《龙湖集团数字科技》专题
-
将字母字符串转换为数字
所以我是计算机科学的新手,我们被要求做的一件事是尝试创建一个程序,首先将用户输入的一个单词转换成一个数字串,a=1,b=2,z=26等等,还有一些其他的事情,因为它们是扩展,我现在不想讨论。诚然,她说她不介意我们完成它,因为这是我们今天的第一节java课程。 有鉴于此,有人能给我一些关于如何做到这一点的建议吗?我不想让一段完整的代码完全做到这一点,因为我需要学习,因此非常感谢指导之手。到目前为止,
-
Spring数据R2DBC与Redshift数据库的集成
我正在尝试迁移到Spring Data R2DBC,我找不到对Amazon Redshift数据库的支持,如果有支持,有人可以帮助我吗? 下面是spring文档url,它支持的数据库很少,但红移不在列表中。https://spring.io/projects/spring-data-r2dbc
-
Jena、RDF、数据多维数据集词汇表
-
对数正态分布中的聚集参数
我想知道是否有可能从一个对数正态分布中得到一个聚合参数。在生态学中,通常使用负二项式中的聚集参数k,该参数度量数据中聚类或聚集或异质性的数量:越小的k意味着更多的异质性。负二项分布的方差为μ+μ2/k,当k变大时,方差接近均值,分布接近泊松分布。在R中,聚合参数称为size参数(Bolker,2008)。 当我在fitdistr中拟合我的数据时,我的数据比负二项式、gamma和Poisson更符合
-
 易语言文本型和字节集型数据相互转换的工具
易语言文本型和字节集型数据相互转换的工具本文向大家介绍易语言文本型和字节集型数据相互转换的工具,包括了易语言文本型和字节集型数据相互转换的工具的使用技巧和注意事项,需要的朋友参考一下 文本和字节集数据互相转换的代码 运行结果: 总结 以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对呐喊教程的支持。如果你想了解更多相关内容请查看下面相关链接
-
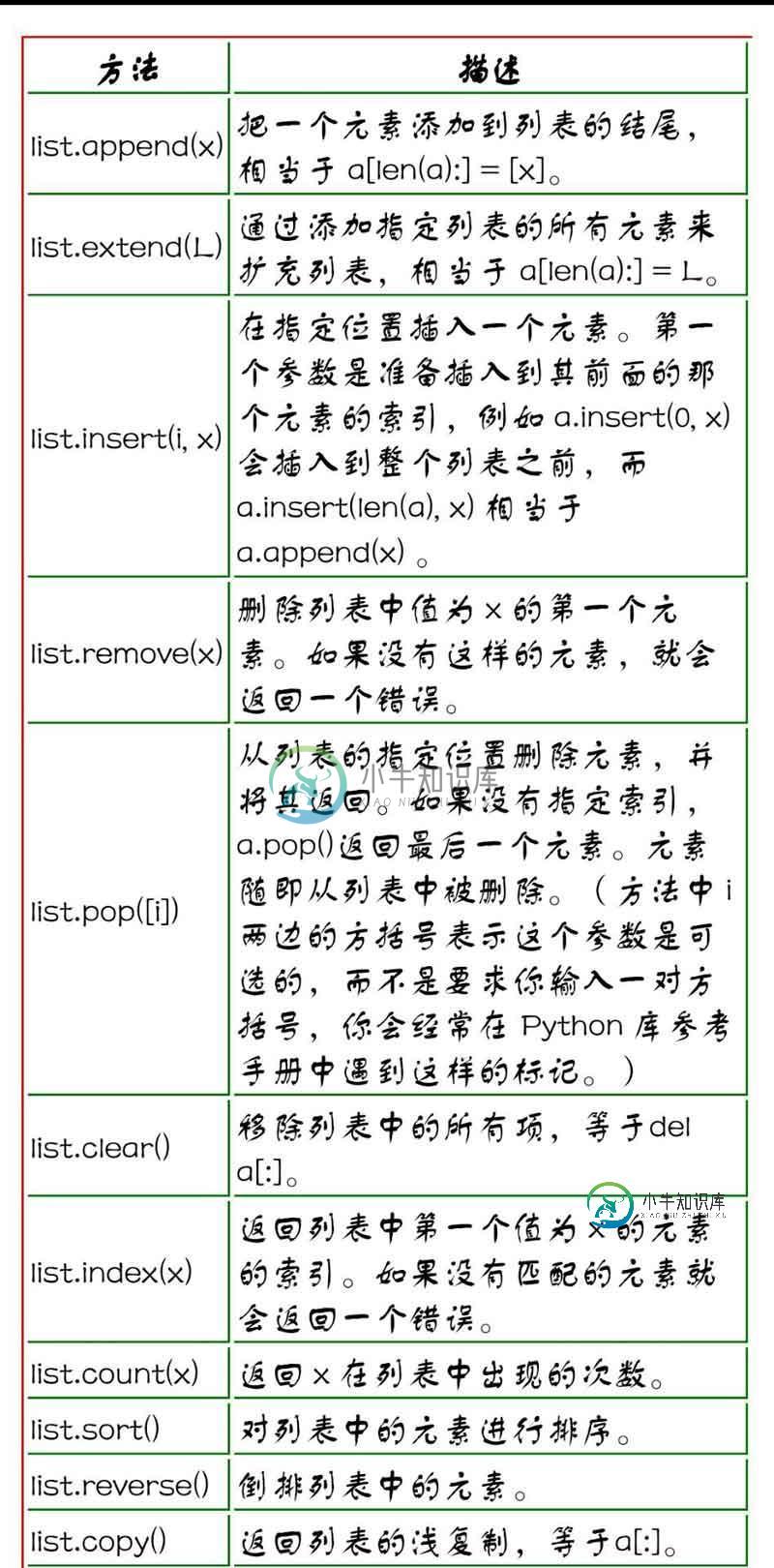 Python基本数据结构与用法详解【列表、元组、集合、字典】
Python基本数据结构与用法详解【列表、元组、集合、字典】本文向大家介绍Python基本数据结构与用法详解【列表、元组、集合、字典】,包括了Python基本数据结构与用法详解【列表、元组、集合、字典】的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python基本数据结构与用法。分享给大家供大家参考,具体如下: 列表 Python中列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和元组不能。以下是 Pyt
-
如何将字典键值项目应用于 spark 中数据集中的列?
spark的新成员...如何使用spark数据集中的列ask键获取一些值并将这些值作为新列添加到数据集中? 在python中,我们有类似的东西: 其中D是前面定义的python中的函数。 如何使用Java在spark中实现这一点?非常感谢。 编辑:例如:我有以下数据集df: 我想根据以下字典创建一个工作日列: 并将列添加回我的数据集df: 这只是一个示例,列A当然可以是整数以外的任何东西。
-
Java:将科学计数法转换为常规int
问题内容: 如何将科学计数法转换为常规int例如:1.23E2我想将其转换为123 谢谢。 问题答案: 如果您具有字符串形式的值,则可以使用
-
 3个用于数据科学的顶级Python库
3个用于数据科学的顶级Python库本文向大家介绍3个用于数据科学的顶级Python库,包括了3个用于数据科学的顶级Python库的使用技巧和注意事项,需要的朋友参考一下 Python有许多吸引力,如效率,代码可读性和速度,使其成为数据科学爱好者的首选编程语言。Python通常是希望升级其应用程序功能的数据科学家和机器学习专家的首选。 由于其广泛的用途,Python拥有大量的库,使数据科学家可以更轻松地完成复杂的任务,而无需很多编写
-
Java打印双科学符号,少位数[重复]
我搜索了一下,但我只找到了如何在没有科学符号的情况下减少数字(所以它最终会像一样,因为数字很小)。
-
 联通数科 后端开发工程师 笔试
联通数科 后端开发工程师 笔试投递岗位:后端开发工程师(西安) 投递base:西安 投递时间线:9.19投递,10.20收到笔试邀请链接,10.23笔试 考试内容:固定时间19:00-20:10,4部分,使用国考平台,除了编程其它都部分提交完不可修改。 1.行测数学:10道,类似行测里的数学计算,感觉更简单一点,排列组合更多更难一点。 2.单选:45道,涉及数据库,计算机网络,操作系统,java语言基础,数据结构等等,有难度,
-
 2023秋招-腾讯-数据科学-四面(HR面)
2023秋招-腾讯-数据科学-四面(HR面)公司:腾讯 部门:腾讯广告 岗位:技术研究-数据科学方向 形式:视频面试 视频面试平台:腾讯会议 时长:14分钟 流程: 1、自我介绍。 2、你对于选择第一份工作的考虑有哪些? 3、腾讯对于你的吸引力是什么? 4、放到一年后你希望你在工作上获得什么样的成果? 5、过往经历中你遇到的最困
-
 飞未云科-数据测试实习生【面经】
飞未云科-数据测试实习生【面经】base地 - 深圳,通过了全部面试环节(业务面+HR面),已拒 时间线:上周五(6.21)BOSS联系的,周一(6.24)交换的简历,周二(6.25)下午收到hr的电话沟通了一下·并添加了微信,后面定了周三(6.26)下午两点进行技术面,周四(6.27)上午十点进行hr面。 面试平台:飞书 电话 全程大概十分钟,说明了一下大概的情况:希望7.8能到岗;没有转正机会;薪资210r/天,每个月大概4
-
 建信金科4.20数据分析建模笔试
建信金科4.20数据分析建模笔试20道选择题一共60分,我怎么觉得第一题4个答案都不正确? 算法题20分,核心代码模式不用自己操心输入: 有一个长度为n的数组,从中找到这样一个序列:1.子序列的第一项任意;2.子序列的后一项比前一项大1。要求返回满足上述条件的最大的子序列的元素和。 范例1:输入[1,3,2,4,3],输出7 范例2:输入[4,6,2,5,3,4],输出9 其实挺简单的题,用动态规划做超时了,只过了80% SQL
-
 c++ 选手 美团oc+美团实习经历
c++ 选手 美团oc+美团实习经历本人不善言辞,写的不好多多见谅! 已在美团实习一个月!oc 很早很多面试过程有些记不清了,大家多多见谅! 实习投递开始时间: 3月初 投递公司:网易有道,字节,腾讯企业微信,美团,oppo ,京东 oc:字节,腾讯,美团 我算是开始投递比较早,oc比较早的一批,笔试我没法给大家太多经验,我的笔试成绩不算好。(腾讯、字节都是免笔试) 面试体验总结: 美团的面试体验是最好的,就跟在跟学长聊天一样。 腾