《搜狐面经》专题
-
1.3.2.3 网站概况(来源网站、搜索词、入口页面、受访页面)
网站概况(来源网站、搜索词、入口页面、受访页面) 关键参数 报告 method metrics(指标, 数据单位) 其他参数 网站概况(来源网站、搜索词、入口页面、受访页面) overview/getCommonTrackRpt pv_count (浏览量(PV)) 无 示例 查看网站概况 百度商业账号 请求 { "header": { "username": "zhang
-
PHP的MySQL全文搜索:Lucene,狮身人面像,还是?
问题内容: 诚然,这 与 全文搜索引擎比较-Lucene,Sphinx,Postgresql,MySQL 类似 (但不是重复)。,但是我正在寻找的是针对特定的,受支持的建议,这些建议是从不止一个可用系统的经验中受益的(似乎有很多:“我使用了lucene,但没有使用狮身人面像”,反之,反之亦然。 设置:标准LAMP(MySQL 5.0,PHP 5)。 MySQL:表将InnoDB引擎用于外键约束 我
-
MediaWiki API搜索具有特定模板的页面标题
有没有办法通过标题和模板查询MediaWiki/Wikipedia页面? 例如,我想知道是否有一个页面的标题为“someperson”,并且包含“Template:Persondata”。 我知道如何按标题查询:http://en.wikipedia.org/w/api.php?action=query 多亏了这一点,我知道如何搜索所有使用特定模板的页面:http://en.wikipedia.o
-
 字节跳动 计算机视觉算法 - 搜索 一面
字节跳动 计算机视觉算法 - 搜索 一面总共1h 看的出来,面试之前面试官都没看过我的简历。聊了10分钟就开始做题,反转链表写了二十多分钟没做出来,最长递增子序列分别用贪心和动态规划写出来了,后面问了一点深度学习的八股,感觉方向不是很对口,大概率凉了。 1. 介绍一下实习做的工作 2. 反转链表,每n个反转一次 3. 最长递增子序列 4. 写一下交叉熵 5. 为什么分类损失不用MSE 6. 多头自注意力中的头从8个变为16个,计算量怎么
-
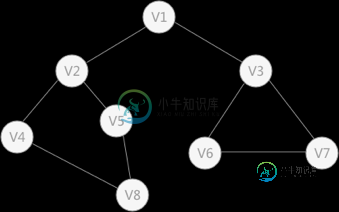 深度优先搜索和广度优先搜索
深度优先搜索和广度优先搜索主要内容:深度优先搜索(简称“深搜”或DFS),广度优先搜索,总结前边介绍了有关图的 4 种存储方式,本节介绍如何对存储的图中的顶点进行遍历。常用的遍历方式有两种: 深度优先搜索和 广度优先搜索。 深度优先搜索(简称“深搜”或DFS) 图 1 无向图 深度优先搜索的过程类似于树的先序遍历,首先从例子中体会深度优先搜索。例如图 1 是一个无向图,采用深度优先算法遍历这个图的过程为: 首先任意找一个未被遍历过的顶点,例如从 V1 开始,由于 V1 率先访问过了,所以
-
Liferay搜索未给出同义词搜索结果?
我们在Liferay DXP和Elasticsearch 2.2.0中有一个自定义搜索portlet。我们在elasticsearch设置中为同义词搜索添加了以下设置。 我们还使用以下代码验证是否将同义词分析器添加到索引中。 这给出了synonyms.txt文件中“acl”的所有同义词的结果。但是Liferay搜索不会给搜索匹配同义词。例如:搜索(“acl”)=
-
嵌套数组的弹性搜索搜索查询
如何获得空数组和美国的结果和
-
按路径搜索文件的 RubyMine 搜索项目
在SublimeText 2中,我可以执行以下操作:<code>cmd t</code> 然后键入文件名或文件夹名,显示的结果是与我正在搜索的术语匹配的文件,以及位于我正在搜索的术语的子文件夹中的文件,例如,如果我的目录结构如下所示: 我可以做命令 和类型和唯一的两个选项,将显示将是和文件,我可以键向下导航或键入添加更多的搜索词和唯一的选项将是 如何在RubyMine中获得相同的功能
-
使用深度优先搜索的单词搜索
我在处理一个单词搜索问题。我正确地实现了dfs搜索,但在其他地方有一些琐碎的错误。
-
如何在Hibernate搜索中搜索特殊字符?
我刚开始使用hibernate lucene搜索。从几天以来,我一直致力于搜索关键字与特殊字符。我正在使用MultiFieldQueryParser进行精确短语匹配以及布尔搜索。但在这个过程中,我无法得到搜索关键字的结果,如“有1年以上的经验”,如果我没有在搜索关键字周围添加任何引号,那么我就得到了结果。所以我在执行lucene查询时观察到的是,它正在转义特殊符号(+)。我正在使用Standard
-
浅析基于WEB前端页面的页面内容搜索的实现思路
本文向大家介绍浅析基于WEB前端页面的页面内容搜索的实现思路,包括了浅析基于WEB前端页面的页面内容搜索的实现思路的使用技巧和注意事项,需要的朋友参考一下 在网页做查询以前都是这么做的 表单获取关键字 –> 传入后端SQL语句处理 –>数据返回给前端显示 今天突然到游览器的Ctrl+F的这个功能怎么实现的,把数据一次放在页面上,然后在用JS 去匹配页面的内容。 不管怎么样,现在完成了功能,然
-
WebDriverWait +搜索项目
问题内容: 创建激活码后,需要1至60秒的时间将代码上传到系统中。因此,在创建新代码之后,我想使用WebDriverWait 60秒钟来确保,并且在此时间段内每3秒钟我要单击“搜索按钮”。有什么办法吗? 问题答案: 附带“免费” 。 您可以在创建时设置一个值,以告诉它应该多久尝试运行一次代码(单击搜索按钮): http://selenium.googlecode.com/git/docs/api/
-
ElasticSearch全文搜索
问题内容: 我尝试在elasticsearchJava API上使用正则表达式运行全文搜索。我的过滤器是这样的: 但是它只与一个单词匹配,而没有短语匹配。我的意思是,例如: 如果soruce中有一个字符串,例如:“ ”,而当我的文本字符串如下:“ ”,“ ”,“ ” …时,它就起作用了。 但是,当我的realTimeTextIn字符串为“ ”时,全文搜索将不起作用。我搜索的单词不能超过一个。 我在
-
ElasticSearch搜索性能
问题内容: 我们有两个节点的集群(私有云中的VM,64GB的RAM,每个节点8个核心CPU,CentOS),几个小索引(约100万个文档)和一个大索引,约有2.2亿个文档(2个分片,170GB)的空间)。每个盒上分配了24GB的内存用于elasticsearch。 文件结构: 运行以下查询大约需要1-2秒: 我们是在此时达到硬件极限,还是有办法优化查询或数据结构以提高性能? 提前致谢! 问题答案:
-
ElasticSearch-搜索人名
问题内容: 我有一个很大的名字数据库,主要来自苏格兰。我们目前正在生产一个原型,以替换执行搜索的现有软件。这仍在生产中,我们的目标是使我们的结果尽可能接近同一搜索的当前结果。 我希望有人可以帮助我,我正在对Elastic Search进行搜索,查询是“ Michael Heaney”,我得到了一些疯狂的结果。当前搜索返回两个主要的姓,分别是“ Heaney”和“ Heavey”,都以“ Micha