《电信天翼云计算》专题
-
计算时差
问题内容: 在我的程序开始和结束时, 但是,当我尝试区别时,我会遇到语法错误…。我做错了一些事情,但是我不确定发生了什么… 基本上,我只想在程序开始时将时间存储在变量中,然后将第二次时间存储在末尾的第二个变量中,然后在程序的最后一位中计算差并显示出来。我不是要为功能速度计时。我正在尝试记录用户通过某些菜单花费的时间。做这个的最好方式是什么? 问题答案: 该模块将为您完成所有工作: 如果您不想显示微
-
计算时间
我正试图在RoR上创建一个计算时间的应用程序。 当您按下开始按钮时,它会拉Time.now,然后,当您按下停止时,它会再次拉Time.now,然后计算两者之间的时间量。然后它会通过to_i将给定的秒转换为整数,然后将整数秒计算为小时:分钟:秒 然而,我的代码出了点问题,它不停地抛出一个又一个错误。 当前顺序为 nil:NilClass 的“未定义方法 '-'”
-
 矩阵计算
矩阵计算我有一个矩阵。只有唯一的颜色以不同的权重重复它们自己。从它们中,我得选择一半,另一半必须用从第一个中最接近的元素替换。 我想到了在图像中循环,并搜索最近的颜色为当前的一个。找到后,我把一个换成另一个。 但我有3个循环、、。前两个I循环通过RGB矩阵,第三个用于循环到包含最终颜色的矩阵。这需要一些时间来计算。 可以做些什么来加快它的速度? 循环如下所示: 表示选择为最终颜色的半色。 我可以考虑一些小
-
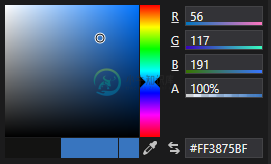 计算RGB值
计算RGB值我目前正在编码一个colorpicker并尝试创建一个函数,它需要3个介于0和255(RGB)之间的整数。 如果你看上面链接的图像,你可以看到在中心有一个彩虹-渐变。上面的所有RGB值至少包含一个0和一个255的整数。另一个可以是0到255之间的任何值。然后在图像的左边有一个正方形,它包含这个“彩虹颜色”的所有“子颜色”的渐变。 函数应该取这个子颜色的RGB值(例如,R=112,G=158,B=7
-
CRC16-CCITT计算
这是代码 更新的答案
-
计算余数
要求定义一个int型数组a,包含100个元素,保存100个随机的4位数。再定义一个int型数组b,包含10个元素。统计a数组中的元素对10求余等于0的个数,保存到b[0]中;对10求余等于1的个数,保存到b[1]中,……依此类推。 解决(python) #!/usr/bin/env python #coding:utf-8 import random if __name__=="__main__"
-
1.4.15.6 计算列
注意 当前章节中涉及的配置一般适用于关系数据库。这里展示的扩展方法在你安装了关系数据库提供程序之后就能获得(由Microsoft.EntityFrmeworkCore.Relational 程序包共享)。 计算列是值其值是在数据库中被计算出来的列。计算列可以利用数据表中的其他列来计算它的值。 惯例 按照惯例不会在模型中创建计算列。 数据注解 不能使用数据注解来配置计算列。 流式 API 可以使用流
-
数值计算
机器学习通常需要大量的数值计算。通过迭代更新估计的过程来解决数学问题,而不去求得一个公式化的结果。通常的操作包括优化和求解线性方程系统。对于采用有限的记忆储存的不能精确表述的问题,即使是估计在数值计算机上估计一个函数方程的2解都是很困难的。(注,MNIST,Mixed National Institute of Standards and Technology database,国家标准与技术研究
-
类型计算
在这一点上,如果你有兴趣像MPL一样进行类型计算,你可能会想知道Hana如何帮助你。不用担心,Hana提供了一种通过将类型表示为值来执行具有大量表达性的类型计算的方法,就像我们将编译时数字表示为值一样。 这是一种全新的接触元编程的方法,如果你想熟练使用Hana,你应该尝试将你的旧MPL习惯放在一边。 但是,请注意,现代C++的功能,如自动推导返回类型,在许多情况下不需要类型计算。 因此,在考虑做一
-
边缘计算
TBD 参考 The Birth of an Edge Orchestrator – Cloudify Meets Edge Computing K8s(Kubernetes) and SDN for Multi-access Edge Computing deployment
-
多GPU计算
本节中我们将展示如何使用多块GPU计算,例如,使用多块GPU训练同一个模型。正如所期望的那样,运行本节中的程序需要至少2块GPU。事实上,一台机器上安装多块GPU很常见,这是因为主板上通常会有多个PCIe插槽。如果正确安装了NVIDIA驱动,我们可以通过nvidia-smi命令来查看当前计算机上的全部GPU。 !nvidia-smi “自动并行计算”一节介绍过,大部分运算可以使用所有的CPU的全部
-
异步计算
MXNet使用异步计算来提升计算性能。理解它的工作原理既有助于开发更高效的程序,又有助于在内存资源有限的情况下主动降低计算性能从而减小内存开销。我们先导入本节中实验需要的包或模块。 from mxnet import autograd, gluon, nd from mxnet.gluon import loss as gloss, nn import os import subproces
-
计算节点
计算节点 需要额外启用 l3_agent(dvr 模式),以及 metadata agent。 其实,跟传统情况下的网络节点十分类似。每个东西向路由器有自己的命名空间,负责跨子网的转发。另外,多一个 floating 路由器,专门负责经由 floating 地址的南北向转发。 东西流量 如上图所示,租户两个子网,红色和绿色,分别有 vm1 和 vm2,位于节点 cn1 和 cn2 上。 vm1 访
-
计算节点
计算节点 主要包括两个网桥:集成网桥 br-int 和 隧道网桥 br-tun。 $ sudo ovs-vsctl show225f3eb5-6059-4063-99c3-8666915c9c55 Bridge br-int fail_mode: secure Port br-int Interface br-int
-
计算节点
计算节点 查看网桥信息,主要包括两个网桥:br-int和br-eth1: [root@Compute ~]# ovs-vsctl showf758a8b8-2fd0-4a47-ab2d-c49d48304f82 Bridge "br-eth1" Port "phy-br-eth1" Interface "phy-br-eth1" Port "