《牧原股份》专题
-
 请你说明一下ConcurrentHashMap的原理?
请你说明一下ConcurrentHashMap的原理?本文向大家介绍请你说明一下ConcurrentHashMap的原理?相关面试题,主要包含被问及请你说明一下ConcurrentHashMap的原理?时的应答技巧和注意事项,需要的朋友参考一下 考察点:JAVA内存模型 ConcurrentHashMap 类中包含两个静态内部类 HashEntry 和 Segment。HashEntry 用来封装映射表的键 / 值对;Segment 用来充当锁的角色
-
码头交叉原产地过滤器
问题内容: 我已经配置了Jetty的跨原点过滤器,但是我继续收到以下错误。有谁知道哪里出了问题以及如何解决?错误消息下方是我的替代描述符(即补充web.xml) 错误: 覆盖描述符: 请求标题 响应头 问题答案: 阿罗哈 我也为此战斗了一段时间,发现最终节点需要为: 不 这是我发现对我有帮助的链接:wiki.eclipse.org/Jetty/Feature/Cross_Origin_Filter
-
规避原产地政策的方法
问题内容: 同一原产地政策 我想制作有关HTML / JS 同源策略的社区Wiki,以希望能帮助任何人搜索此主题。这是关于SO的最热门搜索主题之一,并且没有统一的Wiki,所以我在这里:) 相同的来源策略可防止从一个来源加载的文档或脚本从另一个来源获取或设置文档的属性。该策略可以追溯到Netscape Navigator 2.0。 您采用哪种最喜欢的方式处理同源政策? 请保持详细示例,并最好也链接
-
向JavaScript对象文字添加原型
问题内容: STORE = { item : function() { } }; STORE.item.prototype.add = function() { alert(‘test 123’); }; STORE.item.add(); 一段时间以来,我一直在试图找出问题所在。为什么不起作用?但是,当我使用以下命令时,它可以工作: 问题答案: 原型对象应在构造函数上使用,基本上是将使用new运
-
使用JavaScript原型的调用方法
问题内容: 如果重写了JavaScript中的原型方法,则可以调用该基础方法吗? 问题答案: 我不明白您到底想做什么,但是通常按照以下方式完成特定于对象的行为:
-
价值,原型和特性的差异
问题内容: 好!首先,这个问题来自于一个在jQuery宇宙中挖得太深(很可能迷路)的人。 在我的研究中,我发现了jquery的主要模式是这样的(如果需要的话,欢迎改正): 当启动时,启动并返回一个元素数组。但我不明白它是如何增加了jQuery的方法类似或等。到这个数组。 我得到了静态方法。但是用所有这些方法都无法获得返回值和元素数组的方式。 问题答案: 我也不喜欢这种模式。他们有一个函数,它是所有
-
Java:说一下 session 的工作原理?
当客户端登录完成后,会在服务端产生一个session,此时服务端会将sessionid返回给客户端浏览器。客户端将sessionid储存在浏览器的cookie中,当用户再次登录时,会获得对应的sessionid,然后将sessionid发送到服务端请求登录,服务端在内存中找到对应的sessionid,完成登录,如果找不到,返回登录页面。
-
Java:Synchronized 用过吗,其原理是什么?
(1)可重入性 synchronized的锁对象中有一个计数器(recursions变量)会记录线程获得几次锁; 可重入的好处: 可以避免死锁; 可以让我们更好的封装代码; synchronized是可重入锁,每部锁对象会有一个计数器记录线程获取几次锁,在执行完同步代码块时,计数器的数量会-1,直到计数器的数量为0,就释放这个锁。 (2)不可中断性 一个线程获得锁后,另一个线程想要获得锁,必须处于
-
Java:说一下 HashSet 的实现原理?
HashSet实际上是一个HashMap实例,数据存储结构都是数组+链表。 HashSet是基于HashMap实现的,HashSet中的元素都存放在HashMap的key上面,而value都是一个统一的对象PRESENT。 private static final Object PRESENT = new Object(); HashSet中add方法调用的是底层HashMap中的put方法,pu
-
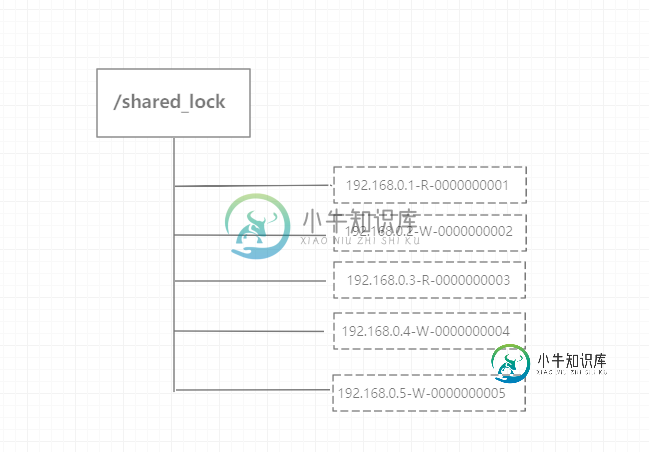 14.0 Zookeeper 分布式锁实现原理
14.0 Zookeeper 分布式锁实现原理主要内容:实例分布式锁是控制分布式系统之间同步访问共享资源的一种方式。 下面介绍 zookeeper 如何实现分布式锁,讲解排他锁和共享锁两类分布式锁。 排他锁 排他锁(Exclusive Locks),又被称为写锁或独占锁,如果事务T1对数据对象O1加上排他锁,那么整个加锁期间,只允许事务T1对O1进行读取和更新操作,其他任何事务都不能进行读或写。 定义锁: 实现方式: 利用 zookeeper 的同级节点的
-
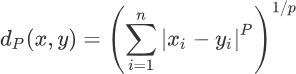 K-means聚类算法原理解析
K-means聚类算法原理解析主要内容:度量最小距离,总结通过《 什么是Kmeans聚类算法》一节的学习,我们了解了 K-means 聚类算法的聚类过程,其实就是不断寻找簇的质心的过程,该过程从随机设定 K 个质心开始,直到找到 K 个最合适的质心为止。本节我们透过算法流程直击算法的本质,帮助您彻底理解 K-means 算法。 度量最小距离 对于 K-means 聚类算法而言,找到质心是一项既核心又重要的任务,找到质心才可以划分出距离质心最近样本点。从数
-
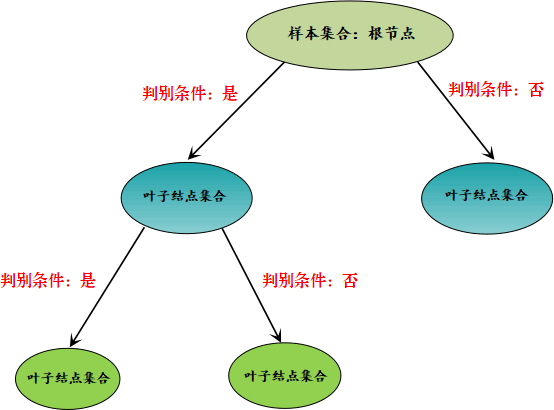 决策树算法和剪枝原理
决策树算法和剪枝原理主要内容:决策树算法原理,决策树剪枝策略本节我们对决策算法原理做简单的解析,帮助您理清算法思路,温故而知新。 我们知道,决策树算法是一种树形分类结构,要通过这棵树实现样本分类,就要根据 if -else 原理设置判别条件。因此您可以这样理解,决策树是由许多 if -else 分枝组合而成的树形模型。 决策树算法原理 决策树特征属性是 if -else 判别条件的关键所在,我们可以把这些特征属性看成一个 集合,我们要选择的判别条件都来自于
-
函数声明以及函数原型
主要内容:函数参考手册C语言代码由上到下依次执行,原则上函数定义要出现在函数调用之前,否则就会报错。但在实际开发中,经常会在函数定义之前使用它们,这个时候就需要提前声明。 所谓 声明(Declaration) ,就是告诉编译器我要使用这个函数,你现在没有找到它的定义不要紧,请不要报错,稍后我会把定义补上。 函数声明的格式非常简单,相当于去掉函数定义中的函数体,并在最后加上分号 ,如下所示: dataType func
-
Java误认为原始数据类型?
问题:我无法存储号码“600851475143”。我意识到这个数字比int所能容纳的要大,比最大long值要小。然而,我的程序没有把变量“number”注册成一个long,而是注册成一个int。有人能解释一下这个问题吗? **-问题线 } 解决方案:正如吉姆在下面所说,为了长型,必须在数字末尾加上“L”或“L”。“如果整数文字以字母L或L结尾,则为long类型;否则为int类型。建议使用大写字母L
-
Spring数据中的通用原油 jpa
我有很多表,几乎所有表我都可以保存或删除它们而无需其他查询。 所以我使用如下所示: 但是我必须创建大约 50 个界面,这太多了!! 没有一种通用的方法可以在Spring数据中使用标准查询CRUD,或者以其他方式使用?