《内存》专题
-
练习 29:内核:内核消息,`dmesg`
那么,如果你到达了这里,现在是谈谈内核的时候了。我们将使用维基百科的操作系统内核定义,开始这个讨论: 在计算机中,内核(来自德语 Kern)是大多数计算机操作系统的主要组成部分;它是应用程序和硬件级别上进行的实际数据处理之间的桥梁。内核的职责包括管理系统的资源(硬件和软件组件之间的通信)。通常,作为操作系统的基本组件,内核可以为资源(特别是处理器和 I/O 设备)提供最底层的抽象,应用软件必须控制
-
4.8.2 行内级元素和行内框
行内级元素(inline-level element),就是那些在源文档中不会形成新块的元素,这些元素的左右可以放置其他元素。典型的行内级元素有 span、em、strong、a,等等。 根据元素自身的特点,行内级元素又被分为非替换元素和替换元素。 非替换元素的内容直接包含在文档中,浏览器在渲染页面时,会读取元素的内容,并直接显示在页面上。说白了,非替换元素的内容就是文本。如: <span>这里
-
内容模块 - 内容分类操作
获取内容分类详情 接口 GET https://cloud.minapp.com/userve/v1/content/:content_group_id/category/:category_id/ 其中 content_group_id 是内容库的 ID, category_id 是内容分类的 ID 代码示例 var axios = require('axios').create({ wit
-
内容模块 - 内容分类操作
获取内容分类详情 接口 GET https://cloud.minapp.com/oserve/v1/content/:content_group_id/category/:category_id/ 其中 content_group_id 是内容库的 ID, category_id 是内容分类的 ID 代码示例 {% tabs getContentCategoryCurl=”Curl”, getC
-
Nodejs进程是否可以使用比可用物理内存更多的内存(通过使用交换内存)?
我正在使用Nodejs。我计划增加Nodejs应用程序的内存限制。 在谷歌上搜索时,我发现了这篇文章:增加节点。js内存限制。 作者说他的服务器只有8GB的物理内存,但他的Nodejs进程使用的是28GB的内存。我假设它正在使用物理交换内存。文章还提到,一个著名的Nodejs框架的开发人员为他的Nodejs使用了15GB的内存限制。 我试图从其他编程语言中搜索一些示例。在Java中,将交换内存用于
-
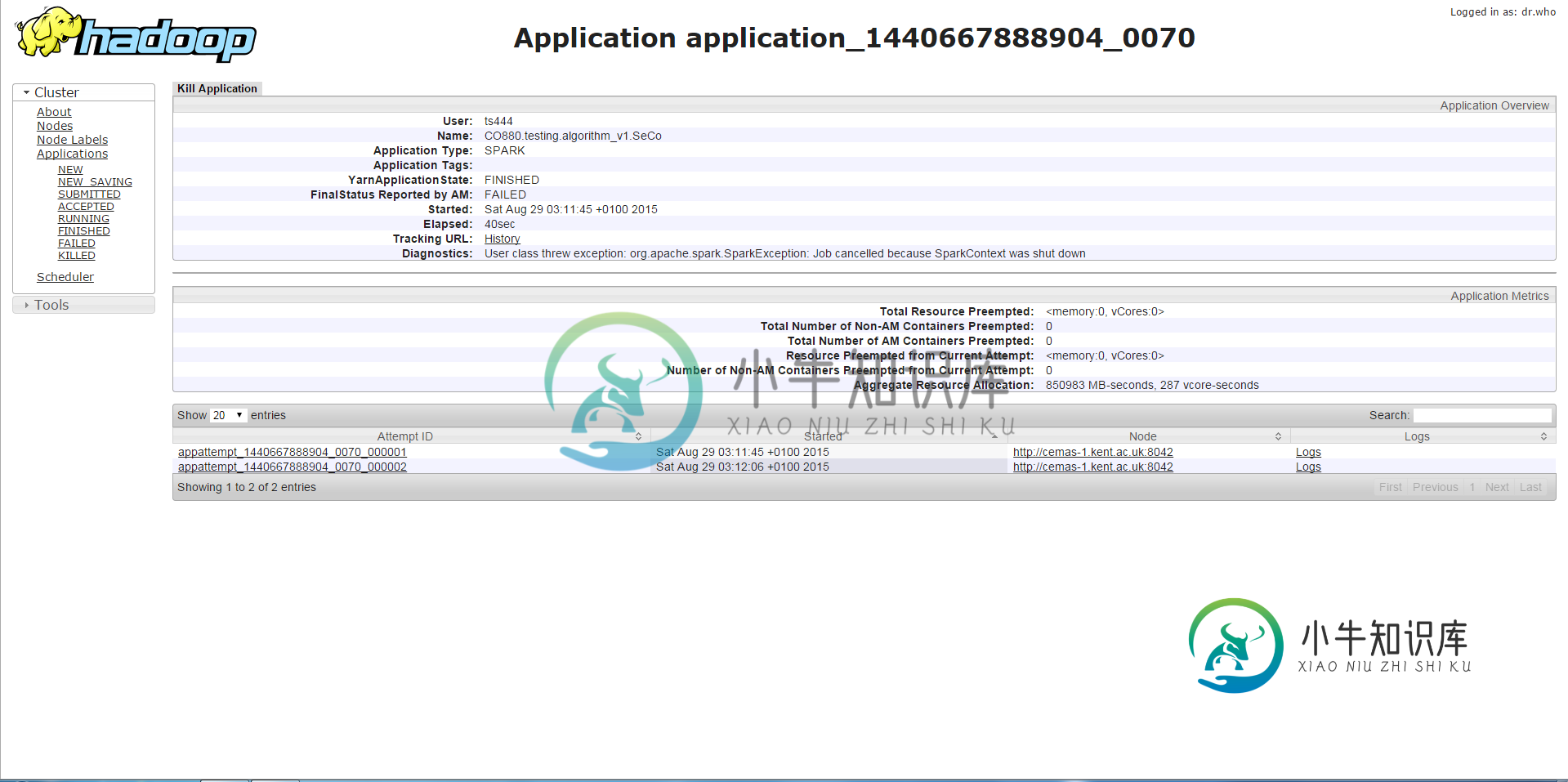 Apache Spark驱动程序内存、执行程序内存、驱动程序内存开销和执行程序内存开销对作业成功运行的影响
Apache Spark驱动程序内存、执行程序内存、驱动程序内存开销和执行程序内存开销对作业成功运行的影响我正在对YARN上的Spark作业进行一些内存调优,我注意到不同的设置会给出不同的结果,并影响Spark作业运行的结果。但是,我很困惑,不明白为什么会这样,如果有人能给我一些指导和解释,我会很感激。 我将提供一些背景资料和张贴我的问题和描述案例,我已经经历了他们在下面。 我的环境设置如下: 存储器20G,每个节点20个vCore(共3个节点) Hadoop 2.6.0 火花1.4.0 我的代码对R
-
将线程本地内存刷新到全局内存是什么意思?
问题内容: 我知道Java中的易失性变量的目的是使对此类变量的写入对其他线程立即可见。我还知道,同步块的作用之一是将线程本地内存刷新到全局内存。 在这种情况下,我从未完全理解对“线程本地”内存的引用。我了解仅存在于堆栈中的数据是线程局部的,但是当谈论堆上的对象时,我的理解变得模糊。 我希望能就以下几点发表评论: 在具有多个处理器的计算机上执行时,刷新线程本地内存是否仅是指将CPU缓存刷新到RAM中
-
操作系统中虚拟内存和缓存内存之间的区别
本文向大家介绍操作系统中虚拟内存和缓存内存之间的区别,包括了操作系统中虚拟内存和缓存内存之间的区别的使用技巧和注意事项,需要的朋友参考一下 在这篇文章中,我们将了解操作系统中虚拟内存和缓存内存之间的区别- 高速缓存存储器 它有助于提高CPU的访问速度。 它是提高访问速度的存储单元。 CPU和其他相关硬件有助于管理缓存。 尺寸很小。 它用于存储最近使用的数据。 虚拟内存 它增加了主存储器的容量。 这
-
IE8 内存泄露(内存一直增长 )的原因及解决办法
本文向大家介绍IE8 内存泄露(内存一直增长 )的原因及解决办法,包括了IE8 内存泄露(内存一直增长 )的原因及解决办法的使用技巧和注意事项,需要的朋友参考一下 最近开发的时候对页面使用了定时的局部更新,结果在ie6,7和Firefox下,一切正常,而在ie8下过上几个小时就浏览器就崩溃了,显示是内存溢出,我以为是代码写的不好导致内存泄露,但是ie6,7又正常,调查了一下,原来这是ie8的bug
-
PHP内存不足错误不反映PHP.ini中的内存限制设置
当我尝试使用Composer客户端将软件包安装到Contao时,我收到一个错误: 致命错误:第220行的phar://D:/wamp/www/myproject/composer/composer.phar/src/composer/dependencysolver/Solver.php中允许的内存大小为1073741824字节(尝试分配134217728字节) 我真的很困惑。我的PHP内存限制设
-
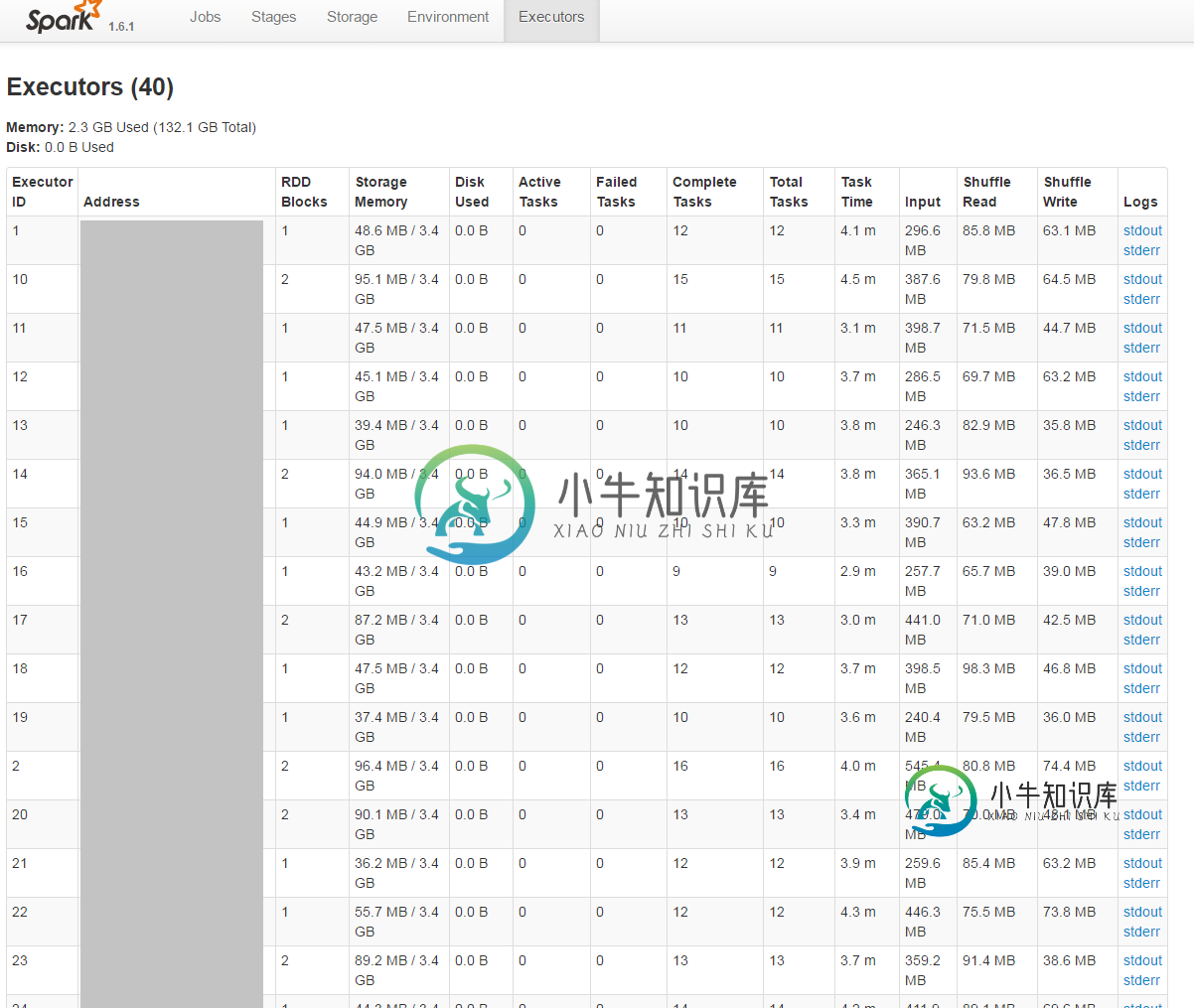 Spark on Yarn:执行器内存少于通过spark-submit设置的内存
Spark on Yarn:执行器内存少于通过spark-submit设置的内存我在纱线簇(HDP 2.4)中使用Spark,设置如下: 1主节点 64 GB RAM(48 GB可用) 12核(8核可用) 每个64 GB RAM(48 GB可用) 每个12核(8核可用) null
-
如何处理Spark中的执行器内存和驱动程序内存?
null null 为了进行简单的开发,我使用在独立集群模式下(8个工作者、20个内核、45.3G内存)执行了我的Python代码。现在我想为性能调优设置执行器内存或驱动程序内存。 在Spark文档中,执行器内存的定义是 每个执行程序进程使用的内存量,格式与JVM内存字符串相同(例如512M、2G)。
-
内容控件绑定丢失内容控件内文本的格式
当我试图将XML与包含带有格式的文本的内容控件的docx绑定时,文本格式(字体类型、字体大小、颜色等)就会丢失。 我正在使用最新的docx4j-3.0.0.jar 有关示例和详细说明,请参见http://www.docx4java.org/forums/data-binding-java-f16/binding-loses-formatting-on-text-inside-content-con
-
调试时检查内存hsqldb
问题内容: 我们在内存中使用hdsqldb运行针对数据库运行的junit测试。在通过弹簧配置运行每个测试之前,已设置数据库。一切正常。现在,当测试失败时,可以方便地检查内存数据库中的值。这可能吗?如果可以,怎么办?我们的网址是: jdbc.url = jdbc:hsqldb:mem:testdb; sql.enforce_strict_size = true 每次测试后,数据库都会被破坏。但是,当
-
64位Java的最大内存
问题内容: 在64位平台上,一个人可以为java分配的最大堆空间是多少?无限吗? 问题答案: 理论上是2 64,但是可能会有限制(显然) 根据此常见问题解答,它仅受本地系统上的内存和交换空间的限制: 在64位VM上,您具有64位可寻址性,因此可产生的最大Java堆大小仅受系统提供的物理内存和交换空间的数量限制。 另请参见为什么使用32位JVM无法获得更大的堆? 另外请记住,您需要通过命令行设置最大