《比亚迪面试》专题
-
Hadoop Classic与纱线的比较
我有两个集群,每个集群运行不同版本的Hadoop。我正在研究一个POC,我需要了解YARN如何提供同时运行多个应用程序的能力,这是用经典的Map Reduce框架无法实现的。 Hadoop Classic:我有一个wordcount.jar文件,并在单个集群上执行(2个映射器和2个简化器)。我并行地开始了两个工作,一个幸运的开始首先得到了两个映射器,完成了任务,然后第二个工作开始。这是预期的行为。
-
如何比较Springmongo的日期
我想在Mongo和Spring中获取结果bw两个日期,但它显示解析异常。 如果我将like date作为字符串传递,则不会有结果。如何比较spring和Mongo应用程序中的日期。 我的收藏:
-
OpenSSL ECDSA签名比预期长
我正在尝试生成“原始”的未编码ECDSA签名,用于加密芯片。目标是在主机pc上签名,然后将其发送到芯片进行验证。然而,我遇到了一个小问题。我的理解是ECDSA签名应该是64字节(对于secp256v1)。而且,当我使用芯片生成签名时,它的长度确实是64字节。然而,当我使用openssl时,签名长度为71字节。签名的开头似乎是某种前缀,但我找不到关于它的任何数据。 以下是我尝试做每件事情的方式: 生
-
在Java8中反转比较器
我有一个ArrayList,需要按降序排序。我用java来实现它。util。流动流动排序(比较器)方法。以下是根据Java API的描述: 返回由该流的元素组成的流,根据提供的
-
Flexbox高度百分比[副本]
我有一个基本的flexbox布局,我正在尝试应用高度百分比,目前他们都占据相同的百分比… 这在FlexBox中是可能的吗?如果是的话,有没有人可以给我一个例子呢?
-
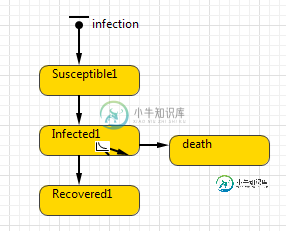 任意逻辑中的比例
任意逻辑中的比例我正在研究一个基于代理的流行病模型。我正在寻找将那些被感染的人的一定比例转移到另一个叫做‘死亡’的州。在AnyLogic中触发这种转变的最佳方式是什么?
-
比较器双倍不工作
我开发了一个程序,它创建一个书籍对象数组,并根据用户输入对它们进行排序。排序选项是author-title-pages-price,除了price排序之外,其他都可以。请帮我找出为什么我不能使用比较器对双打进行排序...我的课本课: 和排序程序:
-
正确使用Cpriority_queue比较器
这个问题最近在一次采访中被问到。 这是我使用的以下方法 1)创建一个最大堆priority_queue来存储最近的点
-
Java比较器排序不同
“StringComparator”在“arrays.sort(b,new StringComparator());”出货量和预期的一样。 但当我使用默认排序(步骤如下),然后按“StringComparator”排序时,bug显示: “Arrays.Sort(a);Arrays.Sort(a,new StringComparator());”
-
PostgreSQL比较两个jsonb对象
对于PostgreSQL(v9.5),JSONB格式提供了极好的机会。但现在我只能做一个相对简单的手术; 比较两个jsonb对象;查看一个文档与另一个文档相比有什么不同或缺失。 到目前为止我所拥有的 应该返回第1行与第2行的差异: 相反,它还返回重复项(
-
为什么recyclerview比listview快[duplicate]
我读到了关于b/w recyclerview和listview的区别,发现RecyclerViewer比listview更快。 我尝试在线搜索,但没有找到任何令人满意的答案,我知道它使用了ViewHolder模式和通知适配器,但它的内在功能是什么,所以它更快?
-
Java PriorityQueue自定义比较器
在我的PriorityQueue中,我有两种类型的客户,即VIP和常规客户。我想先为贵宾服务,再为常客服务。 如果CustomerID<100,则视为VIP。 如果客户是VIP,他会排在队列中VIP部分的最后 更新:我不想排序任何其他列除了VIP。我不想添加“日期”,因为它感觉像是一个黑客,而不是理解Java是如何工作的。
-
比较温特纽扣颜色
我的表单中有四个按钮,其中四个按钮(btn2 btn3 btn4)有相同的颜色。 单击btn1时,它将检查btn2 btn3和btn4是否具有相同的颜色,而无需明确说明要比较的颜色。但我的情况似乎不对,我应该说这个 我使用的代码是:
-
CommonModule与BrowserModule的角度对比
我对这个世界很陌生。和之间有什么区别?为什么一个模块比另一个更可取?
-
向量如何比向量“重”?
在最近的一次采访中,我建议使用向量 编码过程结束后,他们说在向量上使用pair是个好主意,并要求我详细说明我之前所说的“更重”是什么意思。不幸的是,我无法详细说明。是的,我知道我们只能在一对中输入两个值,但在一个向量中可以输入更多的值,并且当向量的大小==容量等时,该向量会自动调整大小。但是我应该如何回答他们的问题?为什么具体使用<代码>向量