《吐槽》专题
-
为什么要增加任务管理器的数量而不是每个任务管理器的任务槽?
根据Flink留档,存在两个维度来影响任务可用的资源量: 任务管理器的数量 任务管理器可用的任务槽数。 每个TaskManager有一个插槽意味着每个任务组在单独的JVM中运行(例如,可以在单独的容器中启动)。拥有多个插槽意味着更多的子任务共享同一个JVM。同一JVM中的任务共享TCP连接(通过多路复用)和心跳消息。它们还可以共享数据集和数据结构,从而减少每个任务的开销。 文档中有了这一行,您似乎
-
Flink时间缓冲水槽
我正在尝试编写一个Flink应用程序,它从Kafka读取事件,从MySQL丰富这些事件并将这些数据写入HBase。我正在中进行MySQL丰富,我现在正在尝试弄清楚如何最好地写入HBase。我想批量写入HBase,所以我目前正在考虑使用,后跟标识(仅返回),然后编写,它获取记录列表并批处理放入。 这是正确的做事方式吗?仅仅为了进行基于时间的缓冲而使用所有窗口和应用窗口感觉很奇怪。
-
Vue和引导Vue-动态使用插槽
我试图在bootstrap-vue表中创建一个插槽,用自定义组件呈现任何布尔值。 所以我有一张简单的桌子 现在,如果我想以特定的方式呈现单个列,我必须使用插槽 它是有效的,因为我知道是一个布尔值。 我想概括这种行为,但我不能在模板中使用,也不能在模板上使用...这个想法是创建一个包含我所有布尔字段的数组并迭代它... 像这样的
-
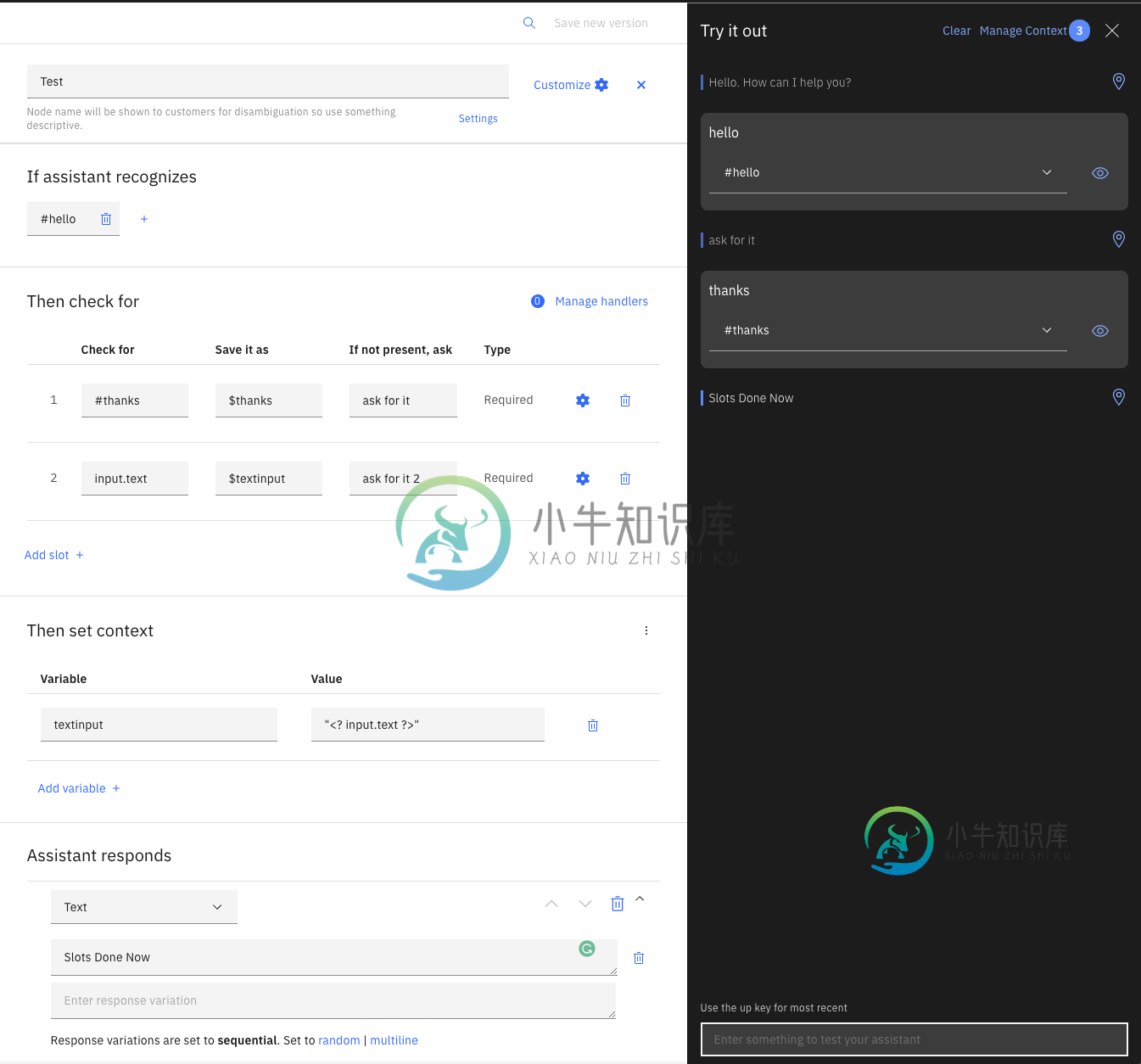 IBM Watson Assistant-如何使用输入。插槽中的文本
IBM Watson Assistant-如何使用输入。插槽中的文本我使用IBM沃森助手聊天机器人。我有一个有两个插槽的对话节点。第一个插槽工作正常。节点被触发,机器人要求第一个插槽,因为它不存在。 然后我想让机器人请求第二个插槽。给出的答案应该存储在$variable中。我试图通过,因为我想存储那里给出的各种输入。 但是机器人没有询问第二个插槽,而是跳过它,并将插槽1中给出的答案存储在插槽2$变量中。我猜这是因为机器人也会检查输入。文本出现在插槽1中。为了明确起
-
Impex old pk在将自定义组件导入内容槽时格式错误
我试图在Hybris 6.4中创建一个impex脚本,以便通过Hybris管理控制台中的impex导入工具将自定义组件放入ContentSlot。当我运行impex时,我得到的是,错误。我已经使用BackOffice应用程序来验证我的自定义组件是否存在。我需要做什么才能将我的组件分配到ContentSlot,而不会遇到错误? 这是我的弹劾。 请注意,我还尝试了$catalogVersion宏的这种
-
通过Android设备的手机扬声器播放音频槽
是否可以通过Android设备的手机扬声器播放音频?手机内部较小的扬声器,可产生低音量声音,只有在将耳朵贴在电话上时才能听到。 希望我的描述足够清楚,可以理解我的问题。 如果可能的话,一个如何实现这一点的例子将非常有帮助。 目前我正在使用下面的代码初始化我的MediaPlayer。
-
Storm之间的通信。亚马尔的主管。插槽。端口和配置。setNumWorkers(#workers)方法调用
其他暴风用户: 建立Storm群的指南(https://github.com/nathanmarz/storm/wiki/Setting-up-a-Storm-cluster)指示主管。插槽。端口配置属性的设置应确保为机器上的每个工作进程分配一个单独的端口。 我的理解是,每个worker都是一个JVM实例,用于侦听来自nimbus控制器的命令。。因此,每个人都在一个单独的端口上监听是有道理的。 然
-
使用 Apache 水槽进行排序
我们摄取的数据可以使用Flume进行排序吗? 我设计了一个简单的多通道水槽代理,它将数据摄取到HDFS中的两个目录中。但我不知道的是,水槽是否支持在这两个通道之间进行排序。 到目前为止,我所假设的是,我的源将是一个假脱机目录。,每当我输入行(每行包含一个唯一的关键字),该行必须进入某个特定的通道。 有什么想法吗?
-
运行水槽下载twitter数据时出现未处理java.lang.错误
当我运行这个命令时 水槽正在启动,但过了一段时间,它向我抛出了不允许水槽下载的异常。我收到以下错误: 出现此错误后,它尝试进行检查,但未能下载数据。 我是Hadoop和Flume的新手。
-
如何使用阿帕奇水槽从txt文件中读取日志
我有阅读持续增长的问题。txt文件。我知道我可以从网上读到一些东西,比如说 但是如何用文本文件做呢?我应该传递什么而不是netcat?
-
如何解决twitter流数据时水槽中的404错误?
我正在尝试使用flume从Twitter API流传输一些数据。代码最初确实有效。但是现在我得到了404错误: 下面是我的conf文件代码。
-
启动水槽代理时找不到文件异常
我第一次安装Flume。我使用的是hadopop-1.2.1和Flume 1.6.0 我试着按照这个指南建立一个水槽代理。 我执行了这个命令:< code > $ bin/flume-ng agent-n $ agent _ name-c conf-f conf/flume-conf . properties . template 它说< code>log4j:ERROR setFile(null
-
如何通过Java代码更改Apache水槽的配置文件?
我目前正在进行一个大数据项目,对推特的热门话题进行情绪分析。我学习了cloudera的教程,了解了如何通过flume向Hadoop发送推文。 http://blog . cloud era . com/blog/2012/09/analyzing-Twitter-data-with-Hadoop/ flume.conf: 现在为了将其扩展到我的应用程序,我需要 flume 配置文件中的关键字部分来
-
如何确定水槽拓扑方法?
我正在设置flume,但是不确定我们的用例应该使用什么样的拓扑。 我们基本上有两个web服务器,它们能够以每秒2000个条目的速度生成日志。每个条目的大小约为137字节。 目前我们已经使用rsyslog(写入tcp端口),php脚本将这些日志写入其中。我们在每个Web服务器上运行一个本地水槽代理,这些本地代理侦听tcp端口并将数据直接放入hdfs。 所以localhost:tcpport是“水槽源
-
水槽假脱机目录源:无法加载较大的文件
我正在尝试使用水槽假脱机目录摄取到 HDFS(SpoolDir 我正在使用Cloudera Hadoop 5.4.2。(Hadoop 2.6.0,Flume 1.5.0)。 它适用于较小的文件,但适用于较大的文件时失败。请在下面找到我的测试场景: < li >千字节到50-60兆字节的文件,处理时没有问题。 < li >大于50-60MB的文件,它将大约50MB写入HDFS,然后我发现flume代