《阿里本地生活》专题
-
 阿里版ChatGPT通义千问:突然上线邀测
阿里版ChatGPT通义千问:突然上线邀测阿里版ChatGPT通义千问:突然上线邀测
-
 阿里设计师作品集要点+面试问题
阿里设计师作品集要点+面试问题PART 1. 如何准备作品集 决定我们能否得到面试机会的,不是漂亮的简历,而是作品集的质量。但既然要应聘面试,就要做好充分准备。一方面是体现你做事的态度,另一方面也是个机会,让自己梳理一下经历过的项目。 01 | 作品集需要包含几个项目? 作品不在于多,而在于精,3-4个项目即可。每个项目从需求分析到调研(包含市场和用户)、初步想法、初步方案、测试、优化、最终方案、商业结果、复盘未来规划等都需要
-
 阿里设计师最常问的6个面试题
阿里设计师最常问的6个面试题1.解释一下UI、交互、UX 这个问题是一个很普遍的问题,很多面试官都会问到,为什么会问这个问题,因为想了解你对于行业是否了解,是否掌握了一些用户体验基础知识。这个问题你也不要随便给出一个百度能查到的答案,这里给大家一些回答方向。 UI和UX大家本质都是在解决用户问题,只不过站位不同视角不同,UI更多是解决用户第一印象,这个设计好不好看,交互逻辑合理不合理,结构清晰不清晰,页面功能层次表达是否
-
 阿里运营暑期实习非典型面经1
阿里运营暑期实习非典型面经1#运营人求职交流聚集地# 之所以叫非典型,是因为我投的事业群还组织了群面hh 但据我了解,群面并不是阿里校招的常规环节,所以还是要重申——具体面试环节及考察方式看BU!(听说有BU没做笔试就开始面试也不是没有) 群面题目是个比较大的case,一段背景描述+几个小问题。整体比较general友好型的题目,基本每个人都能有话可说的那种,专业生疏知识比较少。 我们场大概10人左右,现场分两小组分别讨论最
-
 阿里巴巴 行业运营 实习一面面经
阿里巴巴 行业运营 实习一面面经面试内容 简历细挖:针对各项经历提问,主要为以下方向 过往实习的工作内容、过往项目的主要工作 实习的收获 团队合作中负责哪部分工作 项目的具体idea从哪里来,为什么提这样的方案 对一些具体概念的理解 行为面:问题偏personal,部分类似宝洁八大问 觉得之前的商赛最满意哪一段?为什么? 讲一件坚持很久的事 有没有被建议/批评的经历 为什么投递这个岗位 关于个性特点、工作内容偏好的提问 反问&业
-
 阿里巴巴 行业运营 实习二面面经
阿里巴巴 行业运营 实习二面面经没有遇到业务场景题,更多的还是针对过往实习/项目经历的提问,不同部门面试风格差异蛮大的。 1. 你在过往的项目经历里有哪些可以体现快速学习能力的? 2. 在这段商赛遇到的困难有哪些? 3. 觉得印象最深的一段实习是什么?有哪些收获? 4. 在这段实习中遇到的困难是什么? 5. 这段实习中团队管理遇到的困难有哪些? 6. 还有其他的吗? 7. 几段实习最满意的是哪一段?最不满意的是哪一段?为什么?
-
 阿里巴巴秋招用户运营一面面经
阿里巴巴秋招用户运营一面面经被阿里捞的时候我都懵了,因为大概是他刚开秋招的时候我就投了,但是一直没有后续,我都快忘了。 这里与各位牛友们分享一下面试的问题: 1.自我介绍 2.你觉得你的优缺点是什么,他们分别对你的工作产生了什么影响 3.当你接到一项工作任务时,你是如何处理的 4.你做过最有挑战性的事情 5.你做过坚持最久的事情 6.如何看待工作中那些比较dirty的工作 7.讲述你带领团队体现你领导力的一件事情 8.你周围
-
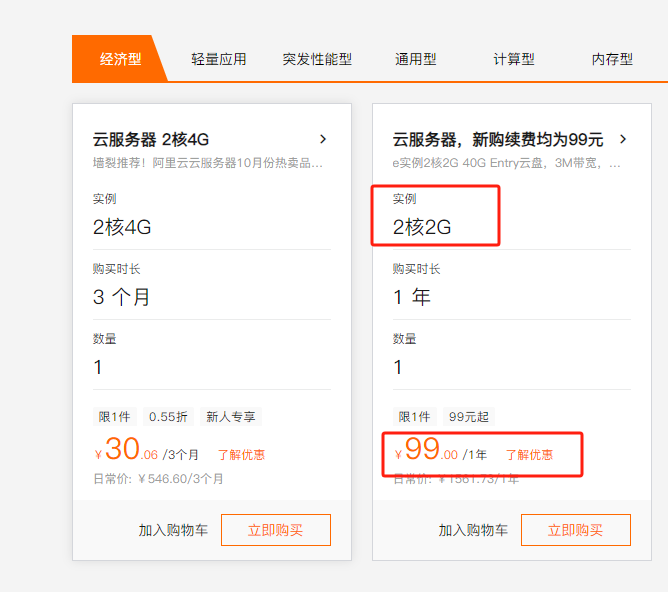 阿里云的这些服务器有什么区别?
阿里云的这些服务器有什么区别?想开一个服务器自己个人用,放一些自己的博客和给客户做的一些企业展示网站。 但这经济型和轻量应用,我看配置也差不多,但价格差的还不小,这具体是差在哪里?我应该怎么选 ?
-
Python-如何在Django中管理本地和生产设置?
问题内容: 建议处理本地开发和生产服务器设置的建议方式是什么?它们中的某些(例如常量等)可以在两者中进行更改/访问,但是其中一些(例如静态文件的路径)需要保持不同,因此,每次部署新代码时都不应覆盖它们。 当前,我将所有常量添加到中。但是每次我在本地更改某些常量时,都必须将其复制到生产服务器并编辑文件以进行生产特定更改… :( 编辑:这个问题似乎没有标准答案,我已经接受了最受欢迎的方法。 问题答案:
-
本地路径不存在... apk文件未生成[重复]
当我在我连接的设备上运行应用程序时,选择设备后显示意外错误,本地路径不存在。
-
如何在JPA2/Hibernate中生成可移植的本地ID?
我希望在我的JPA2实体上有本机和可移植的id生成,目前运行Hibernate和MySQL 当使用@generatedvalue(strategy=auto)时,hibernate默认为MySQL上的“hibernate_sequence”表,我想要标识 当@generatedvalue strategy=auto时,如何将Hibernate设置为使用标识作为mysql的默认值?
-
快速部署一个云原生本地实验环境
本文旨在帮助您快速部署一个云原生本地实验环境,让您可以基本不需要任何Kubernetes和云原生技术的基础就可以对云原生环境一探究竟。 本文中使用kubernetes-vagrant-centos-cluster在本地使用 Vagrant 启动三个虚拟机部署分布式的Kubernetes集群。 如仅需要体验云原生环境和测试服务功能,可以使用更加轻量级的cloud-native-sandbox,通过个
-
用于Jenkins /本地构建的PyPI本地缓存
问题内容: 我有一个Jenkins实例,该实例使用从requirements.txt中附带的PyPI包来构建我的项目。但是,与TravisCI构建一样,每次从头开始构建都非常耗时,并且意味着构建要花费> 4-5分钟,这比理想情况要慢得多。 我正在寻找的是一种在本地缓存下载的软件包的方法,因此,当启动具有相同依赖项的构建时,不必从PyPI获取它就可以在本地获取,而当版本发生更改时,它可以获取上游软件
-
无法从本地HTML页面Ajax本地文件
问题内容: 根据Same OriginPolicy,SOP不应应用于file://协议,但是为什么我的代码不起作用?我正在从本地系统运行此测试页面,并且与html页面位于同一目录中。如果我将URL更改为http://www.google.com/,它也无法正常工作。我不明白为什么,有人可以解释吗? 编辑: 控制台打印如下: XMLHttpRequest无法加载文件:/// C:/Users/yc/
-
SaaS本地数据存储(和本地运行时)
如果我不在合适的StackExchange论坛,请建议我在哪里提问: 我在一家公司工作,他编写了处理敏感数据的软件。为了防止软件被复制(软件盗版),很久以前就决定使用许可证制度。 这个系统运行良好,但对我的公司和客户来说都是一个很大的负担,因此我正在寻找其他方法。 我发现的一种方法是SaaS,但我看到了一个巨大的缺点:Saas在互联网上工作,这意味着本地数据被上传到云上(因此是互联网),这让客户感