、list、map) 5、分别都介绍一下 6、了解socket吗?socket中三次握手的建立 7、进程通信 8、共享内存函数有什么?(这个忘了...) 9、死锁产生的条件 10、堆和栈都存储的什么 11、I/O多路复用介绍一下 12、设计模式了解哪些 13、C++11新标准知道哪些?Lambda
-
 联影集团(offer)
联影集团(offer)8月19号投递,21号测评,8月31号运维部门面试,9月1号开发部门面试(好像简历被两个部门都查看,导致被两个部门进行了约面),9月19号hr面试 不知道为什么联影和其他公司有个不同的点,联影是部门leader直接约面,而不是经由hr约面 一、运维部门:8月31号 1、自我介绍 2、聊了之前实习的工作,聊了下docker和k8s 3、聊了自己的研究方向 4、问了自己获得的奖项,在校成绩,在校比赛,
-
IIS7.5 检测到在集成的托管管道模式下不适用的 ASP.NET设置
本文向大家介绍IIS7.5 检测到在集成的托管管道模式下不适用的 ASP.NET设置,包括了IIS7.5 检测到在集成的托管管道模式下不适用的 ASP.NET设置的使用技巧和注意事项,需要的朋友参考一下 在调试一个网上下载的.net网站时,打开就提示出错: 错误摘要 HTTP 错误 500.22 - Internal Server Error 检测到在集成的托管管道模式下不适用的 ASP.NET
-
跨越文件入站适配器和队列通道的Spring集成事务策略
我有一个由入站文件适配器读取的目录,该适配器被管道输送到优先级通道,该通道按文件名称对文件进行排序。我创建了一个事务同步工厂,用于在处理完成后移动文件,它对入站适配器和其他文件编写器流中发生的所有转换/聚合都很好。一旦我添加了PriorityChannel,事务似乎就完成了,它没有被传递给转换/聚合逻辑。 根据Gary的说法,这应该是可行的(按照要求提供整个示例): 通过这样做并移除Priorit