《中望软件》专题
-
无法在docker Ubuntu映像中安装软件包
如何修复这个错误?
-
在颤振中使用平台专用软件包
我不确定这是否是合适的堆栈交换站点,但我认为它比我能想到的其他站点更适合这里。无论如何,我为一个移动应用程序开发团队工作,我们正在考虑使用Flutter来开发我们未来的移动应用程序,因为它减少了为iOS和Android开发时所需的工作量(我们只是一个小团队)。 我通读了一些关于Flutter的信息,并检查了可用的软件包和Dart /Flutter Pub,还有一些软件包尚未可用于我们用于Andro
-
 中科曙光(嵌入式软件开发面经)
中科曙光(嵌入式软件开发面经) -
 中兴秋招嵌入式软件一面面经
中兴秋招嵌入式软件一面面经岗位:软件开发工程师(深圳) 1、自我介绍 2、成绩排名 3、实习情况 4、介绍项目 5、图像处理部分用了什么工具和算法? 6、介绍论文情况 7、编程语言会哪些? 8、linux熟不熟悉? 9、网络通信的知识了解吗?TCP/IP之类的? 10、无线通信协议了解吗?3/4/5G这些? 11、深度学习有搞过吗?YOLO目标检测之类的? 12、独生子女? 13、目标工作城市 14、有无女朋友? 反问:
-
 中兴软件测试工程师面试记录
中兴软件测试工程师面试记录渠道 1.项目里的webbench压力测试 并发连接展开讲讲 2.登录,注册假如要测试会怎么测 3.struct和类的区别 4.浅拷贝和深拷贝的区别 5.tdma和cdma区别 6.测试设计方法 7.排名 8.为什么选择测试工程师,怎么接触到的 9.第一选择西安第二选择是上海,是可以去上海吗 10.能否接受出差,国内,国际。 反问: 1.面试结果什么时候出 2.测试工程师的上升渠道
-
 南京中科软件研究所 测开(已拒)
南京中科软件研究所 测开(已拒)7.29 面试 自我介绍 巴拉巴拉 对linux熟悉吗?说一下linux查看日志的命令? 不太懂 ,但知道别的 pwd cd ls -l makedir cat more ifconfig rm which touch 等 计网了解吗? 说一下 你的项目主要是怎么设计的?有什么作用? 下午四点 面试完就发了offer 待遇偏低 但是感觉还行 反问 主要做的是什么? 说是服务器相关的工作 7.30
-
 中兴线下一二面软件开发面经
中兴线下一二面软件开发面经base南京 深信服寄了,立马打车到中兴 本人bg:专科-双一流本-南邮硕 0924下午一面40min: 自我介绍 面试官看我专科,问了好一会 发表的sci论文讲讲,和硕士研究方向相关吗 实习经历深入拷打,问的很细 八股: static用法 public protected private 区别 构造器能重写吗 能重载吗 mysql索引 项目中数据怎么存的 最后问了我硕士是全日制吗,我说专升本确实
-
休眠@ManyToMany双向渴望获取
问题内容: 我有一个我认为应该很普遍的问题,但找不到答案。 我有2个对象:组和用户。我的课程如下所示: 现在,当我尝试从数据库中获取用户时,它带来了所有组,所有组都带来了所有用户,依此类推。最后,我遇到了stackoverflow异常。 如何解决此问题,并且仍然具有双向关联以及到达列表中对象的能力? 问题答案: 如果使用属性(无论如何都应使用)将双向关联的一侧设为关联的 拥有 侧,是否会遇到相同的
-
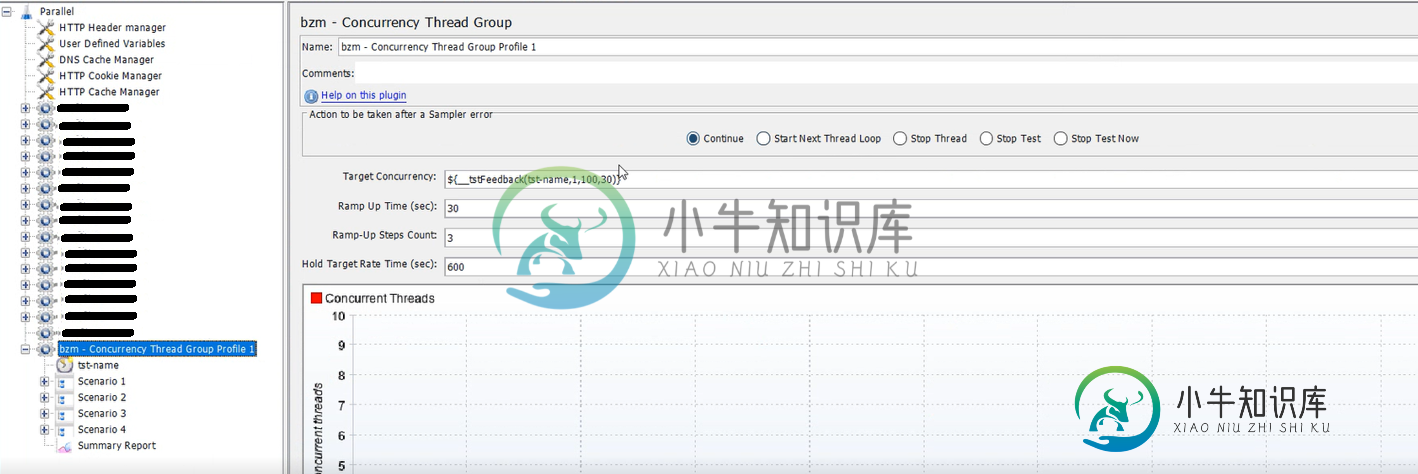 用jmeter模拟期望吞吐量
用jmeter模拟期望吞吐量我希望达到每秒7.6个请求的吞吐量。我使用的是bzm-并发线程组,具有反馈功能和吞吐量成形计时器,如下所示。请忽略删除的线程组。它们被禁用,不由Jmeter执行。 当我从命令行运行脚本时,它显示的日志如下 在日志文件中,它提到: 在并发线程组中,我将带有反馈函数的目标并发定义为${{uu tstFeedback(tst name,1100,30)} 这里,1和100是开始线程和允许的最大线程数,3
-
 卓望数码 java 一面、二面
卓望数码 java 一面、二面9.29一面 面试邀请说要准备身份证,但实际上都没用到。只面了15min,我太菜了啥也不会。 1.StringBuffer和StringBuilder的区别(底层实现) 2.HashMap和HashTable的区别,能不能为空 3.单例模式解决什么问题?线程安全吗? 4.创建线程的几种方法 5.sleep()和wait()的差别 6.JDK线程池有什
-
 卓望数码java一面凉经
卓望数码java一面凉经面试官人挺好一直说没事。面试时间大概有30分钟左右,问的大部分都是八股文内容,但国庆假期一过都忘了 1. 介绍JVM线程私有、共有区域,垃圾回收,对象引用算法; 2. GC调优思路,如何查看JVM垃圾回收次数、内存大小? 2. java集合:ArrayList和LinkedList底层数据结构、效率对比、用途,ArrayList扩容机制; 3. 如何创建线程?Callable和Runnable的区
-
 卓望数码Java后端一面
卓望数码Java后端一面10.13 一面凉经 提前准备身份证 ,我提前进去的,然后就直接开始了。 整体大概30多分钟(这个面试官 有些口音的感觉 难懂) 首先自我介绍,然后说看我项目用的springboot,问我了解springcloud吗 然后开始问问题(顺序记不清了 记不全啦) 1、ArrayList和LinkList区别? 2、ArrayList扩容机制 3、创建线程的方法? Runnable和Callable的
-
 卓望数码c++开发面经
卓望数码c++开发面经自我介绍 1.类里面默认的函数 2.构造函数能不能是虚函数,为什么 3.指针和引用区别 4.c++特性 5.继承和重写 6.select和echo 7.指针数组和数组指针的书写 8.二维数组按行遍历和按列遍历效率 9.多个人围成一圈 10.单链表中心节点 11.结构体和类的区别 12.数组越界没有占用其他内存空间对其他线程会不会有影响 13.内存泄漏后进程结束后对系统的危害
-
SQLAlchemy渴望加载多个关系
问题内容: SQLAlchemy支持渴望加载关系,这基本上是一条语句。但是,如果模型具有两个或多个关系,则可能是非常庞大的联接。例如, 该查询的性能实在是太差了,因为中和会产生一个巨大的表。但是和在这里没有关系,因此它们不应该是。它应该是两个分开的查询。并且由于会话具有某种程度的缓存,因此我将查询更改为此。 这次的性能要好得多。但是,我不认为这样做是正确的。我不确定会话结束时标签缓存是否会过期。
-
OpenNLP产生不期望的结果
我正在使用OpenNLP处理诸如“在洛杉矶工作的医生”和“住在好莱坞并在圣莫尼卡工作的女性”之类的查询。对于理解人类的英语来说,这些句子很明显,主题是“医生”和“女性”。然而,当我使用opennlp时,它将句子标记为 [女性生活][好莱坞] 这是另一个句子“住在圣莫尼卡、在马里布工作和踢足球的人”被处理为 为什么OpenNLP的POS标记器错误地标记了它们?这些句子有最简单的语法结构。如果最先进的