《拆分》专题
-
使用特定方法拆分二叉树
给定一棵二叉树,我必须返回一棵树,其中包含所有小于k、大于k的元素和一棵树,其中仅包含一个元素-k。允许使用的方法:删除节点-O(n)插入-O(n)查找-O(n)查找min-O(n)我假设这些方法的复杂性,因为在练习中没有写到树是平衡的。所需的复杂性-O(n)原始树必须保持其结构。我完全被卡住了。非常感谢任何帮助! 给定的树是二元搜索树,输出应该是二元搜索树。
-
将图像拆分为可点击区域
有没有办法将图像分割到区域(现在是JLabel,但如果需要我可以更改它)? 我在我的程序中使用swing,我有一个图像(这个例子是正方形),里面有一些三角形、星星和梯形(它可以是JPG、PNG等)。 这个想法是用户将点击这些形状中的一个,然后我将在用户点击的区域顶部放置另一个小图标。用户可以点击多个区域,但在一天结束时,我需要知道哪些形状被点击。
-
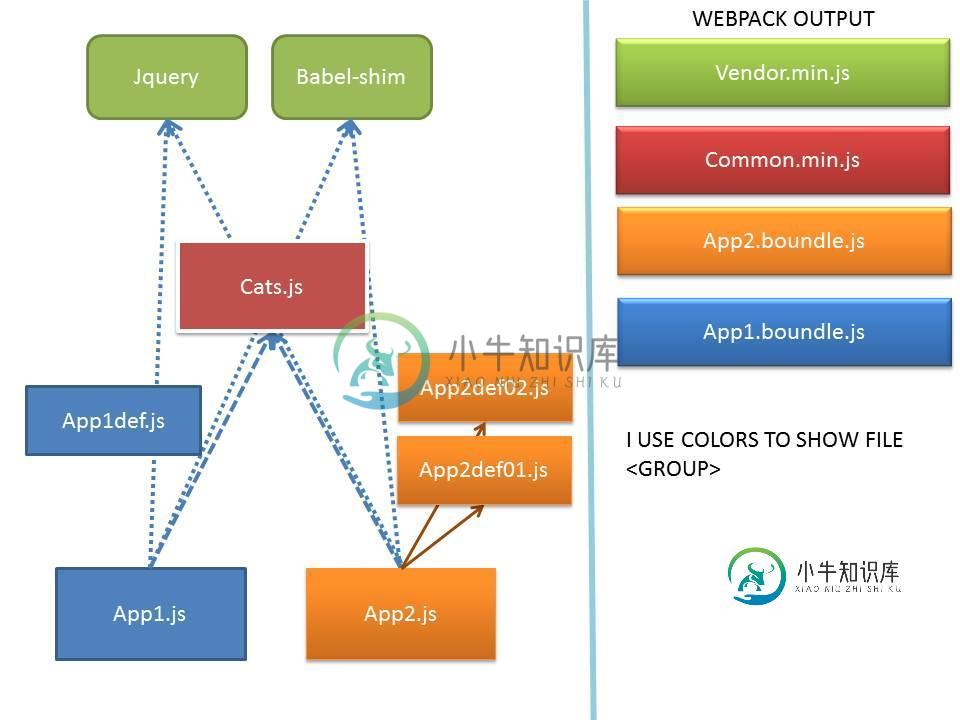 webpack-拆分文件并创建2个bundle
webpack-拆分文件并创建2个bundle我试图用webpack实现以下目标 简而言之,我有两个切入点: app.js和app2.js null 我的webpack配置在这里: 完整的项目在这里:https://github.com/mydiscogr/webpack-babel-config/
-
Hadoop输入拆分和记录阅读器
在apache文档中阅读以下内容: InputSplit表示单个映射器要处理的数据。 通常,它在输入上显示一个面向字节的视图,作业的RecordReader负责处理该输入并显示一个面向记录的视图。 链接-https://hadoop.apache.org/docs/r2.6.1/api/org/apache/hadoop/mapred/inputsplit.html 有人能解释一下面向字节的视图和
-
Apache Flink连续拆分奇怪的行为
我相信,当连续完成两个拆分时,Flink的行为很奇怪。我可能在我的实现逻辑中有一些错误,这就是为什么我在这里发帖征求您的意见。 最小示例:我有一个包含单词Apple、Banana和Orange的文本文件。我将其作为源在流执行环境中传递。我进行了第一次拆分,其中选择条件是参数是否为单词“Apple”。如果是,我将其放在“主题”Apples中,否则放在“主题”NotApples中。然后我在此拆分流中选
-
presto将单个列值拆分为多行
我在presto上有一个表,它有多个记录的记录。在该记录中,我使用了这个简单的SQL查询,
-
ORACLE-拆分字符串并创建游标
我对神谕主题有意见 我们有一个表,其中一列存储由逗号(,)ex分隔的数据 我们需要能够分离这个值,并得到这样的结果 但是这个列的数量并不是固定的,一些类型可能是不同的数据湖,我们需要动态响应,例如 如果我为1运行进程,结果与以前一样 但是如果我为类型2运行它,结果应该如下 我们可以将项目字段转换为varchar2表,但我们找不到如何将其转换为使用游标。任何想法?非常感谢!对不起,如果我的英语不被理
-
Oracle:将函数结果拆分为多列
它是这样的: 插入some_table(col1,col2,col3,col4) 选择col1、col2、my_func(col3)为new_col3、col4 现在我需要使用相同的逻辑返回两个值而不是一个值。 我可以简单地编写另一个函数来执行相同的逻辑并返回第二个值,但这将是昂贵的,因为该函数从一个大的历史表中进行选择。 我不能与历史表进行连接,因为该函数没有执行简单的select。
-
Apache Camel拆分和聚合异常处理
我们在Camel中定义了一个具有拆分和聚合功能的路由,但无法在聚合器之后将异常传播回拆分。这导致即使我们遇到异常,拆分也会运行 下面是不工作的代码 上述代码中的处理器(myProcessor)如下: 但是,当我从路由中移除聚合时,Split能够在异常情况下停止路由。
-
如何在Swift[duplicate]中拆分字符串
我不想拆分我的字符串,以便hello的值得到“hello”,而hi的值得到“hi”
-
将64位值拆分为四个16位
我有如下64位值: 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1101 0011 给定数字流的十进制值为-45。 我想分成四个16位值: 1111111111111111111 1111111111111111111 1111111111111111111111111 1111111111111111
-
将Pandas列的列表拆分为多列
如何将这列列表拆分为两列? 期望的结果:
-
将PDF文档拆分为多个文档
我正在尝试将一个PDF文档拆分为多个文档,其中每个文档包含的最大页数小于最大文件大小。 我的代码目前可以在Eclipse上运行,但是当我点击. jar文件时,java类中的静态方法似乎崩溃了(但是我似乎抓不到异常)。 不工作的代码是: myListOfDocuments=mysplitter。拆分(文件); 在调用上述行时,JVM会以某种方式退出静态方法。加载似乎工作正常,如下所示:PDDocum
-
 透明地将webm视频拆分为png
透明地将webm视频拆分为png我需要将编码的视频拆分为帧,同时不失去透明度。我使用以下ffmpeg命令: 这将产生一个pngs目录,但为什么每个输出帧都缺少透明度? 我已经使用了这个示例视频,其中包含一个alpha通道。看到它在背景上播放。下面是FFMPEG的一个输出帧示例:
-
Hadoop MapReduce TextInputFormat-如何进行文件拆分
根据我的理解,应该在换行符处精确拆分,但根据我在网站上看到的一些答案,我似乎错了。有人有更好的解释吗?哪个选择是正确的? 以下哪项最能描述的工作方式? > 输入文件拆分可以交叉换行。跨越文件拆分的行由包含折线结尾的拆分的读取。 输入文件正好在换行符处拆分,因此每个记录读取器将读取一系列完整的行。 输入文件拆分可能会交叉换行符。将忽略横过平铺拆分的线。 输入文件拆分可能会交叉换行符。跨越文件拆分的一