《差旅壹号》专题
-
下列声明的差异[副本]
那么在上述任何一个声明中, 为什么和不引用同一个对象?
-
C矢量加法补偿误差:
所以我有这个代码: 这是我在最后一行得到的补偿错误: [错误]不匹配运算符 那是为什么呢?
-
Spring无功高负荷性能差
我有一个spring boot webflux应用程序,默认情况下使用Netty。其中一个业务需求,我们有要求,要求应超时在2秒内。 当很少的请求被发送到应用程序时,一切都很好,但是当请求负载增加时(比如Jmeter每秒并发超过40或50次),由于每个请求的时间超过2秒阈值,有时所有请求都会超时。 如果有人能告诉我该做什么,那将是一个巨大的帮助。在这一点上,我没有更多的改进,并认为我可能已经看错了
-
ffmpeg视频转jpg帧质量差
crf 20是相当高的质量,接近100%,恢复的帧应该接近原始。视频播放器暂停帧显示足够的质量。(虽然我不能说它是否在关键帧上) ffmpeg版本信息:
-
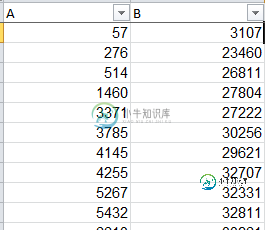 两列[闭合]之间的差异
两列[闭合]之间的差异我有这样的Excel数据: 我想在ColumnA中找到Columnb中不存在的记录。
-
add()、replace()和addToBackStack()之间的差异
调用这些方法的主要区别是什么: 替换已经存在的片段,将片段添加到活动状态,并将活动添加到后堆栈,这意味着什么? 其次,使用,此搜索是通过/方法还是通过方法添加的标记?
-
Java中的协方差与重载
你能解释一下第一行最后一个false输出,为什么它不是真的吗?
-
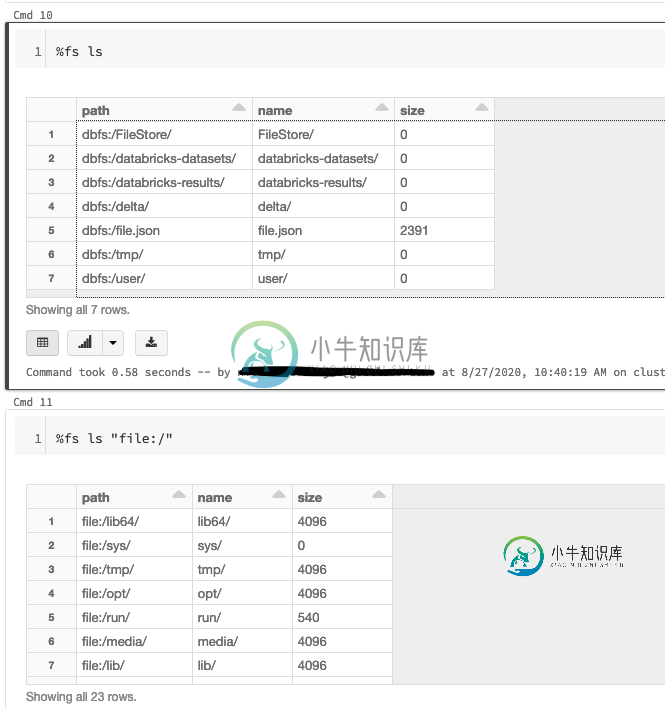 Databricks:dbfs:/vs文件之间的差异:/
Databricks:dbfs:/vs文件之间的差异:/我正在尝试了解Database ricks存储文件的方式,我有点不确定dbfs:/和file:/之间的区别是什么(见下图) 从这里我可以推断,file:/似乎是通过curl/wget下载的外部文件在以下文件夹路径中下载的区域: 但是file:/到底是什么,它为什么存在,它与dbfs:/有何不同? 作为记录,我正在使用Databricks的社区免费版本。
-
火花拼花器读数误差
我在一个Spark项目上工作,这里我有一个文件是在parquet格式,当我试图用java加载这个文件时,它给了我下面的错误。但是,当我用相同的路径在hive中加载相同的文件并编写查询select*from table_name时,它工作得很好,数据也很正常。关于这个问题,请帮助我。 java.io.ioException:无法读取页脚:java.lang.runtimeException:损坏的文
-
使用RecycerView的视差头效果
我想将我当前拥有的ListView更改为使用,这样我就可以使用,但是RecycerView不能添加ListView这样的标头。
-
计算每行的标准偏差
我尝试使用< code>rowSds()来计算每一行的标准偏差,这样我就可以选择具有高标准偏差的行来绘制图表。 我的数据帧名为<code>xx 我试图计算每一行的标准偏差,并辅助sd列名: 我得到这个错误: 知道在计算SD时如何省略吗?我的语法正确吗?
-
FileWriter和BufferedWriter之间的Java差异
这两者有什么区别?我只是在学习Java ATM,但似乎我可以双向写入文件,即(我没有复制try-catch块) 和 我理解先缓冲数据的概念,那么这是否意味着第一个示例逐个写入字符,第二个示例先将其缓冲到内存中并写入一次?
-
保持顺序时的向量差
我有两个向量,分别是{'K','P'、'T'、'M'}。我必须得到这两个向量之间的差异,同时保持顺序,即。 我知道函数,但不能使用,因为这需要对向量进行排序。在C中有什么优化的方法吗?
-
QueryDSL中的平均日期差异
我有一个实体,它有一个表示上次活动的日期对象。我想查询一下平均空闲时间。因此在SQL中,类似于: 我试着这样算了一下差别: 我如何以日期/时间差(以秒为单位)来表示这个平均值?
-
WebDriver.Dispose()、.close()和.quit()之间的差异
null