《超聚变》专题
-
统计与聚合
统计 BuguDao提供如下常用的统计功能,它们都是基于Aggregation实现的。 /* 求最大值 */ public double max(String key) public double max(String key, BuguQuery query) /* 求最小值 */ public double min(String key) public double min(Stri
-
15.7. 聚集函数
HQL 查询甚至可以返回作用于属性之上的聚集函数的计算结果: select avg(cat.weight), sum(cat.weight), max(cat.weight), count(cat) from Cat cat 受支持的聚集函数如下: avg(...), sum(...), min(...), max(...) count(*) count(...), count(distinct
-
3.1.3 集群聚合
集群监控的本质是一个聚合功能。 单台机器的监控指标难以反应整个集群的情况,我们需要把整个集群的机器(体现为某个HostGroup下的机器)综合起来看。比如所有机器的qps加和才是整个集群的qps,所有机器的request_fail数量 ÷ 所有机器的request_total数量=整个集群的请求失败率。 我们计算出集群的某个整体指标之后,也会有“查看该指标的历史趋势图” “为该指标配置报警” 这种
-
网聚宝监控
在以前,我们发展工程还未服务化的时候,我们可能只单单关注单个请求的耗时等基本指标,对其作出优化或者业务上的调整,其内容往往也只是一人从顶到底,一人即可了解其中的逻辑层次。但随着服务化的到来以及业务逻辑愈来愈复杂,一个前端 web 层的请求需要调用很多服务才可以完成一次请求,当请求变的比较慢或者发生故障,我们很难看出是哪个服务或者哪台机器发生的问题,所以需要一个调用链的监控,来快速复现出完整的请求链
-
Focus聚焦社区
Focus聚焦社区是GoFrame社区项目,采用了简洁强大的GoFrame作为后端WEB框架, 由于前台系统需要SEO因此使用了GF自带template模板引擎,数据库用MySQL,前端使用jQuery/bootstrap框架。 一、源码地址 github:https://github.com/gogf/focus gitee:https://gitee.com/johng/focus 二、演示
-
超时
当我们所有数据库的 SQL 语句是通过子查询方式完成,对于超时的控制往往很容易被大家忽略。因为大家在代码里看不到任何调用 set_timeout 的地方。实际上 PostgreSQL 已经为我们预留好了两个设置。 请参考下面这段配置: location /postgres { internal; default_type text/html; set_by_lua_blo
-
超时
你是否正遇到网络或 CPU 的瓶颈? 验证客户端和托管redis-server的服务器上支持的最大带宽。如果有请求被带宽限制,则它们需要更长时间才能完成,从而可能导致超时。 同样,验证您没有在客户端或服务器框上获得CPU限制,这将导致请求等待CPU时间,从而超时。 有没有命令需要在 redis 服务器上处理很长时间? 可能有一些命令需要很长时间才能在redis服务器上处理,导致请求超时。 长时间
-
超时
套房级 套件级超时可应用于整个测试“套件”,或通过其禁用this.timeout(0)。这将由所有嵌套套件和不覆盖该值的测试用例继承。 describe('a suite of tests', function() { this.timeout(500); it('should take less than 500ms', function(done){ setTimeout(done, 30
-
ElasticSearch聚合:每个聚合排除一个过滤器
问题内容: 我想过滤出字段“ A”等于“ a”的文档,并且我想同时考虑字段“ A”,当然不包括先前的过滤器。我知道您可以将过滤器“置于查询之外”,以便在不应用该过滤器的情况下获得构面,例如: elasticsearch 单反 这非常好,但是如果我有多个滤镜和构面,每个滤镜和构面应该互相排斥,会发生什么?例: 也就是说,对于方面AI,希望保留除A:a以外的所有过滤器,对于方面B希望保留除B:b以外的
-
ElasticSearch在另一个聚合结果上使用聚合
问题内容: 有一个对话列表,每个对话都有一个消息列表。每个消息都有一个不同的字段和一个字段。我们需要考虑的是,在对话的第一条消息中使用了动作,在几条消息中使用了动作之后,过了一会儿,依此类推(有一个聊天机器人意图列表)。 将对话的消息动作分组将类似于: 问题: 我需要使用ElasticSearch创建一个报告,该报告将返回每次会话的;接下来,我需要对类似的东西进行分组并添加一个计数;最终将导致as
-
Apache Flink-每小时聚合数据的每日聚合
我有一个窗口化的每小时聚合的数据流。 Datastreamds=.....
-
ElasticSearch聚合:每个聚合排除一个筛选器
我想过滤掉字段'a'等于'a'的文档,同时我想对字段'a'进行刻面处理,当然不包括前面的过滤器。我知道您可以将筛选器放在查询的“外部”,以便在不应用该筛选器的情况下获得方面,例如: 弹性搜索 索尔尔 也就是说,对于方面A,我希望保留除A:A以外的所有过滤器,对于方面B,我希望保留除B:B以外的所有过滤器,以此类推。最明显的方法是执行n个查询(n个方面中的每一个),但我不想这样做。
-
Yii2 Codeception-超过超时时间
我使用命令生成器在Jenkins服务器上运行单元测试。phar exec“codecept运行单元应用程序/模型”-vvv并获取以下错误: [Symfony\Component\Process\Exception\ProcessTimedOutException] 进程“codecept运行单元应用程序/模型”超过了1800秒的超时时间。 我如何修复它并允许测试花费更多的时间?谢谢
-
超全局变量
一般来讲,在 Swoole 项目中,你是无法使用 $_GET、$_POST等超全局变量的。 自 imi v1.0.15 版本开始支持,启用方法: 在项目配置文件的 beans 中加入: [ 'SuperGlobals' => [ 'enable' => true, ], ]
-
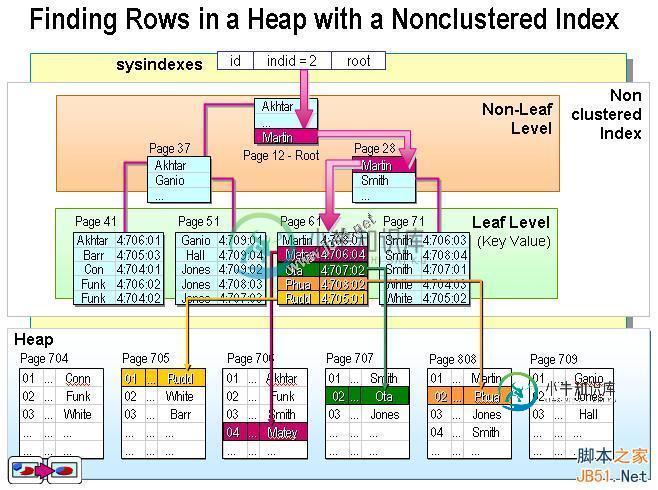 sql 聚集索引和非聚集索引(详细整理)
sql 聚集索引和非聚集索引(详细整理)本文向大家介绍sql 聚集索引和非聚集索引(详细整理),包括了sql 聚集索引和非聚集索引(详细整理)的使用技巧和注意事项,需要的朋友参考一下 聚集索引 一种索引,该索引中键值的逻辑顺序决定了表中相应行的物理顺序。 聚集索引确定表中数据的物理顺序。聚集索引类似于电话簿,后者按姓氏排列数据。由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚集索引。但该索引可以包含多个列(组合索