《群面》专题
-
集群与非集群
问题内容: 我对SQL(Server2008)的较低层次的了解是有限的,现在我们的DBA对此提出了挑战。让我解释一下这种情况:(我已经提到一些明显的陈述,希望我是对的,但是如果您发现有问题,请告诉我)。 我们有一张桌子,上面放着人们的“法院命令”。创建表(名称:CourtOrder)时,我的创建方式如下: 然后,我将非聚集索引应用于主键(以提高效率)。我的理由是,这是一个唯一字段(主键),应该像我
-
1.8.3 集群&集群发现
Cluster Cluster.EdsClusterConfig Cluster.OutlierDetection Cluster.LbSubsetConfig Cluster.LbSubsetConfig.LbSubsetSelector Cluster.LbSubsetConfig.LbSubsetFallbackPolicy (Enum) Cluster.RingHashLbConfig C
-
集群
一、负载均衡 负载均衡算法 转发实现 二、集群下的 Session 管理 Sticky Session Session Replication Session Server 一、负载均衡 集群中的应用服务器(节点)通常被设计成无状态,用户可以请求任何一个节点。 负载均衡器会根据集群中每个节点的负载情况,将用户请求转发到合适的节点上。 负载均衡器可以用来实现高可用以及伸缩性: 高可用:当某个节点故障
-
群组
把用户放到用户群组里。你可以设置文件与目录的所属群组的权限。 查看用户群组 用 groups 命令可以查看用户所属的群组。 groups 用户 比如查看之前创建的 wanghao 所属的用户组: groups wanghao 会返回: wanghao : wanghao wheel 表示 wanghao 属于两个用户组,wanghao 还有 wheel 。 创建群组 groupadd 可以添
-
集群
集群为一组LBAgent转发节点的集合。 负载均衡集群是一组转发节点LBAgent的集合,一般情况下一个集群下配置两个LBAgent节点互为主备即可,同一集群下的LBAgent节点的VRRP路由ID必须相同。 入口:在云管平台单击左上角导航菜单,在弹出的左侧菜单栏中单击 “网络/负载均衡集群/集群” 菜单项,进入集群页面。 创建集群 该功能用于创建负载均衡集群。 单击列表上方 “新建” 按钮,弹出
-
集群
帮助用户快速搭建Kubernetes集群。 云管平台支持创建和纳管Kubernetes集群,目前支持以下纳管集群的方式。 基于 云联壹云 、Aliyun、AWS 平台的虚拟机创建 Kubernetes 集群。 导入已创建的集群,支持纳管 Kubernetes 集群和 OpenShift 集群。 Kubernetes集群是容器运行所需要的云资源的集合。一个Kubernetes集群由1~3个控制节点和
-
集群
集群章节帮助用户快速搭建集群,并帮助用户管理节点、命名空间以及RBAC授权管理等。 集群 帮助用户快速搭建Kubernetes集群。 节点 节点是Pod的实际运行环境。 存储类 存储类用于定义容器集群中的不同存储类型。 命名空间 命名空间用于逻辑上隔离Kubernetes集群中的资源。 角色 角色定义了对集群的指定命名空间下资源的权限。 集群角色 集群角色定义了对集群下资源的权限。 角色绑定 角色
-
集群
etcd 集群 下面我们使用 Docker Compose 模拟启动一个 3 节点的 etcd 集群。 编辑 docker-compose.yml 文件 version: "3.6"services: node1: image: quay.io/coreos/etcd:v3.4.0 volumes: - node1-data:/etcd-data expose:
-
集群部署 - 升级集群
主版本和次版本升级 Seafile 在主版本和次版本中添加了新功能。有可能需要修改一些数据库表,或者需要更新搜素索引。一般来说升级集群包含以下步骤: 更新数据库 更新前端和后端节点上的符号链接以指向最新版本。 更新每个几点上的配置文件。 更新后端节点上的搜索索引。 一般来说,升级集群,您需要: 在一个前端节点上运行升级脚本(例如:./upgrade/upgrade_4_0_4_1.sh) 在其他所
-
集群部署 - MariaDB/Memcached集群
按照Seafile 集群文档中给出的推荐架构,Seafile 集群需要使用一个分布式、高可用的数据库和缓存集群。在本文档中,我们给出一个在 3 台服务器上部署 MariaDB 和 Memcached 集群的案例。 硬件和操作系统需求 最少使用3台服务器部署来集群,每台机器都应该有: 2核、4GB内存。 1个SATA磁盘用来存储操作系统。 1个SATA磁盘用来存储MariaDB数据。也可以把 Mar
-
Akka集群、集群分片和集群单例用例
null
-
 群硕 Java面经
群硕 Java面经第一面 在腾讯会议里面试,个人感觉问问题的顺序很乱,一会问这一块一会问那一块,可能是面试官自己的风格吧。比较深挖实习和项目,比较少八股文,写一些自己还记得的。 自我介绍 聊实习中做的功能,流量有多大,深挖具体细节 项目角色问题(自己做的比较简单,没有区分用户和管理员) 项目是否部署到云服务器 项目中保持缓存与数据库一致如何实现的 Redis数据结构 Redis命令 Git命令,遇到过合并冲突吗 0
-
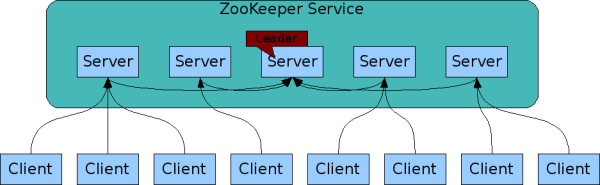 ZooKeeper 集群 ?
ZooKeeper 集群 ?本文向大家介绍ZooKeeper 集群 ?相关面试题,主要包含被问及ZooKeeper 集群 ?时的应答技巧和注意事项,需要的朋友参考一下 为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。通常 3 台服务器就可以构成一个 ZooKeeper 集群了。ZooKeeper 官方提供的架构
-
Cluster (集群)
稳定性: 2 - 稳定的 一个单一的 Node.js 实例运行在一个单独的线程上。 为了利用多核系统,用户有时会想启动一个 Node.js 进程的集群去处理负载。 cluster 模块可以轻松地创建一些共享服务器端口的子进程。 const cluster = require('cluster'); const http = require('http'); const numCPUs = requ
-
Redis 集群
Redis 集群(Redis Cluster) 是 Redis 提供的分布式数据库方案。 既然是分布式,自然具备分布式系统的基本特性:可扩展、高可用、一致性。 Redis 集群通过划分 hash 槽来分片,进行数据分享。 Redis 集群采用主从模型,提供复制和故障转移功能,来保证 Redis 集群的高可用。 根据 CAP 理论,Consistency、Availability、Partition