《龙湖集团数字科技》专题
-
1.5.3 厂商代理商集团客户类API
查询所有商户列表 接口描述 获取所有商户列表 URL /merchant HTTP Method GET 请求参数 无 返回参数 返回参数 是否必须 类型 描述 merchantId true String 厂商id merchantName true String 厂商名称 merchantNickname true String 厂商昵称 groupCode true String
-
 京东集团base北京java一面凉经
京东集团base北京java一面凉经准备的全没用上,好多概念记混了😭😭😭
-
 社招 赫基集团【服装设计】面经
社招 赫基集团【服装设计】面经第一轮初试是HR面的,可能是想让HR来把关,筛选一波。第二轮是总监,总监面还是比较紧张,问的问题也比较有特点,面完后 说是让HR通知我。 HR问的都是一些常见的问题,比如主聊一些校园经历,实习经历,对自己的职业规划,优缺点这样的问题,服装行业加班严重 也会问到你是否愿意加班这样的问题。 总监问的更多是关于服装设计方面的一些问题,具体的设计思路,为什么这么设计等等。 目前还在等通知,不知道能不能过。
-
 欢聚集团-产品运营实习二面
欢聚集团-产品运营实习二面问题比较简单,基本在深挖实习和项目经历 另有一个问题是问“平常你多采取什么方式来学习了解运营方向的知识”。#面经#
-
 三一集团提前批算法工程师
三一集团提前批算法工程师笔试选择题 一面技术面比较简单,python和linux的常用知识点。比如numpy库、pandas库,服务器常用操作等等 终面比较综合,问题没啥意思,但是面试官级别比较高。问的比如你讲讲做过的项目,亮点是什么,你学生工作最难忘的事这一类
-
 阅文集团24春招 产品岗速通
阅文集团24春招 产品岗速通985文科硕 两段产运实习,其中一段是阅文集团。 5月21号下午2点15场, 到3点30面完了hr面 速通1面2面hr面 推进太快有点惊讶,连面三场也是真的累 非技术岗位嘛,也没有问一些特别的问题,主要就是过往经历的挖掘,对AI方向的兴趣等,所以也没有特别多的面经可以分享。 另外就是问了一下offer情况,到岗时间,实习时长等。 hr说预计5月底会出结果 坐等吧
-
 巨人网络 挚文集团(探探) 笔试
巨人网络 挚文集团(探探) 笔试#秋招#巨人网络的岗位是游戏服务器开发,这纯海笔吧,笔试的选择题,关于语言的都是c++,编程题只能用c++写。哥们儿只会写go啊,巨人网络的笔试和挚文集团的笔试冲突了,幸好先去写了挚文的笔试。 挚文的算法题一道easy一道middle,middle是给一个string数组,元素为A->B->C,B->D->E这样的路径,求最长的路径。用递归和邻接矩阵找最长路径秒了。#巨人网络秋招##探探##挚文集
-
 蚂蚁集团前端开发一面面经
蚂蚁集团前端开发一面面经非递归实现二叉树中序遍历 使用栈来实现二叉树的中序遍历。 买卖股票的最佳时机 描述一个算法,找出给定股票价格列表中买卖一次获得最大利润的时机。 宏任务和微任务 宏任务(如setTimeout、setInterval)和微任务(如Promise、MutationObserver)的执行顺序,以及它们的区别和包含的例子。 箭头函数作为构造函数 讨论箭头函数不能作为构造函数的原因。 浮点精度问题 由于J
-
 联通数科 大数据开发
联通数科 大数据开发一面(11/3) 自我介绍 拷打项目 然后问了一个Flink反压的问题 二面(11/10) 自我介绍 拷打项目 问了前端展示大量数据,如何考虑?(可能大佬就是前端的) 问了用了哪些数据库? 问了Kafka 和 Flume 的应用场景? (可能时间比较紧张,所以问的比较急,二面没有遇到反问环节了)
-
Android修改@Getter在龙目岛
是否有可能为一种类型的字段修改Lombok的Getter?有一个可变的LiveData是LiveData的子级。我希望Lombok为返回LiveData而不是MutableLiveData的MutableLiveData字段创建getter。我希望你明白我的意思。 为了描述我所说的内容,我添加了一些代码: 这是关于Android中的MVVM模式和删除ViewModels中的样板代码。谢谢
-
龙卷风巨蟒-流视频
我已经建立一个网站一段时间了,我仍然坚持那件事: 我在dbm数据库中为我的网站存储了一些小视频(最多大约400MB),我想在我的网站上播放它们。 我正在使用Tornado python框架手工构建请求处理程序,我想知道如何构建我的处理程序。我从未发现媒体流是如何工作的,也没有在网上找到很多话题。 所以我想要实现的完整结果是在我的网站上有一个网络播放器,在那里我可以请求特定的视频,然后播放它们,而不
-
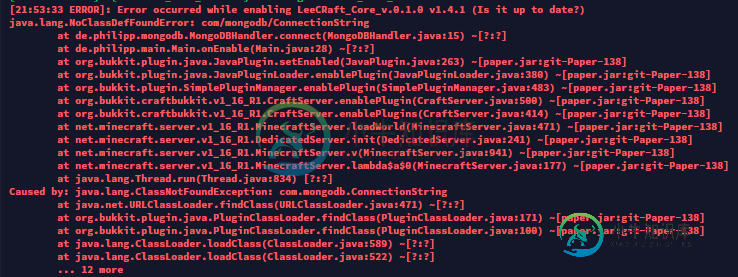 马文没有用龙头跑
马文没有用龙头跑我试图在Spigot 1.16.1插件中使用MongoDB,但我的maven导入遇到了问题。 在我的IDE(EclipseIDE)中没有错误。如果我导出插件并重新加载服务器,会出现以下错误: pom.xml 主课 我已经试着用一个。jar文件,但那也不起作用。 任何帮助都很感激
-
获取Python龙卷风版本?
如何获得我的python龙卷风模块版本的当前版本? 与其他软件包,我可以做到以下几点: 来源:如何检查python模块的版本?
-
龙目岛定制Setter和Getter
Lombok@Data annotation将在带注释的类上无声地添加字段的setter和getter。 如何在龙目岛添加基于条件的setter? lombok中有没有这样的支持 我已经在龙目岛文件中搜索了,我没有看到关于我的问题的解释。
-
龙目岛不生成方法
我试图在带有Java8的Maven项目中使用Lombok,但是当我应用@Data注释时,Lombok不会生成任何Getters和Setters。我尝试使用这里提到的Maven编译器插件版本3.5,但没有帮助。有人知道我需要使用哪些版本吗? pom.xml