《总结和分享》专题
-
 Django自定义分页与bootstrap分页结合
Django自定义分页与bootstrap分页结合本文向大家介绍Django自定义分页与bootstrap分页结合,包括了Django自定义分页与bootstrap分页结合的使用技巧和注意事项,需要的朋友参考一下 django中有自带的分页模块Paginator,想Paginator提供对象的列表,就可以提供每一页上对象的方法。 这里的话不讲解Paginator,而是自定义一个分页类来完成需求: 利用bootstrap的css,生成好看的html
-
分支目标预测结合分支预测?
编辑:我的困惑出现了,因为通过预测哪个分支,你肯定也在有效地进行目标预测?? 这个问题与我关于这个主题的第一个问题有内在联系: 分支预测与分支目标预测 无限循环 语句 或语句 语句的“then”子句结尾(跳过子句) 非虚函数调用 从函数返回 虚函数调用 函数指针调用 语句(如果编译为跳转表) 语句 语句(如果编译成一系列语句) 循环条件测试 和运算符 三元运算符 null 如果我有以下代码: (B
-
应用group_by和总结(sum),但保留包含不相关冲突数据的列?
我的问题非常类似于在保留所有列信息的同时对数据应用group_by和摘要,但我想保留被排除的列,因为它们在分组后发生冲突。 到这里为止,我得到了我想要的。现在我想包含列类型,尽管它被排除在外,因为值是冲突的。这是我想得到的结果 我已经尝试了< code>ungroup()和一些< code>mutate和< code>unite的变体,但都无济于事,任何建议都将不胜感激
-
Elasticsearch字段上的总和和计数聚合
我是Elasticsearch的新手,我希望在Elasticsearch 5的字段上执行某些聚合。x索引。我有一个索引,其中包含带有字段(具有嵌套结构)和字段(具有嵌套结构)的文档。这些是动态映射的字段。以下是示例文档 文件2: DOC 3: 我想在langs字段上执行总和聚合,这样对于每个键(X/Y)和每种语言,我都可以获得索引中所有文档的总和。此外,我还想从docLang字段生成每种语言类型的
-
按日和小时获取数据的总和
下面是我所拥有的数据的一个例子。 我想做的是总结每小时文件的大小。
-
如何将枚举与分组和子分组层次结构/嵌套一起使用
问题内容: 我有一个“班级”,称为: 对于我的项目而言,它们所涉及的所有枚举都非常重要(因为这是类的构造函数中的一个参数)。 我如何使用层次结构/嵌套来实现以下目的: 一种测试an 是否属于A,B或C组的方法。例如,类似于或将是返回true的公共方法。 能够做同样的事情组的子组,和。例如,A组可能有子组,和。然后,我想要一个做某事的方法,例如which 。 一种无需所有复杂名称即可完成所有代码的方
-
使用Weka J48和朴素贝叶斯多项式分类器改进分类结果
我一直在使用Weka的J48和Naive Bayes多项式(NBM)分类器对RSS提要中的关键字频率进行分类,以将提要分类为目标类别。 例如,我的一个。arff文件包含以下数据提取: 以此类推:总共有570行,每行都包含一天的提要中关键字的频率。在这种情况下,10天内有57条feed,总共有570条记录需要分类。每个关键字都以代理项编号作为前缀,并以“频率”作为后缀。 我在“黑盒”的基础上对J48
-
Python-pandas与groupby占总数的百分比
问题内容: 这显然很简单,但是作为一个笨拙的新手,我陷入了困境。 我有一个包含3列的CSV文件,分别是该办公室的州,办公室ID和销售。 我想计算给定状态下每个办公室的销售百分比(每个州的所有百分比的总和为100%)。 返回: 我似乎无法弄清楚如何“高达”的水平与总起来对整个计算分数。 问题答案: 你将不得不创建第二个对象,但是你可以以一种更简单的方式来计算百分比-仅计算并将该列除以其和即可。复制P
-
测微计计数器与分布汇总
使用我将跟踪的请求大小的摘要 < li >请求总数 < li >总请求大小总计 < li >最大请求大小 我可以这样做 但是,我可以使用计数器和最大尺寸的量规来实现相同的效果 问题是,除了更短之外,总结比更长的解决方案有什么好处吗?
-
 人工智能结束分析
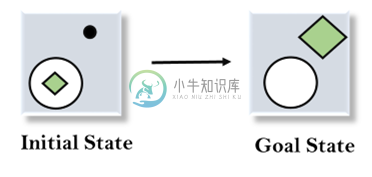
人工智能结束分析主要内容:手段结束分析的工作原理,运算符子目标,均值分析算法人工智能中的手段 - 结束分析 前面已经学习了向前或向后推理的策略,但是两个方向的混合适合于解决复杂和大的问题。这样一种混合策略,使得有可能首先解决问题的主要部分,然后回过头来解决在组合问题的大部分期间出现的小问题。这种技术称为手段 - 末端分析。 Means-Ends分析是人工智能中用于限制AI程序中搜索的问题解决技术。 它是向后和向前搜索技术的混合体。 MEA技术于1961年由Allen Ne
-
If语句结尾的分号
-
第三部分:数据结构
你正在以你的方式构建个人流程,它让你以有限的阻碍快速起步。拥有良好的起步流程,以及培养一种尽管去做的能力,就是创造力的基础。创造力是一种流动性和放松的心态。如果你的起步充满阻碍和沮丧,那么很难进入这个流程。学习“点击”你的大脑,使其进入具有创造力的、松散的 Hack 模式,可以帮助你使用创造力解决问题,并提高生产力。 如果你做的是垃圾,那就没有意义了。首先,是的,显然,你所做的绝大多数都是垃圾,但
-
第IV部分. 系统结构
目录 第11章 x86 汇编语言
-
查询结果的重打分
查询结果的重打分 有些应用场景中,对查询语句的结果文档进行重新打分是很有必要的。重新打分的原因可能会各不相同。其中的一个原因可能是出于性能的考虑,比如,对整个有序的结果集进行重排序开销会很大,通常就会只对结果集的子集进行处理。可以想象重打分在业务中应用会相当广泛。接下来了解一下这项功能,学习如何将它应用在业务中。 理解重打分 在ElasticSearch中,重打分是一个对限定数目的查询结果进行再次
-
InnoDB的内存结构分析
主要内容:一、基本的数据结构,二、Buffer Pool,三、Change Buffer,四、ADaptive Hash Index,五、Log Buffer,六、总结一、基本的数据结构 在InnoDB中,数据的分配和存储也有自己的数据结构,在前面分析过MySql中的内存管理,但是内存管理是有一个不断抽象的过程。在InnoDB中还会有一层自己的内存管理。在InnoDB引擎中的内存结构主要有四大类: 1、Buffer Pool 在MySql中,数据都是存储在磁盘中的,也就是说,从理论上讲,每次做S