《美的群面》专题
-
电报群为什么自动变成超级群?
这些消息将自动触发。所以如果聊天id自动改变,那对我来说是个问题。 我有几个问题想了解原因。 为什么电报组变成超群组? 电报中聊天的聊天id可以改变多少种方式? 电报频道的聊天id可以更改吗?(如果没有,我将停止使用组。我将使用通道)
-
消费者“群_name”群永远在重新平衡
我用的是Kafka:2.11-1.0.1。应用程序包含主题“X”的并发性为5的使用者,分区为5。 重新启动应用程序并在分区分配之前在主题“X”上发布消息时,主题“X”的5个使用者会找到组协调器,并将加入组请求发送给组协调器。预计会收到小组协调员的回复,但未收到回复。 我检查了Kafka服务器日志,但在调试日志级别找不到相关日志。 当我运行描述消费者组的命令时,作出如下观察: 消费群体正在重新平衡
-
Swift中的自定义类集群
问题内容: 它允许您从调用中返回子类。 我正在尝试找出使用Swift实现相同功能的最佳方法。 我确实知道,很可能有一种更好的方法可以用Swift实现相同的目的。但是,我的类将由我无法控制的现有Obj- C库初始化。因此,它确实需要以这种方式工作并且可以从Obj-C调用。 任何指针将不胜感激。 问题答案: 我不相信Swift可以直接支持这种模式,因为初始化程序不会像在Objective C中那样返回
-
限制Hazelcast群集中的成员
我正在进行一个Spring启动项目,我使用Hazelcast作为缓存。我启用了tcp作为连接方法,我还提到了一些成员。会员可以加入。但问题是其他节点也可以加入除了成员。有人能告诉我如何限制它吗? 这是我的配置,
-
 Redis集群与Spring boot的集成
Redis集群与Spring boot的集成我有一个redis集群,有主服务器、从服务器和3个哨兵服务器。主从映射到dns名称node1-redis-dev.com、node2-redis-dev.com。redis服务器版本为2.8 我在application.properties文件中包含以下内容。 但是,当我检查StringRedisTemplate时,在JedisConnectionFactory的hostName属性下,我看到的是
-
获取Kafka connect集群的信息
我目前使用的是Kafka connect集群,它有两个节点,使用的是同一个 当使用curl/connectors时,我可以获得创建的连接器列表,但我看不到有关活动节点的信息,健康检查。。。
-
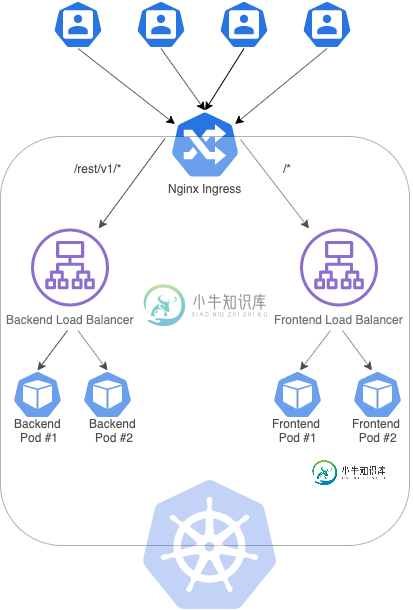 Kubernetes群集上的粘性会话
Kubernetes群集上的粘性会话目前,我正在尝试在Google云上创建一个Kubernetes集群,其中包含两个负载平衡器:一个用于后端(在Spring boot中),另一个用于前端(在Angular中),其中每个服务(负载平衡器)与两个副本(POD)通信。为了实现这一点,我创建了以下入口: 上面提到的入口可以使前端应用程序与后端应用程序提供的REST API进行通信。但是,我必须创建粘性会话,以便每个用户都与同一个POD进行通
-
在Heroku上的Puma集群配置
在RoR4 Heroku应用程序上配置Puma(多线程多核服务器)时,我需要一些帮助。那上面的Heroku文档不是最新的。我遵循了这一条:配置的并发性和数据库连接,其中没有提到集群的配置,因此我必须同时使用这两种类型(线程和多核)。 我目前的配置: /程序文件 ./config/puma.rb 问题: a) 我是否需要像Unicorn中那样的before\u fork/after\u fork配置
-
集群ActiveMQ中的负载平衡
假设我在一个集群中有3个ActiveMQ Artemis代理: 经纪人_01 在给定的时间点,我有每个经纪人的消费者数量: 经纪人有50名消费者 让我们假设在这个给定的时间点,有70条消息要发送到集群中的一个队列。 我们期望集群完成负载平衡,以便Broker_01将接收50条消息,Broker_0210条消息,Broker_0310条消息,但目前我们正在经历70条消息通过所有3个代理随机分发。 是
-
关于Ignite中的群集配置
现在我在复制的缓存上使用SQL select语句。现在这些缓存的写入同步模式是FULL_SYNC。 现在,我们只能在一个DC中工作客户端节点,而不能同时在两个DC中工作。假设我们有两个客户在DC1。 因此,节点总数为6个(在DC1中有2个客户端节点和2个服务器节点,在DC2中有2个服务器节点)。 我们的用例是这样一种方式… 2个客户端应该只查询DC1中的2个服务器节点,而不是DC2中的其他2个服务
-
Java.lang.OutOfMemoryError:ignite集群上的Java堆空间
我们正在将web应用程序从内存缓存中的临时解决方案迁移到apache ignite集群,其中运行webapp的jboss作为客户端节点工作,两个外部vm作为ignite服务器节点工作。 当用一个客户机节点和一个服务器节点测试性能时,一切正常。但在集群中使用一个客户端节点和两个服务器节点进行测试时,服务器节点会出现OutOfMemoryError崩溃。
-
两个kubernetes集群之间的mTLS
我试图在两个 kubernetes 集群中的两个应用程序之间获取 mTLS,而没有 Istio 的方式(使用其入口网关),我想知道以下内容是否有效(对于 Istio,对于 Likerd,对于 Consul...)。 假设我们有一个带有应用程序A. A的k8s集群A和一个带有应用程序B. B的集群B。我希望它们与mTLS通信。 集群A为nginx入口控制器提供了letsEncrypt证书,并为其应用
-
启动hadoop集群时的密码
每当我启动Hadoop集群时,系统都会询问密码。 我已经在.ssh文件夹中添加了密钥。 开始-dfs.sh 19/01/22 20:38:56警告util.nativeCodeLoader:无法为您的平台加载本机Hadoop库...使用内置Java类(如果适用)在[localhost]xxxx@localhost's password上启动namenode:localhost:启动namenode
-
Hazelcast中的自定义集群组?
对于我的暑期实习项目,我正在尝试在多个节点上分配作业。但是,我想根据谓词(cpu使用情况)以编程方式创建自定义集群组,就像在Apache Ignite中一样。我的公司已经使用Hazelcast IMDG。Hazelcast是否提供类似的功能?我知道我可以根据组名称创建不同的Hazelcast实例,但有没有办法使用cpu指标在Hazelcast中创建自定义集群组?
-
Spring安全中的多重蚁群
代码似乎工作正常,除了管理部分-它不工作,但返回访问被拒绝异常。