《2022毕业即失业取暖地》专题
-
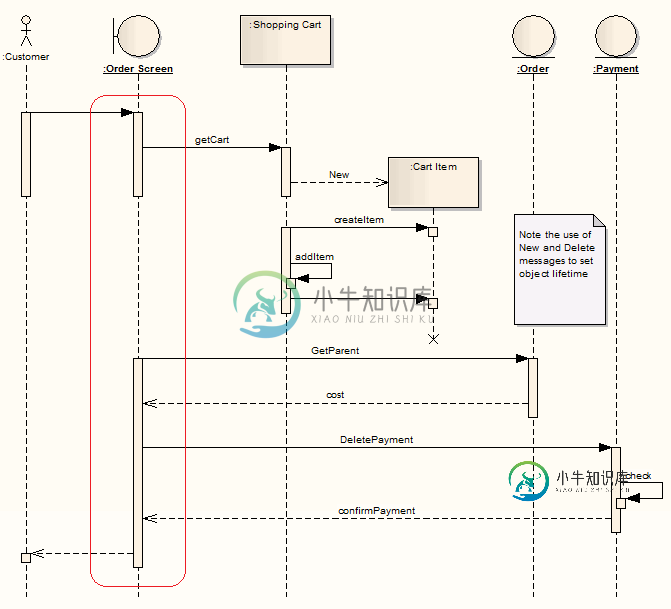 合并实体-企业架构师
合并实体-企业架构师我有一个问题,我如何“合并”实体的序列图在企业架构师(红圈),使他们成为一个长长的条从顶部到结束的生命线?
-
关闭Quartz作业日志记录
在我的应用程序中,石英作业是在应用程序部署后立即安排的。我有两个日志文件和,都用于特定的日志记录。搜索日志文件只是记录访问者的IP,其余所有日志记录(异常、调试信息)都记录在应用程序日志文件中。 我面临的问题是,默认的Quartz语句正在登录到文件中,这不是必需的。 如何禁用该日志记录?将级别设置为OFF不起作用。我也遵循了禁用石英日志记录,但这也没有帮助。 下面是我的log4j.properti
-
Spring批量-动态作业选择
我们当前的代码库具有以下重要特征: 一个代码库-但是很多批处理(我们在批处理之间重用代码) 目前,我们在代码库中有多个main()方法,并且只有不同的shell脚本来调用正确的main类。 我希望在Spring Batch中解决以下问题: null 提前谢了。
-
正在kubernetes上运行flink作业
我正在kubernetes上试用最新版本的Flink1.5的flink工作。 我的问题是如何在上面的flink集群上运行一个示例应用程序。flink示例项目提供了如何使用flink应用程序构建docker映像并将该应用程序提交给flink的信息。我遵循了这个例子,只是把flink的版本改成了最新版本。我发现应用程序(example-app)提交成功,并且在kubernetes的pod中显示,但是f
-
Spring批处理作业存储库
我已经开始探索Spring Batch,并遇到了一些基本问题。
-
获得定制的商业产品
我想得到10产品从一个类别在WooCommerce 例如,对于获取帖子类别的最新帖子,我使用以下代码 我想要一个代码,像这样的商业产品
-
域对象中的业务逻辑
因此,每个功能区显然都在数据库中,但它们还需要一些逻辑来确定用户何时获得了功能区。 按照我的编码方式,是一个简单的接口: 是一个抽象类,它实现了接口,避免了方法的定义: 现在,将像这样实现一个特定的功能区: 这段代码工作得很好,表是按照我期望的方式在数据库中创建的(我在本地环境中使用DDL生成)。 问题是,在域对象中编写业务逻辑感觉是错误的。这是好的练习吗?你能提出一个更好的解决方案吗?此外,我不
-
Spring石英触发程序作业
我有一个Sprint Boot-Java8应用程序,它有一个quartz作业,我在启动时配置该作业并设置一个时间表。该作业按照计划自动运行,这与您对quartz作业的期望一样。然而,现在我希望能够允许用户通过点击前端上的一个按钮手动触发这些作业,而不会扰乱该作业的正常调度。这是我所有的相关档案。 但每次运行应用程序并点击控制器的方法时,都会在控制台中出现以下错误: 我到底做错了什么?如何使此作业按
-
石英作业通常不着火
我在Maven/war项目中使用了quartz 2.2.1和Spring 3.2.5。 我的WAR文件在Apache-Tomcat-7.x下部署良好,日志表明所有quartz作业都已加载。麻烦就从这里开始。 有人能解释一下发生了什么吗?在我看来,根本不应该有任何遗漏的触发器。 多谢了。
-
Spring批处理和作业调度
-
使用ExecutorService并行处理作业
我正在编写一个需要处理大量URL的java程序 每个URL将按顺序运行以下作业:下载、分析、压缩 我希望每个作业都有固定数量的线程,这样所有作业在任何给定时间都有并发运行的线程,而不是每个URL一次使用一个线程来完成所有作业。 例如,下载作业将有多个线程来获取和下载URL,一旦其中一个URL被下载,它就会将其传递给分析作业中的一个线程,一旦完成,它就会传递给压缩作业中的一个线程,等等。 我正在考虑
-
Spring xd批处理作业锁定
我正在使用sping-xd通过批处理作业进行数据摄取。大量作业在4个容器中并行运行。任何地方都在10到40个作业之间。其中大多数在不到一分钟的时间内完成。我使用redis(而不是Rabbitmq)和mysql进行数据存储。Spring-xd-批处理使用不同的mysql-db进行作业/步骤统计,我的应用程序使用不同的mysql-db用于自己的目的。两个mysql-db都在同一台服务器上。所有4个容器
-
独立运行Netlogo-企业环境
我曾多次使用NetLogo向人们解释基于代理的建模的力量,我发现它非常有效。 我在工作中遇到了一个特殊的商业问题,我认为ABM,尤其是Netlogo,可能有助于在两个观点根深蒂固且相互对立的团体之间就前进的道路达成共识。 我想做的是演示模型和修改参数。更好的是,如果可能的话,我希望他们看到我加入模型。 然而,这是一个企业环境。我不能在我的机器上安装软件,或者任何我可以连接到他们网络的机器上。 有没
-
在docker中运行cron python作业
这种方法的潜在问题是什么?是否还有其他方法,它们的利弊是什么?
-
Spring批量通用作业设计
我很难找到这个问题的正确答案。当使用Spring批处理框架时,是否可以尝试在一个通用作业中解决所有的批处理?