《python入门》专题
-
传入Python列表时变量名/编号非法
我试图通过Python在列表上运行SQL语句。通过传递列表,在本例中为日期。因为我想运行多个SELECT SQL查询并返回它们。我已经通过传递整数来测试了这一点,但是当尝试传递日期时,我得到了ORA-01036错误。变量名/编号非法。我正在使用Oracle数据库。 有什么建议可以让它运行吗?
-
为什么python要导入更低版本的Numpy?
我用pip安装了numpy,版本1.15 然而,当我使用python导入numpy时,我得到了版本1.7.1 这个numpy是从哪里来的,我怎样才能禁用它? 我检查了sys.path的所有文件夹,并删除了Numpy版本1.7.1的文件夹 导入系统路径['''/usr/lib/python2.7','/usr/lib/python2.7/plat-x86_64-linux-gnu','/usr/li
-
尝试导入python模块时的疯狂行为
我想用Apache mod-wsgi部署的django webapp有一些问题,我已经将它们追溯到这一行(django标记模块丢失): 现在,当我尝试以root和apache用户身份运行pip-python(我使用的是CENTOS 6)时,这里是我的输出: 已安装标记。。。 Apache用户也这么说! 确定根可以导入标记! 但是apache用户不能!!!!!我如何才能使这项工作???? 我已经对d
-
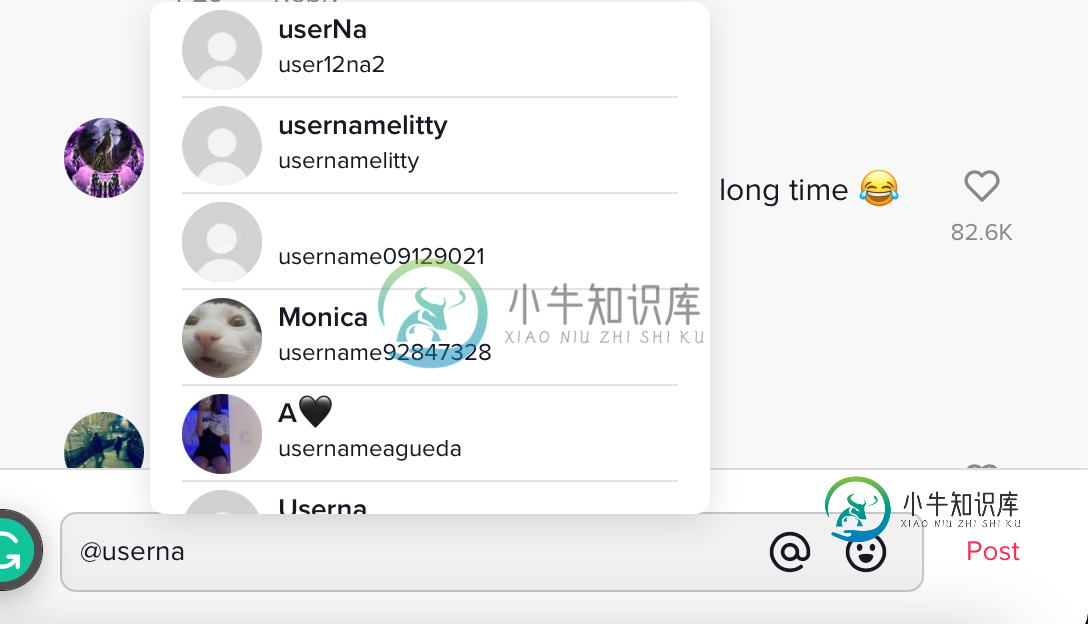 如何使用python selenium在DIV中输入文本
如何使用python selenium在DIV中输入文本我正在尝试创建一个机器人,在各种TikTok帖子上留下评论,其中一些帖子需要留下一个提及,例如用户名。问题是,TikTok的注释框是一个div元素,而不是一个input元素。 首先,我知道这个StackOverflow帖子,对一些人来说,它只是说使用javascript更新div值。问题是,如果编辑代码,它将不会显示用户名下拉菜单 “用户名下拉菜单”是什么? 这是一个小菜单,上面有你想要提及的用户
-
在Apache Beam/Dataflow Python流中写入文本文件
我有一个非常基本的Python Dataflow工作,从pub/sub读取一些数据,应用FixedWindow并写入Google Cloud Storage。 输出被写入--output中特定的位置,但只写入临时阶段,即。 当进一步测试时,我注意到streaming_wordcount示例也有同样的问题,但是标准wordcount示例写得很好。也许问题在于开窗,或者从PubSub阅读? Write
-
如何使用带Python的line协议写入influxdb
我正在使用line协议和Python写入influxDB。下面是创建数据库和工作正常的代码。 我想在下面写到influxDB中使用行协议的示例数据 我正在使用最新版本的InfluxDB支持行协议。 知道Client.Write语句对于python客户机是什么样子吗?
-
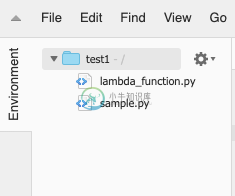 如何导入函数从python file1到file2在Lambda
如何导入函数从python file1到file2在Lambda在Lambda中使用Python 3.7,如何从sample.py导入函数run()lambda_function.py 这是我的代码:File1-lambda_函数。py: 文件2-示例。py: 错误:{"错误消息":"无法导入模块'示例':没有名为'sample.py'的模块;'示例'不是一个包","错误类型":"运行时。####################################
-
从文件夹导入Python 3中的.csv文件
同一位置有2个csv文件:1-candidates.csv,2-store.csv 当我在使用以下代码时导入candidates.csv filw时,它被导入: pandas._libs.parsers.textreader._convert_with_dtype()中的pandas_libs\parsers.pyx pandas._libs.parsers.textreader._string_
-
python导入错误“没有名为appengine.ext的模块”
运行此代码后,我发现导入错误:- 如何使用google.apengine.ext
-
使用python将数据块数据帧写入S3
我有一个名为df的数据库数据帧。我想将它作为csv文件写入S3存储桶。我有S3存储桶名称和其他凭据。我检查了这里给出的在线留档https://docs.databricks.com/spark/latest/data-sources/aws/amazon-s3.html#mount-aws-s3它说使用以下命令 但我有的是数据帧,而不是文件。怎么才能实现?
-
Python(report):导入excel文件时出现xlrd错误
我是python的初学者,我有以下(令人尴尬的)问题: 我正在尝试使用 xlrd 导入 excel 文件,但我有“文件未找到错误”。 有人能帮助新手吗? 非常感谢,马特奥 -导入xlrd #加载数据文件路径=(r"C:\用户\MCECCHI\桌面\oil_exxon.xls") WB = xlrd . open _ workbook(path)sheet = WB . sheet _ by _ i
-
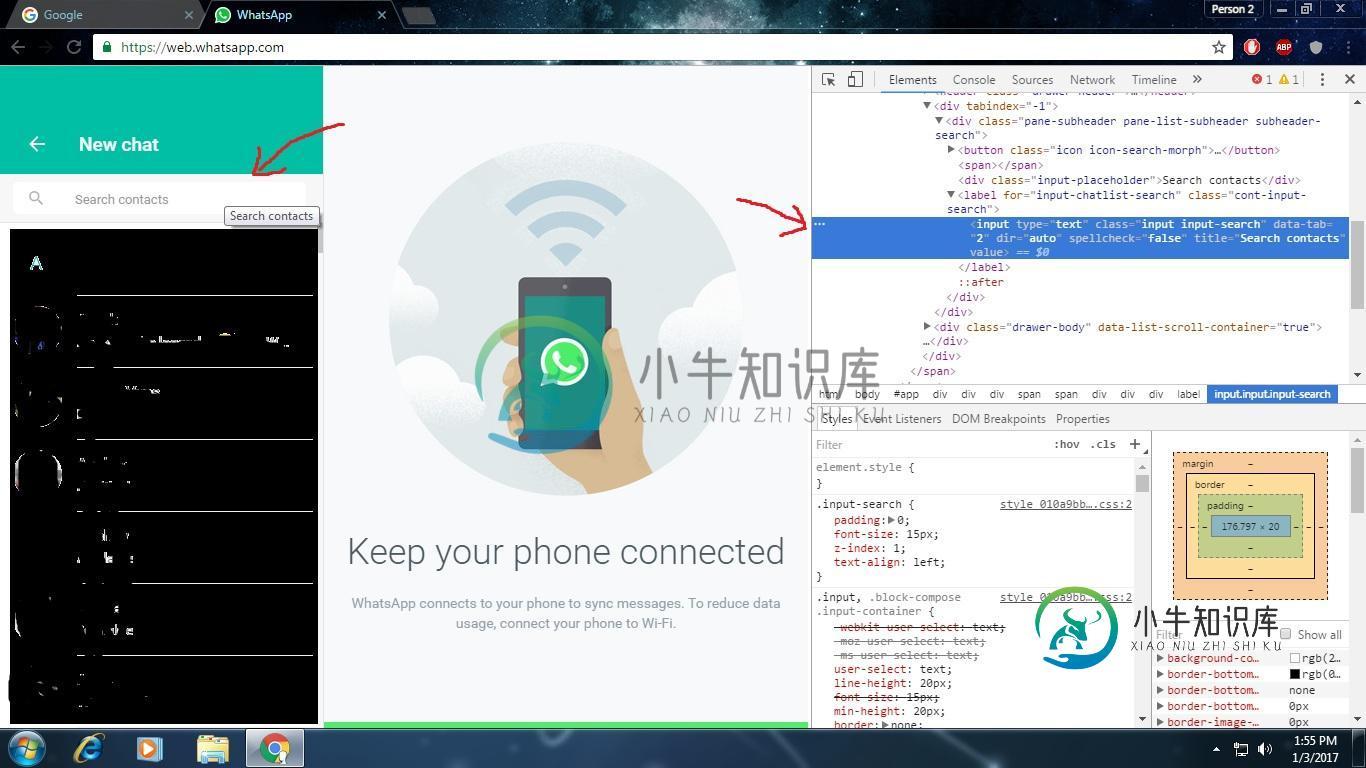 如何使用python填充输入文本字段?
如何使用python填充输入文本字段?驱动程序的fire中有一个bug。使用chrome驱动解决了这个问题。 代码 我试过联系搜索。clear()和click()方法,但输入仍然为空。代码来自https://web.whatsapp.com/登录后会出现一个名为“搜索”或“开始新聊天”的字段。我想在该字段中输入文本。
-
带有google appengine的python boilerpipe出现导入错误?
我正在尝试工作与谷歌应用程序引擎Python boilertube。我在本地机器上安装了锅炉管道,工作正常。 使用
-
第 19 章 在 Python 中使用 Neo4j 嵌入模式
这描述了 _neo4j-embedded_,让你在Python应用中嵌入Neo4j数据库的一个Python库。 从参考文档和这个章节的安装介绍分开,你可以参考:第 9 章 在Python应用中使用Neo4j。 这个工程在GitHub上面的源代码地址: https://github.com/neo4j/python-embedded 19.1. 安装 注意:Neo4j 数据库(来自社区版)本身就被包
-
Python进阶02 文本文件的输入输出
Python具有基本的文本文件读写功能。Python的标准库提供有更丰富的读写功能。 文本文件的读写主要通过open()所构建的文件对象来实现。 创建文件对象 我们打开一个文件,并使用一个对象来表示该文件: f = open(文件名,模式) 最常用的模式有: "r" # 只读 “w” # 写入 比如 >>>f = open("test.txt","r") 文件对象的方法 读取: content =