《群面》专题
-
一个Kafka话题能搞定多少消费群体?
假设我有一个Kafka主题,大约有10个分区,我知道每个消费群体应该有10个消费者在任何给定的时间阅读该主题,以实现最大的平行性。 然而,我想知道,对于一个主题在任何给定时间点可以处理的消费者群体的数量,是否也有任何直接规则。(我最近在一次采访中被问及这一点)。据我所知,这取决于代理的配置,以便在任何给定的时间点可以处理多少个连接。 然而,我只是想知道在给定的时间点可以扩展多少个最大消费群体(每个
-
Kafka:多个实例中的单一消费者群体
null null 使用简单消费者或低级消费者可以控制分区,但如果一个实例宕机,其他三个实例将不会处理来自第一个实例中使用的分区的消息
-
在kafka集群节点间分配数据套接字
如有任何帮助,不胜感激。
-
单个集群中的AWS ALB入口和Nginx入口
我有一个关于库伯内特斯·安格拉斯的简短问题。我在单个集群中拥有Nginx入口控制器和AWS ALB入口控制器以及Nginx和AWS ALB入口资源。这两个入口资源都指向单个服务和部署文件,这意味着这两个入口资源都指向相同的服务。然而,当我点击Nginx入口URL时,我能够看到所需的页面,但是使用AWS ALB入口,我只能看到apache默认页面。我知道这听起来不太实际,但我正在尝试用这两种入口资源
-
Tomcat的群集/会话复制无法正确复制
问题内容: 我正在本地计算机上的Tomcat 7上设置群集/复制,以评估它是否可与我的环境/代码库一起使用。 建立 我在不同端口上运行的同级目录中有两个相同的tomcat服务器。我已经在其他两个端口上监听了httpd,并作为VirtualHosts连接到了两个tomcat实例。我可以在配置的端口上访问两种环境并与之交互。一切都按预期进行。 Tomcat服务器在server.xml中启用了集群功能:
-
RabbitMQ 对集群节点停止顺序有要求吗?
本文向大家介绍RabbitMQ 对集群节点停止顺序有要求吗?相关面试题,主要包含被问及RabbitMQ 对集群节点停止顺序有要求吗?时的应答技巧和注意事项,需要的朋友参考一下 RabbitMQ 对集群的停止的顺序是有要求的,应该先关闭内存节点,最后再关闭磁盘节点。如果顺序恰好相反的话,可能会造成消息的丢失。
-
请你说一下分布式和集群的概念?
本文向大家介绍请你说一下分布式和集群的概念?相关面试题,主要包含被问及请你说一下分布式和集群的概念?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 分布式:是指将不同的业务分布在不同的地方, 集群:是指将几台服务器集中在一起,实现同一业务。 分布式中的每一个节点,都可以做集群,而集群并不一定就是分布式的。集群有组织性,一台服务器垮了,其它的服务器可以顶上来,而分布式的每一个节点,都完成不同
-
春云Kafka流——不同集群中的死信主题
我有一个Kafka消费者。如果消费者未能阅读任何信息,我需要将其发送到死信主题。我使用的是Spring cloud Kafka stream,我在这样的配置中启用了DLQ。 但我的常规消费者话题与DLQ话题不同。有可能做到这一点吗?如果是,你能指导我完成配置吗?
-
 允许在kubernetes中与nginx进行集群内通信
允许在kubernetes中与nginx进行集群内通信我目前的k8s设置面临一个问题。在生产中,我启动了我们每个服务的三个副本并将它们放在一个pod中。当pod相互通信时,我们希望pod以循环方式与pod中的每个容器通信。不幸的是,由于TLS保持活动,pod之间的连接永远不会终止——我们不想专门更改该部分——但我们确实希望pod中的每个容器都能正常通信。这就是我们现在所拥有的: 如果API试图与pod OSS通信,它将仅与第一个容器通信。我希望API
-
两种不同Kafka群集设置的Spring Kafka配置
在我们的一个基于spring boot的服务中,我们打算同时连接到两个不同的kafka集群。这些集群都有自己的引导服务器集、主题配置等。它们之间没有任何关联,就像这个问题中的情况一样。 我将有不同类型的消息从不同主题名称的每个集群中读取。可能有或可能没有多个生产者通过此服务连接到两个集群,但我们肯定每个集群至少有一个消费者。 我想知道如何在application.yml中定义属性以满足此设置,以便
-
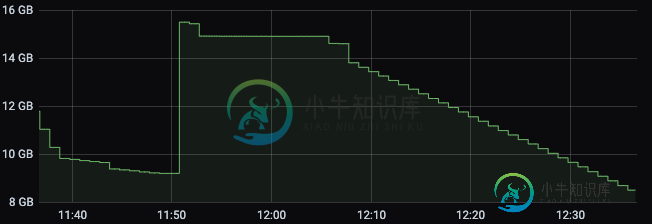 运行Apache Flink作业时K8s群集内存减少
运行Apache Flink作业时K8s群集内存减少我们正在尝试在K8s集群上部署apache Flink作业,但我们注意到一个奇怪的行为,当我们开始我们的作业时,任务管理器内存以分配的数量开始,在我们的例子中是3 GB。 最终,内存开始减少,直到达到约160 MB,此时,它会恢复一点内存,所以不会达到其极限。 这种非常低的内存通常会导致作业因任务管理器心跳异常而终止,即使在尝试查看Flink仪表板上的日志或执行作业流程时也是如此。 为什么它的内存
-
Spring云总线-刷新特定的客户端集群
我在Kafka的spring云总线上配置了一个spring云配置服务器。我正在使用Edgware。随boot 1.5.9一起发布。当我向endpoint/总线/刷新发送POST请求时,destination=clientId:dev:*在主体中通过POSTMAN to config server,所有客户端都会刷新其bean,即使其clientId与destination字段中的值不匹配。 以下是
-
如何在熊猫中添加“群内订单”一栏?
采用以下数据帧: 我想增加两列: 行在其组中的顺序 我知道我可以用自定义应用程序来实现,但我想知道是否有人有什么有趣的想法?(当有许多组时,这也很慢。)这里有一个解决方案:
-
实现多个唯一域名网站的K8s集群
null 优点: 每个网站的POD/容器级隔离 可能是骗局? null null null null
-
在kubernetes集群中通过Ingress公开多个服务
我使用几个独立服务运行Kubernetes单节点dev集群--Nginx proxy(端口80)和elasticsearch(端口9200)。有没有办法用ingress公开这些服务,用一个LoadBalancer IP拥有入口点?(X.X.X.X:80和X.X.X:9200) 我读过关于入口限制,它只能用80和443端口访问。但是,也许,存在一些变通方法? 请Thx提供任何建议 但如果以后您想公开