《内存》专题
-
设置pyspark jvm内存(Xmx)
当我运行用pyspark编写的spark作业时,我会运行一个jvm,它的Xmx1g设置似乎无法设置。以下是ps aux的输出: 我的问题是,如何设置此属性?我可以使用SPARK\u DAEMON\u memory和SPARK\u DRIVER\u memory设置主内存,但这不会影响pyspark的派生进程。 我已经尝试了JAVA\u选项,或者实际查看了包的文件,但无法理解这是在哪里设置的。 设置
-
线程消耗的内存
我需要监控应用程序生成的线程所消耗的内存量。如果贪婪的线程占用了太多内存,那么我们可以采取纠正措施。我提到了我的java线程需要多少内存?。关于该链接的建议之一是在ThreadMXBean中使用getThreadAllocatedBytes 我用以下作业试验了getThreadAllocatedBytes。 我在四个线程上运行了相当长的时间。虽然作业不会连续累积内存,但getThreadAlloc
-
点燃堆内存使用
我有一个tomcat用ignite进行会话聚类。我有一个示例登录调用,它为一个用户创建一个会话,在成功登录之后,我看到下面的日志打印出来,其中堆大小波动很大。 我的问题是 为什么整个堆大小是波动的?。 感谢任何指点。 问候你,阿拉温德
-
强制JVM释放内存
我改进了代码,以便从垃圾收集器中获得更好的结果。 现在,当我调用时,它确实释放了所有内存。但是,当我在不调用 的情况下观察内存使用情况时,应用程序确实会保留并使用越来越多的内存。 这是否意味着我的改进正在起作用,我的所有引用都是正确的,我可以忽略JVM是如何自己释放内存的。或者,我的代码中是否存在其他问题,这些问题是JVM在不运行垃圾收集器的情况下保留更多内存的原因。
-
pyspark-Kafka流-内存不足
我正在尝试使用此代码使用代理版本0.10测试kafka流。这只是一个打印主题内容的简单代码。还没什么大不了的!但是,由于某种原因内存不足(VM中的10GB RAM)!代码: 运行火花提交: 不幸的是,结果是: java.lang.OutOfMemoryError:Java堆空间 我假设Kafka每次应该带一小部分数据来避免这个问题,对吗?那么,我做错了什么?
-
优化Node.js内存消耗
不是内存泄漏或类似的问题,因为第一次连接后内存使用量不会增加,所以优化可能是加载更少的模块或做一些不同的事情...
-
Optaplanner内存泄漏问题
我有一个课程调度问题,带有用于分数计算的约束流。当求解分配的堆时,它会不断增加,因此在几个小时后甚至超过8GB,我得到了一个java.lang.OutOfMemoryError:java堆空间。正如optaplanner文档中所述,堆大小在求解器阶段应保持不变。我需要关于这种行为的问题以及如何调试的建议。 optaplanners toList ConstraintCollector中提供的复制器
-
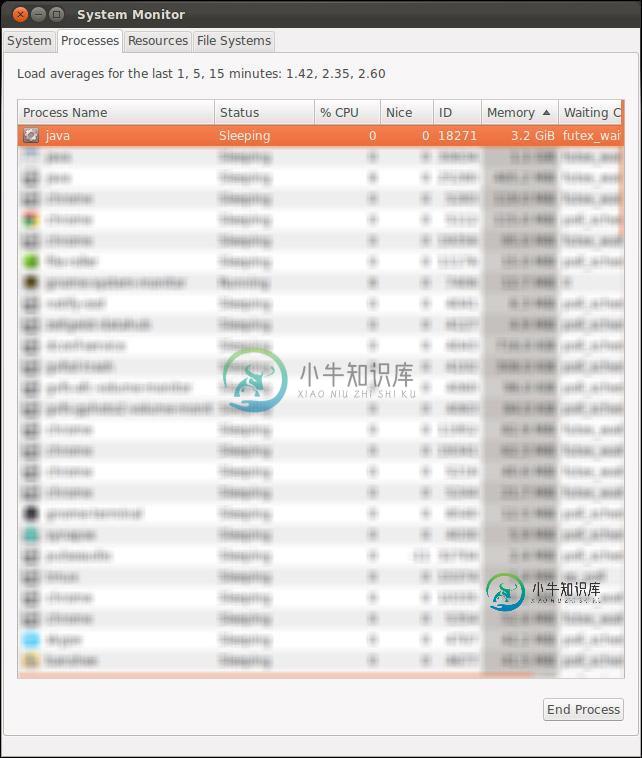 JVM内存使用失控
JVM内存使用失控我有一个Tomcat webapp,它代表客户端执行一些相当大的内存和CPU密集型任务。这是正常的,也是所需的功能。但是,当我运行Tomcat时,内存使用量会随着时间的推移而猛增,达到4.0GB以上,这时我通常会关闭该进程,因为它会扰乱我开发机器上运行的其他所有内容: 我以为我的代码无意中引入了内存泄漏,但在使用VisualVM检查它之后,我看到了一个不同的情况: VisualVM显示该堆占用大约
-
Selenium使用太多内存
我在Python3.5上使用selenium,在ububtu vps上使用chrome webdriver,当我运行一个非常基本的脚本(导航到站点,输入登录字段,单击)时,内存占用增加了400MB,cpu占用增加到100%。我可以做些什么来降低这个数字,或者如果没有的话,有什么其他的办法吗? 我正在python中测试selenium,但我计划在java中使用它进行一个项目,其中内存使用对我来说是一
-
JVM内存不足崩溃
我一直在使用G1垃圾收集器经历Java VM崩溃。我们得到使用以下签名生成的hs_err_pid.log文件:
-
如何增加jvm内存
我想改变(增加)Java内存限制(Windows PC上的JRE)。我到处都遵循以下命令: -xms设置初始Java堆大小 -Xmx设置最大Java堆大小 例如-Xmx1024m。 但我的问题是在哪里!我必须输入这个命令吗?抱歉这个初学者的问题。通常我对java没有任何接触。
-
堆转储!=虚拟内存?
我并不了解Java特别是Java调试,但在Jenkins中使用Monitoring进行堆转储,然后在Eclipse中使用MAT对其进行解码,显示总内存使用量为169.4MB,而在Jenkins中Monitoring似乎经常使用内存,GCs也经常运行。-XMX是4G。 为什么我只有169.4MB的mat?可能是因为在进行转储之前,Jenkins执行了GC吗?如果是,我是否可以避免它以看到完整的内存转
-
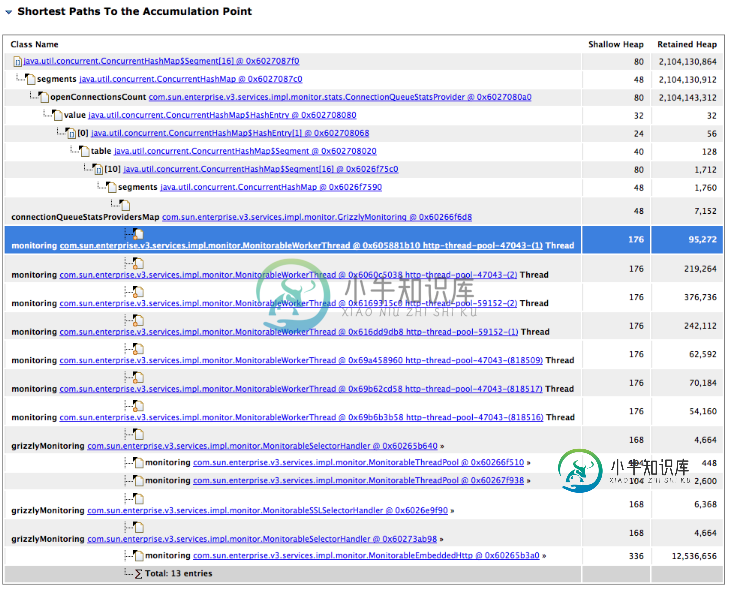 ConnectionQueueStatsProvider内存不足错误
ConnectionQueueStatsProvider内存不足错误上周,我们在生产环境中遇到了内存不足的错误。这种内存不足的错误可能每周发生一次,当前的解决方案是重新启动应用程序服务器。我们使用的是glassfish 3.0.1。生成的堆转储约为5GB。 请帮助分析下面的堆转储。下面是使用eclipse MAT生成的泄漏嫌疑人报告。我们如何分析下面的报告?
-
JavaFx TableView cellFactory内存开销
我的问题与来自JavaFX的TableView有关。JavaFx建议使用属性来存储将在表中显示的值(SimpleSttringProperty等),如下面的示例所示。 这难道不是Java的内存开销(为每个单元格创建另一个对象)吗?我将使用TableView从数据库中显示超过10,000行。难道没有一种方法可以避免这种情况,并像Swing之前那样简单地工作吗?TableView不能只获取要表示的值吗
-
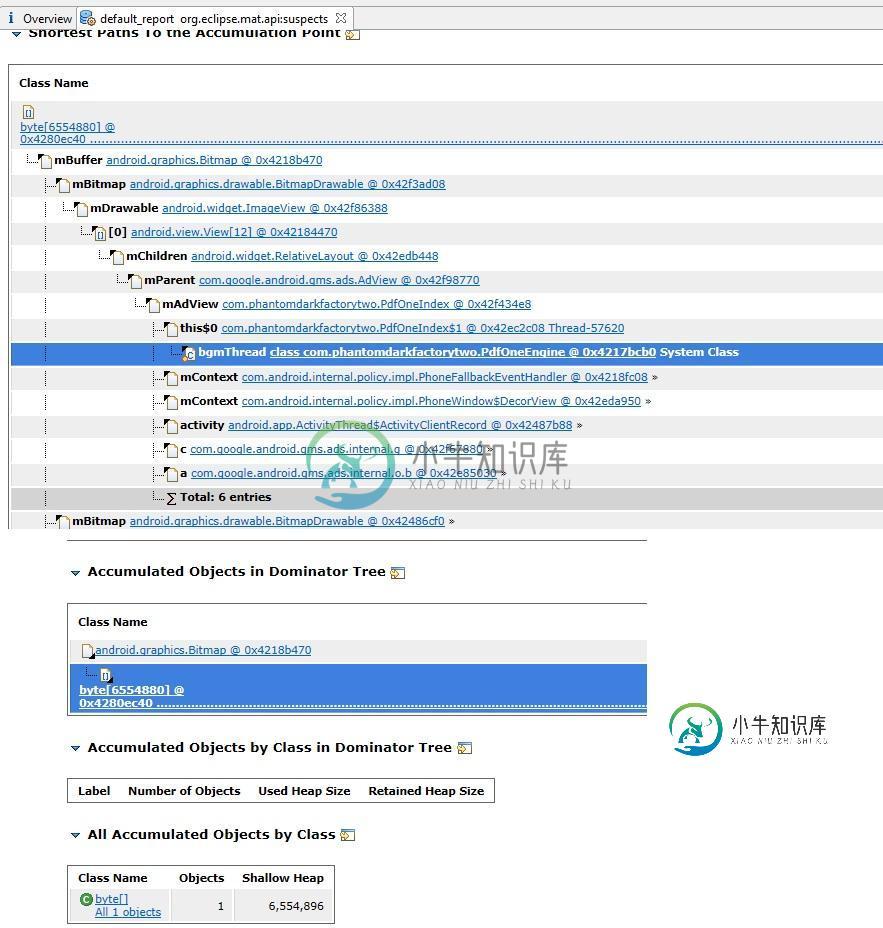 Android内存泄漏位图
Android内存泄漏位图我在继续我的游戏超过8次后,我得到了OutOfMemory错误,因为堆逐渐填充。在使用MAT分析我的游戏堆时,我知道以下2个原因: 关键词Android.Graphics.Bitmap Byte[] 关键词java.lang.Object[]Android.content.res.resources 请提出解决方案