《梅卡曼德机器人实习》专题
-
Android获取手机联系人电话号码并返回结果
本文向大家介绍Android获取手机联系人电话号码并返回结果,包括了Android获取手机联系人电话号码并返回结果的使用技巧和注意事项,需要的朋友参考一下 之前做了一个小练习需要用到获取手机里联系人的电话号码,通过查阅相关的资料,自己尝试写了一个小例子,可以成功获取。 首先需要在AndroidManifest.xml中获取权限 xml布局文件 MainActivity.java 以上就是本文的全部
-
有没有人使用秋千在Java中的老虎机示例?
问题内容: 我想获得一些有关用Java编写的老虎机GUI的示例,我知道这是一种特定的东西,但是我想知道是否可以用Java swing或类似的方式做一些动画问候 问题答案: 这不是老虎机模拟,但是您可以在此示例中找到相关功能。 附录:引用的示例使用Unicode字形来实现多样性,但另一个技巧是实现接口,该接口与某些组件配合得很好。本示例装饰用于游戏的,而本示例扩展的子级以渲染表格。
-
多人联机射击游戏中的设计模式应用(二)
(6) 观察者模式 联机射击游戏可以实时显示队友和敌人的存活信息,如果有队友或敌人阵亡,所有在线游戏玩家将收到相应的消息,可以提供一个统一的中央角色控制类(CenterController)来实现消息传递机制,在中央角色控制器中定义一个集合用于存储所有的玩家信息,如果某玩家角色(Player)阵亡,则调用CenterController的通知方法notifyPlayers()
-
多人联机射击游戏中的设计模式应用(一)
为了方便大家更加系统地学习和掌握各种常用的设计模式,下面通过一个综合实例——“多人联机射击游戏”来学习如何在实际开发中综合使用设计模式。 反恐精英(Counter-Strike, CS)、三角洲部队、战地等多人联机射击游戏广受玩家欢迎,在多人联机射击游戏的设计中,可以使用多种设计模式。下面我选取一些较为常用的设计模式进行分析: (1) 抽象工厂模式 在联机射击游戏中提
-
 2024华为OD机试真题 - 快速人名查找 JAVA代码
2024华为OD机试真题 - 快速人名查找 JAVA代码2024华为OD机试真题,代码包含语言java 代码基本都有详细注释。 题目描述 给一个字符串,表示用’,’分开的人名。 然后给定一个字符串,进行快速人名查找,符合要求的输出。 快速人名查找要求︰人名的每个单词的连续前几位能组成给定字符串,一定要用到每个单词。 输入描述 第一行是人名,用’,’分开的人名 第二行是 查找字符串 输出描述 输出满足要求的人名 用例 输入 zhang san,zhang
-
uniapp真机测试安卓9不发请求,友人知道吗?
点击登录只转圈,看了一下代码根本没发请求
-
如何使用Java Swing实现可拖动选项卡?
问题内容: 如何使用Java Swing实现可拖动选项卡?除了将静态JTabbedPane拖放到其他位置以外,还可以将其重新排列。 编辑 :Java教程- 拖放和数据传输 。 问题答案: 我喜欢Terai Atsuhiro san的DnDTabbedPane,但我想要更多。最初的Terai实现在TabbedPane中转移了选项卡,但是如果我可以从一个TabbedPane拖动到另一个,那就更好了。
-
js简单实现竖向tab选项卡的方法
本文向大家介绍js简单实现竖向tab选项卡的方法,包括了js简单实现竖向tab选项卡的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了js简单实现竖向tab选项卡的方法。分享给大家供大家参考。具体如下: 选项卡占据左边,而内容放在右边,一个适合新手的竖向的tab选项卡特效例子 希望本文所述对大家的javascript程序设计有所帮助。
-
批处理脚本实现提醒下班要打卡
本文向大家介绍批处理脚本实现提醒下班要打卡,包括了批处理脚本实现提醒下班要打卡的使用技巧和注意事项,需要的朋友参考一下 你是不是经常下班忘记打卡,要被扣钱的哟,下载这个脚本,在windows下添加一个定时任务,到点提醒你一定要去打卡。 下班经常忘记打卡,于是写了这个脚本来提醒我,在计划任务里设定好下班时间运行该脚本既可。 另一个版本 以上所述就是本文的全部内容了,希望大家能够喜欢。
-
 Android开发之自定义刮刮卡实现代码
Android开发之自定义刮刮卡实现代码本文向大家介绍Android开发之自定义刮刮卡实现代码,包括了Android开发之自定义刮刮卡实现代码的使用技巧和注意事项,需要的朋友参考一下 关于刮刮卡的实现效果不需要做太多解释,特别是在电商APP中,每当做活动的时候都会有它的身影存在,趁着美好周末,来实现下这个效果,也算是对零碎知识点的一个整合。 所涉及的知识点: 1、自定义View的一些流程 2、双缓冲绘图机制 3、Paint的绘图模式
-
 Android编程之TabWidget选项卡用法实例分析
Android编程之TabWidget选项卡用法实例分析本文向大家介绍Android编程之TabWidget选项卡用法实例分析,包括了Android编程之TabWidget选项卡用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Android编程之TabWidget选项卡用法。分享给大家供大家参考,具体如下: 1 概览 TabWidget与TabHost。tab组件一般包括TabHost和TabWidget、FrameLayout,且
-
 javascript - 类似卡券的布局请问怎么实现?
javascript - 类似卡券的布局请问怎么实现?像这种卡券的缺口请问如何实现,如果背景是纯色直接定位个纯色上去也就没啥问题,但这种背景渐变的显然不行,请巨佬贴个demo给我学习一下谢谢
-
 实战-Swing实现计算器
实战-Swing实现计算器主要内容:1 Swing实现计算器1 Swing实现计算器 我们可以借助Swing的事件处理功能来开发Java计算器。让我们看看在Java中创建计算器的代码。 最终运行效果为: 点击下载完整计算器源码
-
什么是Java的本机实现?
问题内容: 如果我们看一下Java Object类,那么我们可以找到一些方法,例如: 这些本机是什么,这些方法如何工作? 问题答案: 这些方法是 本 机的,也可能是在Java外部用“本机”代码编写的,也就是说,特定于给定的计算机。 您提到的是 _内部的,_并且是JDK的一部分,但是您也可以自己使用Java本机接口(JNI)编写本机方法。通常,这将使用C来编写方法,但是许多其他语言(例如python
-
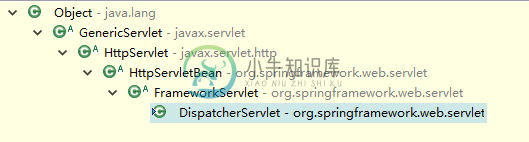 详解Spring mvc DispatchServlet 实现机制
详解Spring mvc DispatchServlet 实现机制本文向大家介绍详解Spring mvc DispatchServlet 实现机制,包括了详解Spring mvc DispatchServlet 实现机制的使用技巧和注意事项,需要的朋友参考一下 在Spring中, ContextLoaderListener只是辅助类,在web 容器启动的时候查找并创建WebApplicationContext对象,通过该对象进行加载spring的配置文件。而真正