《宽德投资》专题
-
具有可比接口和通用列表的未检定投放警告
当我使用带有通用或参数化列表的可比接口时,我会收到一个未选中的强制转换警告。我可以使用ObjectList进行比较,但不能使用通用列表。这是我的开发,首先使用ObjectList,然后使用通用列表。 下面是我的ListNode类定义的一个片段: 和我的ObjectList类定义的片段: 我的可比界面: 我的ObjectList类中有一个方法,可以将对象参数与ListNode中的对象进行比较,没有问
-
 秋招总结 投递记录 - 笔试挂篇(含部分笔试真题)
秋招总结 投递记录 - 笔试挂篇(含部分笔试真题)主投岗位/技术栈:java后端 bg:中9本计算机类,lc总计70 笔试挂x≈30 大疆 7.6-8.9 7.10投 后端开发工程师(互联网事业部-深圳) 7.19测评:80min 85题(工作场景抉择、性格测评、数学推理、图形推理、数字推理)(顺序不定) 8.6笔试 赛码 90min 大疆创新2024校招互联网事业部岗A卷 单选x10 多选x3(前端、java、http、正则)、sqlx1、编程
-
前端 - 有比较推荐的Android 与 iOS 投屏软件SDK推荐吗?
有比较推荐的Android 与 iOS 投屏软件SDK推荐吗?最好是能支持与车机对接的。
-
前端 - 使用shapefile-js读取zip包出现投影坐标系问题?
无法解析shapefile zip code: error: PROJCS["CGCS2000_3_Degree_GK_CM_123E",GEOGCS["GCS_China_Geodetic_Coordinate_System_2000",DATUM["D_China_2000",SPHEROID["CGCS2000",6378137.0,298.257222101]],PRIMEM["Green
-
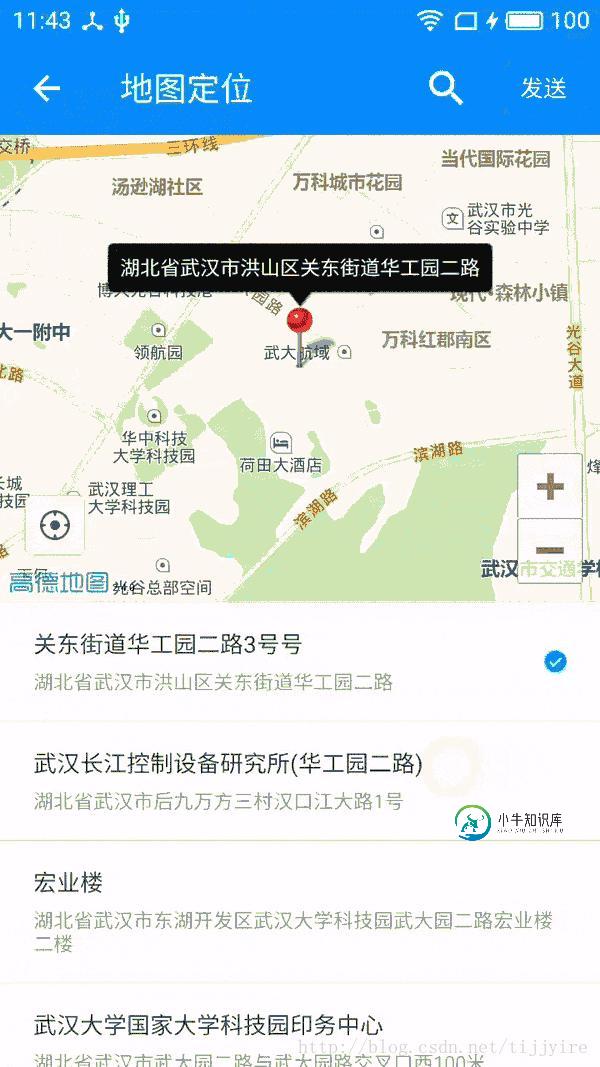 Android高德地图poi检索仿微信发送位置实例代码
Android高德地图poi检索仿微信发送位置实例代码本文向大家介绍Android高德地图poi检索仿微信发送位置实例代码,包括了Android高德地图poi检索仿微信发送位置实例代码的使用技巧和注意事项,需要的朋友参考一下 最近项目需求把发送定位模块改成类似微信发送位置给好友的效果,我使用了高德地图实现了一个demo,效果图如下: 从主界面中我们可以看到中心标记上面显示的就是我们定位的地址,下面是一个listview列表,第一条item的数据就是我
-
无法加载驱动程序类组织。马里亚德。jdbc。驾驶员
我想在Spring Boot中配置2个JNDI数据源。我尝试了这个配置: application.properties 主要数据源配置: 第二个数据源配置: 但是我在部署过程中收到错误: 我正在使用部署到Wildfly服务器的Spring Boot战mariadb-java-client-2.4.2.jar.当我使用单个数据源配置时,它工作正常。但是对于第二个数据源,我得到了异常。 你知道我如何解
-
无法解析类com。云蜂。哈德逊。插件。文件夹文件夹
我试图使用groovy脚本从jenkins收集数据并收到错误: 无法解析类com。云蜂。哈德逊。插件。文件夹文件夹 下面是代码: 错误是: rg.codehaus.groovy.control.MultipleCompilationErrorsExceptio n:启动失败: Script1.groovy: 12:无法解析类com.cloudbees.hudson.plugins.folder.文
-
如何解决构建中不同版本库的错误。格拉德尔?
我正在开发Android,并尝试实现GPS和谷歌地图。 构建。gradle(模块:app)如下所示 但它在编译com时显示了错误。Android支持:appcompat-v7:26' 。错误是 但是我在构建中没有看到任何版本25。gradle。我错过什么了吗?提前谢谢。
-
使用相同的GLTF模型两次在反应-三纤维/德瑞/Three.js
在这个最小反应三光纤应用程序中,我尝试加载并包含相同的GLTF型号两次: 看到这个代码沙盒了吗 然而只有第二个
-
Windows上Node.js+ibm_db+DB2 LUW 9.7的代码页问题(例如德文元音)
我们可以使用npm包IBM_DB从Widows客户端上的node.js成功访问IBM DB2 LUW Server9.7。 但是在ibm_db SQL查询的结果集中的chacarter编码确实存在问题。JavaScripte结果集中的数据在涉及德语元数时已经出现了错误。 我们还检查了数据库中的SQL列字符集: 给出结果1252。 其他徒劳的尝试: null Windows 10 node.js 1
-
我不能理解曼德布罗特分形代码的一些东西
这是计算功能代码。我听说“逃跑”应该是。因为如果()小于,它就不会无限大。但是在这个代码中,转义是。为什么?为什么?
-
朱莉娅·塞特和曼德尔布罗特·塞特是什么关系?
我写了一个mandelbrot集,我读过关于julia集的文章,它非常相似,但到底是什么关系呢?我能用mandelbrot公式画一个julia集吗?起始参数是什么?请阅读我的mandelbrot集合代码: 我不确定mandelbrot集对于z是迭代的,julia集对于c是迭代的,这意味着什么?我需要更改代码吗? 更新:我更改了代码,但它不起作用。我的想法是从$re和$im开始,而不是从0开始: 更
-
卡桑德拉安装在窗口 10 上,无法连接到服务器
我已经在Windows 10上安装了“数据斯塔克斯-ddc-64位-3.9.0.msi”,当我运行卡桑德拉CQL外壳时,我得到了这个错误。 连接错误:('无法连接到任何服务器',{'127.0.0.1':错误(10061,"尝试连接到[('127.0.0.1',9042)]。最后一个错误:无法进行连接,因为目标机器主动拒绝它")})
-
卡桑德拉:对时间序列数据时间戳的范围查询
我正在尝试评估Cassandra DB在存储和检索不同通道的时间序列数据方面的性能。 数据以文件格式记录,最大记录速率为8个样本/秒,每个样本都有一个以毫秒为单位的时间戳。给定时间记录的通道数可能会有所不同。 受以下链接的启发,我使用时间序列数据建模入门创建了以下表: 创建表uhhdata ( ch_idx int,date timestamp,dt timestamp,val float,PRI
-
时间序列数据的卡桑德拉:如何调整分区大小?
我正在尝试使用Cassandra来存储来自一些传感器的数据。我读了很多关于Cassandra的时间序列数据模型的文章。我从时间序列数据建模入门开始,“时间序列模式2”看起来是最好的方法。所以我创建了一个复制因子为2的键空间和一个这样的表 其中是唯一的设备ID,是一天(例如2017-08-30),是时间戳。 我的查询是 如您所见,我需要从多天中检索数据,这意味着在我的集群中读取多个分区。在我看来,查