《差旅壹号》专题
-
2.10. Robust 协方差估计
实际数据集通常是会有测量或记录错误。合格但不常见的观察也可能出于各种原因。 每个不常见的观察称为异常值。 上面提出的经验协方差估计器和收缩协方差估计器对数据中异常观察值非常敏感。 因此,应该使用更好的协方差估计(robust covariance estimators)来估算其真实数据集的协方差。 或者,可以使用更好的协方差估计器(robust covariance estimators)来执行异
-
2.9. 稀疏逆协方差
协方差矩阵的逆矩阵,通常称为精度矩阵(precision matrix),它与部分相关矩阵(partial correlation matrix)成正比。 它给出部分独立性关系。换句话说,如果两个特征在其他特征上有条件地独立, 则精度矩阵中的对应系数将为零。这就是为什么估计一个稀疏精度矩阵是有道理的: 通过从数据中学习独立关系,协方差矩阵的估计能更好处理。这被称为协方差选择。 在小样本的情况,即
-
6.exec 跟 source 差在哪
这次让我们从CU shell版的一个实例帖子来谈起吧: (论坛改版后,原链接已经失效) 例中的提问原文如下: 帖子提问: cd /etc/aa/bb/cc可以执行 但是把这条命令放入shell脚本后,shell脚本不执行! 这是什么原因? 意思是:运行shell脚本,并没有移动到/etc/aa/bb/cc目录。 我当时如何回答暂时别去深究,先让我们了解一下进程 (process)的概念好了。 首先
-
什么是视差滚动?如何实现视差滚动的效果?
本文向大家介绍什么是视差滚动?如何实现视差滚动的效果?相关面试题,主要包含被问及什么是视差滚动?如何实现视差滚动的效果?时的应答技巧和注意事项,需要的朋友参考一下 什么是视差滚动: 就是在同一视角下,鼠标或者页面滚动时,不同元素以不同的速率跟随滚动,产生生动的效果。 如何实现视差滚动: 根据页面滚动高度的变化,JS相应调整不同元素的不同位移,常见的插件有 parallax.js,以及更多的推荐《1
-
Pandas:计算整个数据框的均值或标准差(标准差)
问题内容: 这是我的问题,我有一个像这样的数据框: 我只想计算整个数据帧的平均值,因为以下方法不起作用: 然后我想出了: 但是,此技巧不适用于计算标准偏差。我最后的尝试是: 除了在后一种情况下,它使用了numpy中的mean()和std()函数。这不是平均值的问题,而是std的问题,因为pandas函数默认使用,而不是numpy的where 。 问题答案: 您可以将数据框转换为单列(将形状从5x3
-
Python集合之间的差异。计数器和nltk。可能性频差
我想计算文本语料库中单词的词频。我一直在使用NLTK的word_tokenize,后跟概率。FreqDist一段时间来完成这项工作。单词_tokenize返回一个列表,该列表由FreqDist转换为频率分布。然而,我最近在collections(collections.Counter)中遇到了计数器函数,它似乎在做完全相同的事情。FreqDist和Counter都有一个最常用(n)函数,返回n个最
-
如何计算C ++或Java中的方差,中位数和标准差?
问题内容: 我有一些双打(1.1,2,3,5)的向量。如何计算方差,中位数和标准偏差? Java或C ++甚至伪代码都可以。 问题答案: public class Statistics { double[] data; int size;
-
强化学习:蒙特卡罗,时序差分,多步时序差分
蒙特卡罗方法也称为统计模拟方法(或称统计实验法),是一种基于概率与统计的数值计算方法。该计算方法的主要核心是通过对建立的数学模型进行大量随机试验,利用概率论求得原始问题的近似解,与它对应的是确定性算法。
-
请说一下,你要如何组织一场班级旅游?
本文向大家介绍请说一下,你要如何组织一场班级旅游?相关面试题,主要包含被问及请说一下,你要如何组织一场班级旅游?时的应答技巧和注意事项,需要的朋友参考一下 旅行线路选择、旅行方式选择、出行人数确定、安全保障。 出发前: 1、需求收集、分析 设计问卷,调研班级同学空闲时间、期望的旅行类型、可接受价格区间等信息。 对收集到的信息进行统计分析,找出空闲时间最集中、热度最高的旅行类型以及价格区间。 2、线
-
“围棋之旅”网络爬虫练习中的频道说明
问题内容: 我正在经历“ A Go of Go”,并且一直在编辑大多数课程,以确保我完全理解它们。我对以下练习的答案有疑问: https : //tour.golang.org/concurrency/10,可在此处找到: https //github.com/golang/tour/blob/master/solutions/ webcrawler.go 我对以下部分有疑问: 从通道添加和删除t
-
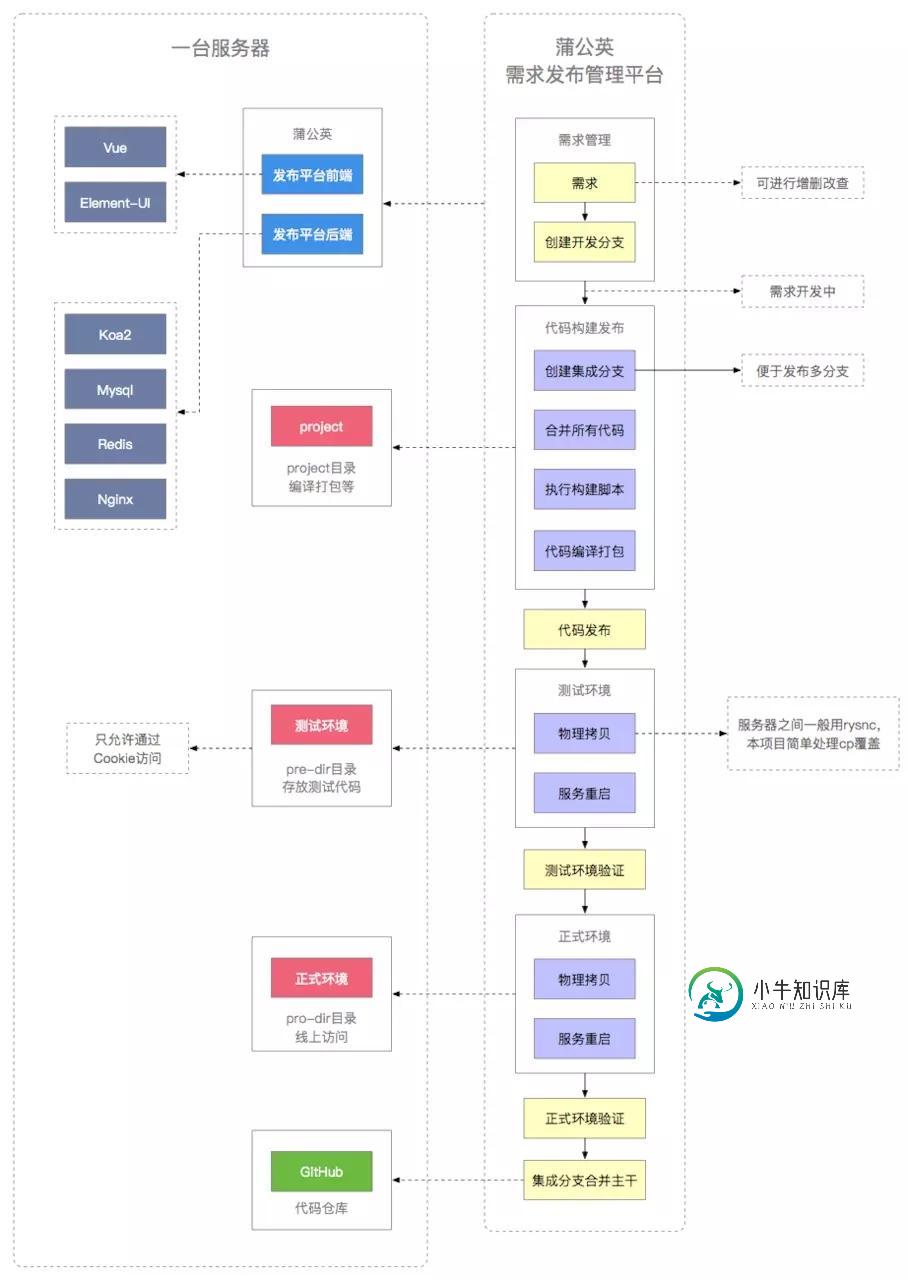 如何自动化部署项目?折腾服务器之旅~
如何自动化部署项目?折腾服务器之旅~本文向大家介绍如何自动化部署项目?折腾服务器之旅~,包括了如何自动化部署项目?折腾服务器之旅~的使用技巧和注意事项,需要的朋友参考一下 本篇文章讲的不是如何把一个项目部署上线,而是如何自动化上线。 开发了一个需求管理和发布系统。 通过这个系统,可以创建需求、创建发布计划、创建分支、部署到测试环境、部署到生产环境、正式上线、合并代码等。 一、功能设计 9.9元的阿里云服务器真的很慢,但还是足够折腾完
-
 一段艰难的游戏策划实习之旅(含面经)
一段艰难的游戏策划实习之旅(含面经)更新一下,一段实习已经结束啦!本想着安心过大年,结果正好被另一家拐走,无缝衔接🙃 从十月开始找,历经波折啊...... 阿里灵犀——二面挂 快手游戏——二面挂 巨人网络——oc 沐瞳科技——oc 鹰角网络——笔试挂(就你最离谱啊角) 高贵的tx——被调剂了,没去 高贵的网易——二面挂 更高贵的网易雷火——简历挂(不愧是你) 莉莉丝——一面挂 搜狐畅游——oc 完美世界——oc 大多数简历都没挂,
-
分类中的高相对绝对误差和相对平方根误差
我的模型JRip分类器有一个小问题 输出似乎足够好,但我担心相对绝对误差和相对平方根误差会很高。当我尝试J48和NaiveBayes时,它也高出了98%。这在分类中不是很重要吗?我可以就这样离开吗?否则,我如何改进它?成本矩阵为: 0 1 2 0 是什么改善了二等舱TP费率的结果。提前感谢您的帮助
-
DateTimeFormatter基于周的年差异
问题内容: 我正在将应用程序从Joda-Time迁移到Java 8 。 我遇到的一件事是使用中的图案打印基于周的年份。 根据文档 但是,当我尝试这两个时,似乎总是会返回与相同的结果。 我的测试代码: 输出: 从重要的年份(例如2000、2005、2009和2016)来看,和的输出是不同的。 在Java的时间与DateTimeFormatter基于周周的–一年模式分析中指出,这与本地化做的(如可以清
-
Java集合协方差问题
问题内容: 可以说我们有一个包含此类的程序: 容易吧?好吧,可以说我们现在想要制作这样的方法(在某个随机类中): 现在的问题是,在Java的泛型集合不是协变的(希望这是我要找的术语),我不能分配给一个。我在这里看到的唯一解决方案是复制代码并为每种类型做一个版本,但这显然很糟糕(如果我们有更多的类用不同的列表实现AbstractToolbox会怎样?)。哦,显然,第二种解决方法是删除泛型并创建一个普