《剑心互娱》专题
-
 灵犀互娱 一面凉经
灵犀互娱 一面凉经灵犀游戏测开一面,之前投递都是后台开发,想试一下测试方向,于是第一个测开面试; 面试岗位:游戏测试开发工程师 面试部门:灵犀互娱 - 质量管理中台 共50min,无手撕 1.自我介绍 2.实习相关 线上处理过什么bug吗 处理线上bug的流程 有处理bug的系统之类的吗 修复问题后代码提交后怎么提交到线上的 上传上去后,代码是直接生效吗,实际怎么解决的 上传到代码库后怎么在线上生效 出现问题后是你
-
 灵犀互娱 数分笔试
灵犀互娱 数分笔试1.手撕kmeans(不会) 2.sql 百分位取数(percent rank) 字符串拆分(不会) 3.编程 滑动窗口 不用库取随机数(取当前时间毫秒作为种子)
-
 阿里灵犀互娱一面
阿里灵犀互娱一面#我的实习求职记录# 客户端开发 5.7笔试 5.17一面 项目方面: 详细问了项目的一部分,深入了一些点 如raycast,vector3 八股方面: 栈,堆,继承,多态,虚函数等基本的点都问到了(内联函数我给忘了) 提了快排和堆排 (堆排怎么删除元素我给忘了) 双非摆烂仔的第一次面试 希望能有二面(也希望二面不要太难)
-
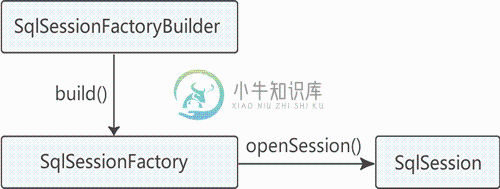 MyBatis核心对象
MyBatis核心对象主要内容:SqlSessionFactoryBuilder,SqlSessionFactory,SqlSessionMyBatis 有三个基本要素: 核心接口和类 MyBatis核心配置文件(mybatis-config.xml) SQL映射文件(mapper.xml) 下面首先介绍 MyBatis 的核心接口和类,如下所示。 每个 MyBatis 应用程序都以一个 SqlSessionFactory 对象的实例为核心。 首先获取 SqlSessionFactoryBuilder 对象,可以
-
 Hibernate核心接口
Hibernate核心接口主要内容:1. Configuration,2. SessionFactory,3. Session,4. Transaction ,5. Query在 Hibernate 中有 5 个常用的核心接口,它们分别是 Configuration 接口、SessionFactory 接口、Session 接口、Transaction 接口和 Query 接口。本节,我们就对这 5 个核心接口进行详细讲解。 1. Configuration 正如其名,Configuration 主要用于管理 Hiber
-
 Solr核心(内核)
Solr核心(内核)主要内容:创建一个核心,使用create命令,使用create_core命令,删除核心Solr核心(Core)是Lucene索引的运行实例,包含使用它所需的所有Solr配置文件。我们需要创建一个Solr Core来执行索引和分析等操作。 Solr应用程序可以包含一个或多个核心。 如果需要,Solr应用程序中的两个核心可以相互通信。 创建一个核心 安装和启动Solr后,可以连接到Solr的客户端(Web界面)。访问以下网址: http://Localhost:8983/solr/ 如
-
4.1 核心概念
Spring Data repository抽象中最核心的接口就是Repository(显而易见的哈)。该接口使用了泛型,需要提供两个类型参数,第一个是接口处理的域对象类型,第二个是域对象的主键类型。这个接口常被看做是一个标记型接口,用来获取要操作的域对象类型和帮助开发者识别继承这个类的接口。在Repository的基础上,CrudRepository接口提供了针对实体类的复杂的CRUD(增删改查
-
Spring WebFlux/Reactor核心
我用的是Spring WebFlux,Reactor核心。我有一个疑问。Spring webflux是否遵循每个请求的线程模型?我想问的是,在spring webflux中,一个请求可以在多个TOMCAT线程中执行吗?
-
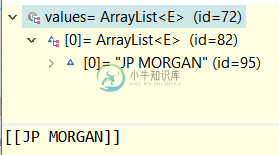 放心-Json提取
放心-Json提取我正在收到以下结构的响应: ] 每当我想提取JSON属性时,例如描述,最终的对象不是我所期望的。它创建具有ArrayString的列表。 如何将值从此JSON对象获取到包含值的简单列表?谢谢
-
Asp。NETMVC核心CORS
我们正在开发具有移动部分和网络用户界面的应用程序。Web UI使用角,我们在后端配置cors时遇到了问题。我们的代码如下(只是对我们的问题很重要的代码): 从stackoverflow上的文档和其他帖子来看,这应该是可行的,但不是。我们错过了什么? thnx 编辑: 这是邮递员的请求: 卷曲'https://guw.azurewebsites.net/api/token'-X OPTIONS-H'
-
9.3 核心思想
Kafka Streams 是一个处理和分析 Kafka 系统中的数据的客户端库。 它建立在重要的流处理概念之上,例如能够恰当地区分 event time 和 Processing time 、支持 window 操作以及简单有效、支持实时查询的应用程序状态管理。 Kafka Streams 的入门门槛很低。我们可以在单节点环境上快速实现一个小规模的验证性的程序,只要程序能在多节点的集群环境成功运
-
6.2 数据中心
有一些部署需要维护一个跨越多个数据中心的数据管道。对此,我们推荐的方法是在每个拥有众多应用实例的数据中心内部署一个本地Kafka集群,在每个数据中心内只与本地的kafka集群进行交互,然后各集群之间通过镜像进行同步,(请参阅镜像制作工具了解怎么做到这一点)。. 这种部署模式允许数据中心充当一个独立的实体,并允许我们能够集中的管理和调节数据中心之间的复制。在这种部署模式下,即使数据中心间的链路不可用
-
2.1 注册中心
服务注册中心用来实现服务发现和服务的元数据存储。 当前rpcx支持多种注册中心, 并且支持进程内的注册中心,方便开发测试。 rpcx会自动将服务的信息比如服务名,监听地址,监听协议,权重等注册到注册中心,同时还会定时的将服务的吞吐率更新到注册中心。 如果服务意外中断或者宕机,注册中心能够监测到这个事件,它会通知客户端这个服务目前不可用,在服务调用的时候不要再选择这个服务器。 客户端初始化的时候会从
-
2.4.3 消息中心
一个简易的消息管理模块,你可以进行存储消息,记录消息的已读状态。也可自行扩展,当作消息队列的基础。或者也可以用做记录,管理员之间的留言。 Service说明 1、创建单一消息 /** * @param $title 消息标题 * @param $content 消息内容 * @param $receiver 接收者(例如管理员id) * @re
-
2 核心技术
Docker 核心技术 Docker核心是一个操作系统级虚拟化方法, 理解起来可能并不像VM那样直观。我们从虚拟化方法的四个方面: 隔离性 Namespace 可配额/可度量 Cgroups 便携性 AUFS 安全性 AppArmor、SELinux、GRSEC 接下来将详细介绍Docker的技术细节。