《联影医疗》专题
-
继承会影响应用程序的性能吗?
我想知道是否可以通过使用更多的超类来提高应用程序的性能。我的问题是关于Kotlin的,但我假设对Java的答案也是一样的。 假设您有这样的继承模式(右边的类是他左边的类的子类): a 也就是说,您不需要所有子类中定义的所有东西,而只需要A类的属性和函数。由于一个模糊的原因,您的代码只使用Z类。 提前感谢您的回答。
-
影子罐不包括对脂肪罐的依赖
我对Gradle和shadow jar(Maven的Shade插件的Gradle版本)是新手。我正在构建一个胖jar,我想在其中合并服务文件(这就是我首先使用shadowjar的原因)。根据文档,shadowJar任务继承自gradle Jar任务。因此,我们可以假设它将完全像jar任务一样工作。 下面是jar任务的片段: 结果,它产生了一个脂肪罐与所有的依赖关系爆炸,什么是预期的。当我将任务名称
-
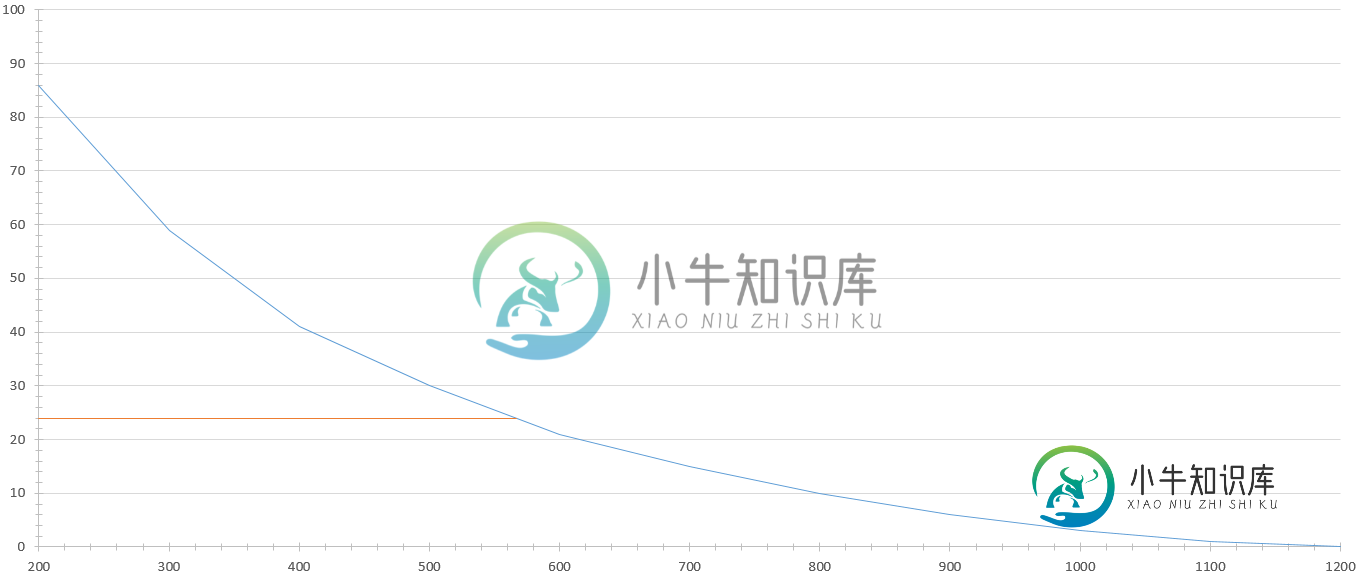 两个折线图和轴之间的阴影区
两个折线图和轴之间的阴影区我在网上搜索的第二天,虽然我发现了很多点击似乎应该有效,但没有一个似乎适用于我的特殊情况。 我有一个Excel图表,显示了两个系列。一个是指数衰减曲线,一个是与指数曲线相交的常数,但不继续超过它(估计橙色线的最后x值使其看起来像与蓝色曲线相交): 蓝色曲线的原始数据如下(出于保密原因,删除了数据标签,但x值在左边,y值在右边): 这就是我需要解决的问题:我需要用一种颜色填充蓝色曲线下面的所有区域,
-
调用ToList()是否会对性能产生影响?
使用时,是否有需要考虑的性能影响? 我正在编写一个从目录检索文件的查询,这就是查询: 那么,在决定进行这样的转换时,是否应该考虑某种性能影响--还是只在处理大量文件时才考虑?这是一个可以忽略不计的转换吗?
-
为什么合并器不影响输出?[副本]
-
memcpy()的速度受malloc()方式的影响很大
我编写了一个程序来测试的速度。然而,内存的分配方式对速度有很大的影响。 为什么memcpy()的速度每4KB就会急剧下降? 原因与GCC编译器有关,我用不同版本的GCC编译运行了这个程序: GCC版本------------------------
-
 2023oppo提前批影像算法工程师 面经
2023oppo提前批影像算法工程师 面经学历背景:双非本硕 计算机 研究方向:医学图像处理 无实习 一面: 基本围绕简历上的项目问,问简历上的具体算法,然后问了简历上会的技能。 二面: 还是问项目简历 1. 项目的具体流程 2.自己具体做了什么工作 3.项目算法与其他算法的效果对比 4. 遇到的困难,如何解决的 感觉整挺好,希望有三面吧。哈哈哈哈哈哈 #OPPO提前批#
-
 阿里影业 测开暑期 简历筛选面
阿里影业 测开暑期 简历筛选面电话面 50m 1.自我介绍 2.软件流程 3.自动化测试用的别人的还是自己实现的,有什么可以优化的地方,知道自己实现的缺陷为什么不用别人的 4.http https区别 5.怎么判断测试可以结束了 6.实习的一些工作内容 有接触代码和自动化吗 7.实习怎么适应的,有碰到什么问题,怎么沟通解决的 8.索引 9.测试计划编写都包含什么内容 10.冒烟测试的设计 11.jvm 12.了解redis和一
-
10.2.1生成大疆智图倾斜摄影索引
生成大疆智图倾斜摄影索引 实景三维数据(大疆智图/DJI Terra数据) (1)对于大疆智图生成的倾斜数据,在重建时数据格式选择osgb(不同版本略有差异) (2)重建完成后,打开任务所在文件夹 (3)双击models文件夹依次进入pc->0 (4)在LSV场景中点击“大疆智图”直接选择terra_osgbs文件夹即可
-
第四十二课 基于 PCF 的阴影优化
在 24 课中我们学习了使用阴影纹理技术来实现阴影效果,但是阴影纹理实现的效果不是特别好,阴影边缘出现了很多锯齿,就像下面图片中这样: 这一课中我们会介绍一个优化这个问题的方法,这个方法就是 PCF,这个算法核心就是对阴影纹理中当前像素的周围进行多次采样,并将当前像素的深度值分别与所有采样结果比较,通过对最后的结果求平均值,这样我们就使得阴影的边缘显得更加平滑,例如像下面这个阴影纹理: 每个格子里
-
1.2.4 计算思维对其他学科的影响
1.2.4 计算思维对其他学科的影响 随着计算机在各行各业中得到广泛应用,计算思维对许多学科都产生了重要影响。下面以数学、生物学和化学为例进行简单的介绍。 数学:计算机对数学来说过去只是一个数值计算工具,用于快速、大规模的数值计算, 对数值计算方法的研究导致了计算数学的形成。后来数学家利用计算机进行代数演算,形成 了计算机代数;利用计算机研究几何问题,形成了计算几何学。数学家还利用计算机去验证 数
-
从个人计算机或PS3™复制影像
从个人计算机或PS3™复制影像 可将图像文件案从个人计算机或PS3™复制至Memory Stick™或主机内存并使用PSP™播放。 使用USB连接线连接个人计算机和PSP™ 将图像文件案复制至Memory Stick™或主机内存
-
 影石360/科大讯飞飞星计划面经
影石360/科大讯飞飞星计划面经题主是做视觉slam,VIO相关的,本非硕9,有一段手机厂机器人相关的实习,一段自驾公司AVP泊车业务实习,一篇RAL在投,一篇TIV一审,本科做robomaster出身,有国奖,项目涉及地下停车场和城市场景多传感器融合的车辆位姿估计。 提前批OPPO简历挂,要求双9 字节机器人部门挂,宇宙厂招神仙 百度,网易泡着,估计也快挂了 大疆测评做完,初筛中 宁德时代,极氪初筛中 影石360,科大讯飞飞星
-
使用复杂关联表连接JPA实体,而不创建关联实体?
我正在尝试使用一个不是很简单的关联表在两个JPA实体之间进行ManyTo许多连接。我想知道是否有一种方法可以在不创建关联表实体的情况下实现这一点(类似于使用@JoinTable)。 表A-ID(PK) -名称 表b -ID(PK) -名称 TableMapping-ID(PK) -Parent\u ID(FK)-- 映射以我上面描述的方式存储,原因我不知道,也无法更改。很多地方都在这样使用它,我必
-
JPA/Hibernate左联接提取延迟异常,因为联接的实体为空
最初,我在supervisor字段上用注释了我的Employee实体,但这导致实体管理器生成大量SQL调用,从而降低了应用程序的性能。JPA/Hibernate查询速度慢,查询太多 是我的Employee实体上缺少了一些将填充空主管的构造函数,还是对我的查询进行了一些修改,将像注释那样执行,而不需要大量的单独SQL调用?