《2022毕业即失业取暖地》专题
-
 25提前批 作业帮
25提前批 作业帮[流程中] 投递岗位:图像算法工程师(北京) BG:双9,无实习 研究方向:计算机视觉(一篇一作SCI在投) 7.1 投递 —— 7.24 一面 —— 7.30 二面(预约) 一面(30min): 自我介绍 项目介绍(10min),提问项目创新点、与其他类似方法的比较等 论文介绍(15min),提问创新点和技术细节 手写Cross Entropy Loss 反问:业务场景、工作强度、后续安排 #面
-
Apache Spark:作业因阶段失败而中止:“TID x因未知原因失败”
我正在处理一些奇怪的错误信息,我认为这可以归结为内存问题,但我很难确定它,可以从专家那里得到一些指导。 我有一个两台机器的Spark(1.0.1)集群。两台机器都有8个核心;一台有16GB内存,另一台有32GB内存(这是主)。我的应用程序涉及计算图像中的成对像素亲和力,尽管我测试的图像到目前为止只有1920x1200大,16x16小。 我确实必须改变一些内存和并行性设置,否则我会得到显式的OutO
-
向emr提交本地spark作业
im关注亚马逊文档,向emr集群提交spark作业https://aws.amazon.com/premiumsupport/knowledge-center/emr-submit-spark-job-remote-cluster/ 在按照说明进行操作后,使用frecuent进行故障排除,它由于未解析的地址与消息类似而失败。 错误火花。SparkContext:初始化SparkContext时出错
-
如何使管道作业等待所有触发的并行作业?
问题内容: 我将Groovy脚本作为Jenkins中Pipeline工作的一部分,如下所示: 由于将标记设置为,因此它并行执行多个其他自由式作业。但是,我希望所有作业完成后才能完成呼叫者作业。目前,Pipeline作业会触发所有作业并在几秒钟后自行完成,这不是我想要的,因为我无法跟踪总时间,而且我无法一次取消所有已触发的作业。 当并行完成所有作业时,如何纠正上述脚本以完成管道作业? 我试图将构建作
-
在上游作业中显示下游作业的控制台输出
问题内容: 我正在使用詹金斯。 詹金斯(Jenkins)有上游工作:A 詹金斯(Jenkins)有下游工作:B A的控制台日志输出为: B的控制台日志输出为: 我想要得到的是: 有什么办法,我可以在作业A的控制台日志中获取作业B的控制台输出,然后确定作业“ A”是否成功(使用日志解析/ grep表示故障/错误等关键字)。 问题答案: 不确定您要达到的目标,但是看起来有些人为。查看以下方法是否满足您
-
将作业配置导入通用作业配置类(注释配置)
我正在重构一个传统的基于Spring Batch XML的应用程序,以使用注释配置。我想了解如何将以下XML文件转换为基于注释的配置,并保持相同的关注分离。 为了便于讨论,这里有一个简单的例子。 job-config-1.xml job-config-2.xml job-config-3。xml 我想从XML配置转移到Java配置。我想为每个XML创建3个作业配置类。比如说JobConfig1。j
-
Jenkins管道作业将构建状态转发到自由式作业
我目前正在使用全局构建统计插件,显示我们的工作状态在一个良好的格式图表。
-
一个作业更新另一个作业输出的最佳方法
下面是我的场景。我的工作是处理大量的csv数据,并使用Avro将其写入按日期划分的文件中。我得到了一个小文件,我想用它来更新这些文件中的一些附加条目,第二个作业我可以在需要时运行,而不是再次重新处理整个数据集。 这个想法是这样的: job1:处理大量的csv数据,将其写入压缩的Avro文件中,并按输入日期拆分为文件。源数据不按日期划分,因此此作业将做到这一点。 job2(在Job1运行之间根据需要
-
无法将作业参数传递给步骤-Spring批处理作业
我们正在实施Spring批量作业, 我们需要将作业参数从Client/MASTER传递给SLAVE。CLIENT/MASTER是我们的作业和分区代码所在的位置。我们使用传递JOB参数的J Unit调用JOB。 SLAVE是定义所有步骤及其实现(读取器Writer和处理器)的地方。 我们能够以独立的方式实现这一点,但不能与客户一起实现 我们正在使用Weblogic和Spring集成以及JMS来实现同
-
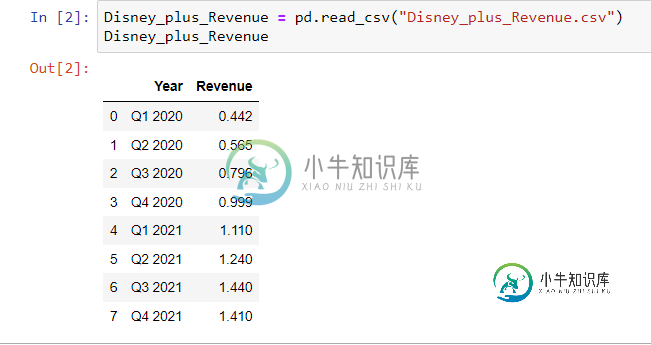 使用 Pandas 将季度业绩转换为年度业绩的建议
使用 Pandas 将季度业绩转换为年度业绩的建议因此,我有2020年第一季度至2021第四季度迪士尼加收入的季度数据。 错误-
-
Java+Spring+Quartz-Scheduler:在其他作业结束后触发一个作业
我在用Spring集成石英。
-
Quarzt:在调度作业之前/不调度作业之前存储JobDataMap
现在我需要实现作业队列,因为有些作业不能并行启动。问题是某些作业的状态()是从客户机传递的,为了排队的目的,应该保持这些状态。另一方面,我不能根据用户请求调度作业,因为我不知道什么时候应该执行它!(应该在上一个作业之后立即执行)
-
 美团春招业务运营管理岗面经(一面-业务面)
美团春招业务运营管理岗面经(一面-业务面)✅投递岗位:业务管理运营岗 ✅个人情况:1段银行投行部+1段审计+1段咨询+1段互联网 实习 ✅笔试情况:全部行测题,无主观问答题,难度适中,可以通过多刷题来准备 ✅面试情况:30分钟左右 ✅面试问题汇总: 1. 自我介绍 2. 挖深了咨询公司的实习经历,包括工作内容、团队中的角色、所经历的项目等 3. 从现在来看,为什么XX产品当时有这样的市场表现 4. 咨询公司的实习中遇到了哪些困难,如何解决
-
如何在一定次数的重试后使(cron)作业失败?
我们已经设置了一个库伯内特斯网络抓取cron作业集群。在cron作业开始失败之前,一切似乎都很顺利(例如,当站点结构发生变化并且我们的抓取器不再工作时)。看起来偶尔会有一些失败的cron作业会继续重试,直到它导致我们的集群崩溃。运行(在集群失败之前)会显示有太多作业正在为失败的作业运行。 我试图遵循这里描述的关于pod退避失败策略的已知问题的注释;然而,这似乎不起作用。 以下是我们的配置供参考:
-
 Android面经分享,失业两个月,五一节前拿到offer
Android面经分享,失业两个月,五一节前拿到offer基本介绍 疫情期间,我被裁了。 从3月初开始复习,准备面试题。 首先介绍一下自己基本情况:渣本毕业快4年,一直在小厂摸鱼混日子,学历和简历背景不是很好看,所以面试邀约也不是很多,面试也到处碰壁。从3月中旬开始面试,一直到4月底。共面试9家公司,近20轮面试,拿到2个小公司和1个上市公司(不是出名的公司)的offer,最后准备去上市公司了。也投递了BAT、360、抖音、快手、平安等大厂的岗位,不过大