
webpack-拆分文件并创建2个bundle

我试图用webpack实现以下目标
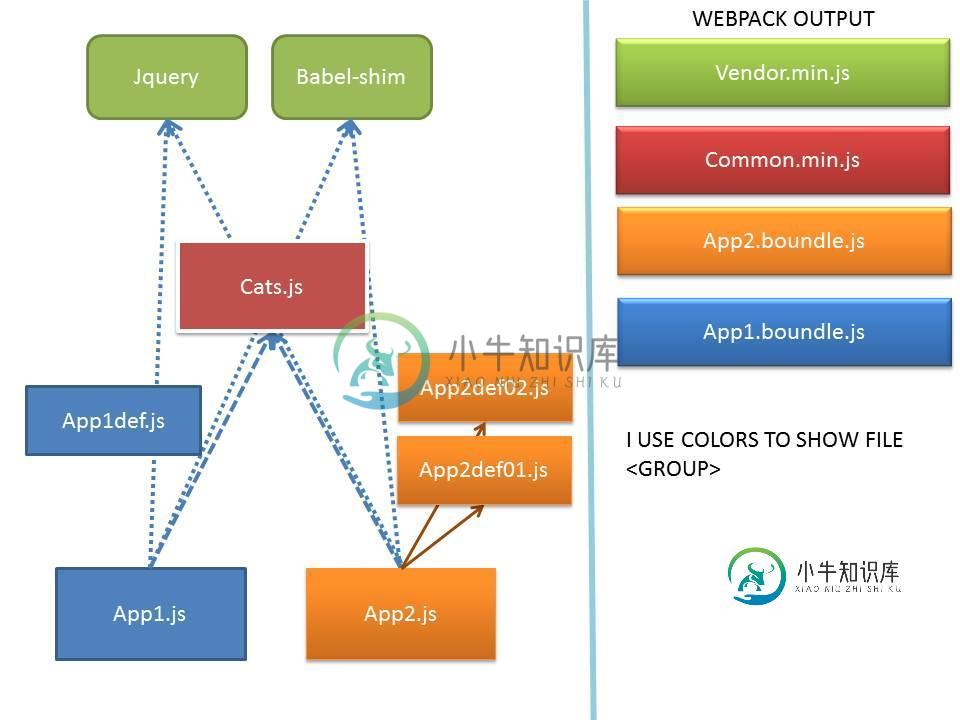
简而言之,我有两个切入点:
app.js和app2.js
-
null
我的webpack配置在这里:
var webpack = require("webpack");
const createVendorChunk = require('webpack-create-vendor-chunk');
module.exports = {
entry: {
app:"./src/js/app.js",
app2:"./src/js/app2.js"
},
output: {
path: './bin',
filename:"[name].bundle.js",
},
module: {
loaders: [{
test: /\.js$/,
exclude: /node_modules/,
loader: 'babel-loader'
}]
},
resolve: {
extensions: ['', '.js', '.es6']
},
plugins: [
/*
new webpack.optimize.CommonsChunkPlugin({
name: "vendor",
filename: "vendor.min.js",
minChunks: Infinity
})
*/
createVendorChunk({
name:"vendor.min.js"
}),
createVendorChunk({
name:"common.min.js",
chunks:["common"]
}),
]
};
完整的项目在这里:https://github.com/mydiscogr/webpack-babel-config/
共有1个答案

你能试试这个吗?
entry: {
app:"./src/js/app.js",
app2:"./src/js/app2.js"
vendor: [
'jquery',
'moment',
'lodash',
'some other vendor'
]
},
output: {
path: './bin',
filename:"[name].bundle.js",
},
module: {
loaders: [{
test: /\.js$/,
exclude: /node_modules/,
loader: 'babel-loader'
}]
},
resolve: {
extensions: ['', '.js', '.es6']
},
plugins: [
// it moves cat.js to common.js
new webpack.optimize.CommonsChunkPlugin({
name: 'Common',
chunks: ['App1', 'App2']
}),
// some third party libraries (eg: jquery, moment) when used in App1, App2, and Common moves to vendor.js
new webpack.optimize.CommonsChunkPlugin({
name: 'Vendor',
minChunks: Infinity
}
// Just Other Tricks!!
// Delete 2 CommonsChunkPlugin option above and add this
new webpack.optimize.CommonsChunkPlugin({
// The order of this array matters
names: ['Common', 'Vendor'],
minChunks: 2
})
]
如果有用就告诉我
-
问题内容: 我有一个文件,我想用Java读取并将其拆分为(用户输入)输出文件。这是我读取文件的方式: 如何将文件拆分为文件? 注意-由于文件中的条目数约为100k,因此我无法将文件内容存储到数组中,然后将其拆分并保存到多个文件中。 问题答案: 由于一个文件可能很大,因此每个拆分文件也可能很大。 例: 源文件大小:5GB 数字分割:5:目的地 档案大小:每个1GB(5个档案) 即使我们有这样的内存,
-
我对神谕主题有意见 我们有一个表,其中一列存储由逗号(,)ex分隔的数据 我们需要能够分离这个值,并得到这样的结果 但是这个列的数量并不是固定的,一些类型可能是不同的数据湖,我们需要动态响应,例如 如果我为1运行进程,结果与以前一样 但是如果我为类型2运行它,结果应该如下 我们可以将项目字段转换为varchar2表,但我们找不到如何将其转换为使用游标。任何想法?非常感谢!对不起,如果我的英语不被理
-
我有这个批处理文件来拆分txt文件: 它可以工作,但它一行一行地拆分它。我如何让它每5000行拆分一次。提前感谢。 编辑: 但我得到一个错误提示:<code>没有足够的存储空间来处理此命令。<code>
-
我试图通过在本地服务器上创建zip文件来下载a 2文件。文件是以zip格式下载的,但当我试图解压缩它时。它给出了一个错误:找不到中央目录签名的结尾。要么该文件不是zip文件,要么它构成了多部分存档的一个磁盘。在后一种情况下,中心目录和zip文件注释将在该存档的最后一个磁盘上找到。 下面的代码我使用这个: 我检查了传递到函数中的所有变量的值,都很好。所以请看这个。提前谢谢。
-
问题内容: 我有从mongodb导出的json文件,如下所示: 大约有30000行,我想将每一行拆分成自己的文件。 (我正在尝试将我的数据转移到榻榻米群集上) 我尝试这样做: 但是我发现它似乎减少了行的负载,而当我期望30000个奇数时,运行此命令的输出仅给了我50个奇数文件! 有没有一种逻辑方法可以使此操作不使用任何适合的方法删除任何数据? 问题答案: 假设您不在乎确切的文件名,如果要将输入拆分
-
问题内容: 将Spring的配置拆分为多个xml文件的正确方法是什么? 此刻我有 /WEB-INF/foo-servlet.xml /WEB-INF/foo-service.xml /WEB-INF/foo-persistence.xml 我有以下内容: 实际问题: 这种方法正确/最佳吗? 我真的需要同时指定中的配置位置 和该板块? 我需要记住什么才能能够引用中定义的?这与 指定有关吗? 更新1: