《大三实习》专题
-
opencv 查找连通区域 最大面积实例
本文向大家介绍opencv 查找连通区域 最大面积实例,包括了opencv 查找连通区域 最大面积实例的使用技巧和注意事项,需要的朋友参考一下 今天在弄一个查找连通的最大面积的问题。 要把图像弄成黑底,白字,这样才可以正确找到。 然后调用下边的方法: RETR_CCOMP:提取所有轮廓,并将轮廓组织成双层结构(two-level hierarchy),顶层为连通域的外围边界,次层位内层边界 方法二
-
js图片放大镜实例讲解(必看篇)
本文向大家介绍js图片放大镜实例讲解(必看篇),包括了js图片放大镜实例讲解(必看篇)的使用技巧和注意事项,需要的朋友参考一下 1、图片放大镜的思路: 当打开页面时只有图片 首先,说一下基本效果和调理,图片放大镜,也就是当你鼠标移入当前的商品图片时,会出现一个小灰色的观察移动框,有点会出现一个对应部位的放大的图片。 然后当鼠标移动时,右边的放大镜会出现对应部位的放大图片 最后当鼠标移开后,小的观察
-
为什么调整大小是这样实现的?
在添加新的键值对时,我有几个关于重建哈希映射的问题。我将根据这些事实提出问题(它们对于Oracle JVM是正确的,不确定它们对于其他JVM是否正确): 每次当HashMap增长大于阈值(阈值=加载因子*条目数)时,Resize将重建HashMap,使其具有更大的内部表数组。新创建的条目放在哪个存储桶中并不重要,Map仍然会变得更大。即使所有条目都进入一个bucket(即它们的键“返回相同的数字)
-
Redis获取某个大key值的脚本实例
本文向大家介绍Redis获取某个大key值的脚本实例,包括了Redis获取某个大key值的脚本实例的使用技巧和注意事项,需要的朋友参考一下 1、前言 工作中,经常有些Redis实例使用不恰当,或者对业务预估不准确,或者key没有及时进行处理等等原因,导致某些KEY相当大。 那么大Key会带来哪些问题呢? 如果是集群模式下,无法做到负载均衡,导致请求倾斜到某个实例上,而这个实例的QPS会比较大,内存
-
 Python 实现 贪吃蛇大作战 代码分享
Python 实现 贪吃蛇大作战 代码分享本文向大家介绍Python 实现 贪吃蛇大作战 代码分享,包括了Python 实现 贪吃蛇大作战 代码分享的使用技巧和注意事项,需要的朋友参考一下 感觉游戏审核新政实施后,国内手游市场略冷清,是不是各家的新游戏都在排队等审核。媒体们除了之前竞相追捧《Pokemon Go》热闹了一把,似乎也听不到什么声音了。直到最近几天,突然听见好几人都提到同一个游戏,网上还有人表示朋友圈被它刷屏了。(不过现在微信
-
在MySQL SELECT语句中实现区分大小写
本文向大家介绍在MySQL SELECT语句中实现区分大小写,包括了在MySQL SELECT语句中实现区分大小写的使用技巧和注意事项,需要的朋友参考一下 SELECT默认情况下不区分大小写。对于区分大小写的实现,使用BINARY运算符。以下是语法: 让我们首先创建一个表- 使用插入命令在表中插入一些记录- 使用select语句显示表中的所有记录- 这将产生以下输出- 以下是区分大小写的选择查询-
-
为什么类大多通过函数实例化?
为了科学目的,我已经使用python好几年了。最近我对类的编写更加熟悉了,但我觉得我缺少了一些关于实例化类的标准方法。 假设我定义了一个类。 然后我知道我可以用 这很好,完全符合我的预期。 然而,在我看来,当我使用标准库或或中的代码时,我不会以相同的方式创建对象:据我所知,我通常不会使用类的名称来实例化它。据我所知,这意味着我既不使用类方法,也不使用类的默认构造函数,而是使用在类之外定义的其他函数
-
使用MMU实现可调整大小的数组
通常,列表可以实现为链表(遍历速度较慢),也可以实现为数组列表(插入元素时速度较慢)。 我想知道是否有可能使用处理器的MMU来更有效地实现列表,只要插入或删除一个元素,就可以重新映射而不是复制内存。这意味着数组中任何地方的索引和插入/删除速度都要达到O(1),比任何其他列表实现都要好。 我的问题是: 程序是否真的能够控制自己的虚拟内存,或者是否需要对操作系统进行更改 每个进程的页表条目数是否有限制
-
Bluemix节点红色错误:请求实体太大
我一直在尝试将base64数据发送到bluemix中的节点red 但是它声明我的文件请求实体太大。。。 我一直在找。。。。bodyparser模块能处理这个问题吗?或者,有什么解决方案比更改代码更容易,因为我无法下载启动程序代码来操作,因为它会将我重定向到主页 非常感谢。
-
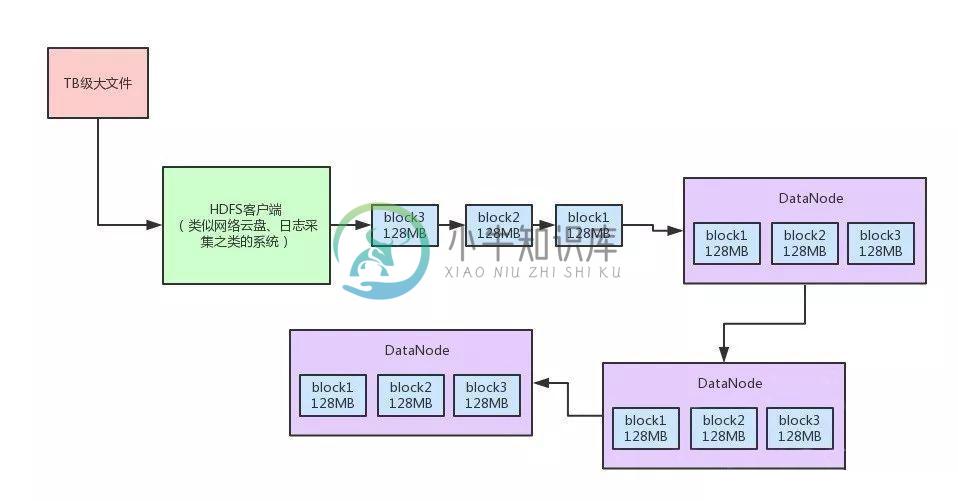 Hadoop的TB级大文件上传优化实践!
Hadoop的TB级大文件上传优化实践!主要内容:一、写在前面,二、原始的文件上传方案,三、HDFS对大文件上传的性能优化,1. Chunk缓冲机制,2. Packet数据包机制,3. 内存队列异步发送机制,四、总结一、写在前面 上一篇文章,我们聊了一下Hadoop中的NameNode里的edits log写机制。 主要分析了edits log写入磁盘和网络的时候,是如何通过分段加锁以及双缓冲的机制,大幅度提升了多线程并发写edits log的吞吐量,从而支持高并发的访问。 如果没看那篇文章的同学,可以回看一下:《每秒上千次高并发访问
-
HashSet的最大大小
问题内容: 所以基本上我正在生成随机的10000个IP地址,我想存储在HashSet中找到的所有那些IP地址,但是根据我的计算,发现了大约6000个IP地址,但是在HashSet中仅存储了700个IP地址?HashSet在存储String方面是否有任何限制。任何建议将不胜感激。 问题答案: 就您而言,没有限制(限制是数组的最大大小,即2 ** 31)。 但是,仅存储 唯一 值,因此我的猜测是您仅生
-
JavaFX:最大ImageView大小
这听起来可能像是JavaFX ImageView设置的最大大小的重复,但它是不同的。 我想限制ImageView的最大大小。不幸的是,设置ImageView大小的唯一方法似乎是fitWidth和fitHeight,但是如果图像小于配合值,则会放大图像。 我尝试将fitWidth/fitHeight设置为0/0,并将ImageView包装到设置了maxWidth的窗格中-没有成功(图像以原始大小显示
-
StringBuffer的最大大小
问题内容: 为什么会限制其大小? 我浏览了一些链接:http : //www.coderanch.com/t/540346/java/java/maximum-size-hold- String-buffer 。 是因为count成员变量是int吗? 假设我们有2 ^ 31-1个字符,并在其中追加了一些字符。Count成员变量将增加附加的字符数,如果Count变量已经达到最大值(2 ^ 31-1)
-
Docker: Overlay2大小太大
我用两个容器运行docker的环境。我注意到Overly2文件夹太大了。当docker关闭(docker compose down)时,Overly2文件夹的大小为2.3GB。当容器运行时,Overly2文件夹将增加到4.0GB,并且随着时间的推移而增加。这正常吗? 命令停止容器: 命令,容器运行: 编辑 命令
-
Intellij堆大小,初始堆大小设置为大于最大堆大小的值
我是Java的初学者,刚开始使用Intellij作为我的IDE。 当我使用它时,有时会延迟。 我更改了我的 xms 和 xmx 以获得更大的堆大小(xms = 1024,xmx = 2048),但它抛出了一个错误。 所以,我把它回滚了。 错误消息是这样的:“初始堆大小设置为大于最大堆大小的值”。 有什么问题? 如果可能,如何增加最大堆大小? 我用的是笔记本电脑,它有8GB内存。x64Intelli