《C语言开发》专题
-
详解django中Template语言
本文向大家介绍详解django中Template语言,包括了详解django中Template语言的使用技巧和注意事项,需要的朋友参考一下 Django是一个开放源代码的Web应用框架,由Python写成。采用了MTV的框架模式,即模型M,视图V和模版T。它最初是被开发来用于管理劳伦斯出版集团旗下的一些以新闻内容为主的网站的,即是CMS(内容管理系统)软件。并于2005年7月在BSD许可证下发布。
-
Python 语言嵌套集合
本文向大家介绍Python 语言嵌套集合,包括了Python 语言嵌套集合的使用技巧和注意事项,需要的朋友参考一下 示例 导致: 而是使用frozenset:
-
更改DecimalFormat语言环境
问题内容: 我在Edittext的addTextChangedListener方法中已自定义,一切正常,但是当我更改语言(语言环境)时,我的addTextChangedListener无法正常工作。 我搜索了我的问题并找到了解决方案: 但我不知道如何使用此代码。 问题答案: 您可以尝试先转换为,然后将其投射到
-
AJAX的Java语言版本
问题内容: 当我只想使用AJAX时,如何消除下载完整的jquery库的需要。是否有一个较小的文件专注于AJAX,还是此代码的Vanilla Javascript版本? 问题答案: 您可以尝试使用 XMLHttpRequest, 如下所示。 演示: https : //www.w3schools.com/js/tryit.asp?filename=tryjs_ajax_first 参考: https
-
 Thymeleaf Spring表达式语言
Thymeleaf Spring表达式语言本文章将介绍Thymeleaf Spring表达式语法中的概念。 Spring Expression Language(简称SpEL)是一种强大的表达式语言,支持在运行时查询和操作对象图。 语言语法类似于Unified EL,但提供了额外的功能,特别是方法调用和基本的字符串模板功能。 Spring表达式语言的创建旨在为Spring社区提供单一支持的表达式语言。 它的语言特性是由Spring项目中的
-
R语言卡方检验
主要内容:语法,示例卡方检验是一种统计方法,用于确定两个分类变量之间是否具有显着的相关性。 这些变量应该来自相同的人口,它们应该是分类的,如 - 是/否,男/女,红/绿等。 例如,我们可以建立一个数据集,观察人们的冰淇淋购买模式,并尝试将一个人的性别与他们喜欢的冰淇淋的味道相关联。 如果发现相关性,我们可以通过了解访问者的性别数量来调整对应口味的库存。 语法 执行卡方检验的函数是:。 在R中创建卡方检验的基本语法是
-
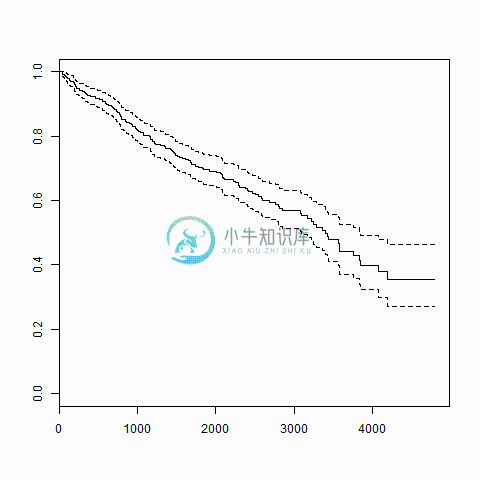 R语言生存分析
R语言生存分析主要内容:安装包,示例,应用Surv()和survfit()函数生存分析涉及预测特定事件发生的时间。 它也被称为失败时间分析或分析死亡时间。 例如预测癌症患者的生存天数或预测机械系统出现故障的时间。 R中的软件包:用于进行生存分析。该包中含有函数,它将输入数据作为R公式,并在所选变量中创建一个生存对象进行分析。然后使用函数来创建分析图。 安装包 语法 在R中创建生存分析的基本语法是 - 以下是使用的参数的描述 - time - 是直到事件发生的后续时间。 ev
-
R语言随机森林
主要内容:安装R包 - randomForest,语法,示例在随机森林方法中,创建了大量的决策树。每个观察结果都被送入每个决策树。 每个观察结果最常用作最终输出。对所有决策树进行新的观察,并对每个分类模型进行多数投票。 对于在构建树时未使用的情况进行错误估计。 这被称为OOB(Out-of-bag)错误估计,以百分比表示。 R中的软件包用于创建随机林。 安装R包 - randomForest 在R控制台中使用以下命令安装软件包,还必须安装其它依赖软件包(如
-
R语言泊松回归
主要内容:语法,示例泊松回归涉及回归模型,其响应变量是计数形式而不是分数数字。 例如,计算出生人数或一个足球比赛系列中的胜率数。响应变量的值也遵循泊松分布。 泊松回归的一般数学方程为 - 以下是使用的参数的描述 - y - 是响应变量。 a 和 b 是数字系数。 x - 是预测变量。 用于创建泊松回归模型的函数是函数。 语法 实现泊松回归的函数的基本语法是 - 以下是上述函数中使用的参数的描述 - formula -
-
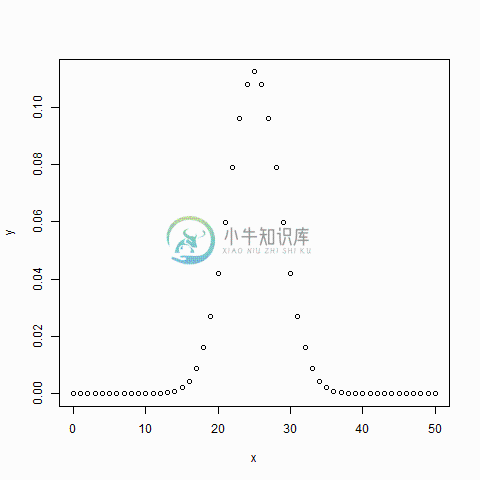 R语言二项分布
R语言二项分布主要内容:1.dbinom()函数,2.pbinom()函数,3.qbinom()函数,4.rbinom()函数二项分布模型用来处理在一系列实验中只发现两个可能结果的事件的成功概率。 例如,掷硬币总是两种结果:正面或反面。使用二项式分布估算在重复抛掷硬币次时正好准确地找到次是正面的概率。 R具有四个内置函数来生成二项分布,它们在下面描述。 以下是使用的参数的描述 - x - 是数字的向量。 p - 是概率向量。 n - 是观察次数。 size - 是试验的次数。 prob - 是每次试验成功的概
-
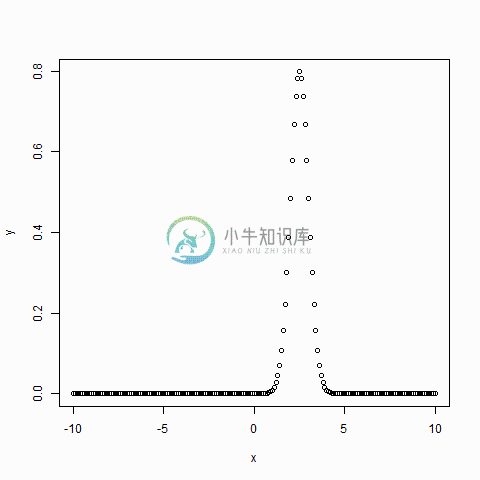 R语言正态分布
R语言正态分布在随机收集来自独立来源的数据中,通常观察到数据的分布是正常的。 这意味着,在绘制水平轴上的变量的值和垂直轴中的值的计数时,我们得到一个钟形曲线。 曲线的中心代表数据集的平均值。 在图中,百分之五十的值位于平均值的左侧,另外五十分之一位于图的右侧。 统称为正态分布。 R有四个内置函数来生成正态分布。它们在下面描述 - 以下是上述函数中使用的参数的描述 - x - 是数字的向量。 p - 是概率向量。
-
R语言逻辑回归
主要内容:语法,示例,创建回归模型逻辑回归是一种回归模型,其响应变量(因变量)具有分类值,如或。 它实际上是根据与预测变量相关的数学方程,来衡量二进制响应的概率作为响应变量的值。 逻辑回归的一般数学方程为 - 以下是使用的参数的描述 - y - 是响应变量。 x - 是预测变量。 a 和 b 是数字常数的系数。 用于创建回归模型的函数是函数。 语法 用于计算逻辑回归的函数的基本语法是 - 以下是使用的参数的描述 - formula
-
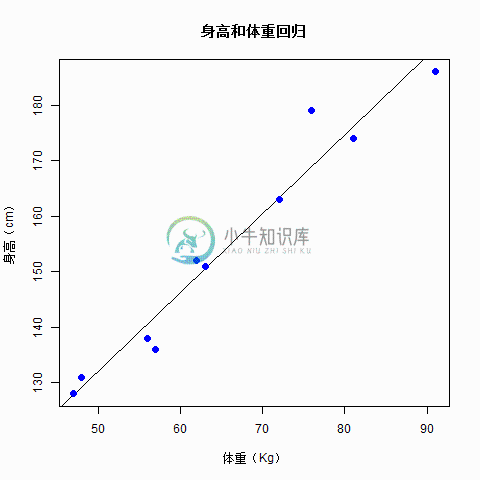 R语言线性回归
R语言线性回归主要内容:建立回归的步骤回归分析是一个广泛使用的统计工具,用于建立两个变量之间的关系模型。 这些变量之一称为预测变量,其值通过实验收集。 另一个变量称为响应变量,其值来自预测变量。 在线性回归中,这两个变量通过一个等式相关联,其中这两个变量的指数(幂)是。数学上,当绘制为图形时,线性关系表示直线。任何变量的指数不等于的非线性关系产生曲线。 线性回归的一般数学方程为 - 以下是使用的参数的描述 - y - 是响应变量。 x
-
R语言数据重塑
主要内容:在数据框中连接列和行,合并数据帧,拆分数据和重构数据,拆分数据,重构数据R中的数据重整是关于将数据组织成行和列的方式。 R中的大多数时间数据处理是通过将输入数据作为数据帧来完成的。 很容易从数据帧的行和列中提取数据,但是有些情况下,我们需要的格式与收到的格式不同。 R具有许多函数,用于在数据帧中拆分,合并和更改行到列,反之亦然。 在数据框中连接列和行 我们可以使用函数连接多个向量来创建数据帧。也可以使用函数合并两个数据帧。 当我们执行上述代码时,会产生以下结果 - 合
-
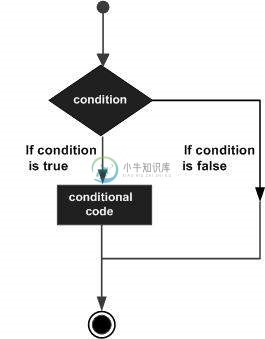 R语言决策结构
R语言决策结构决策结构要求程序员指定要由程序评估计算或测试的一个或多个条件,以及如果条件被确定为真(),则执行指定的一个或多个语句;可选地,如果条件被确定为假()则执行其他语句。 以下是大多数编程语言中的典型决策结构的一般形式 - R提供以下类型的决策语句。可通过单击以下链接来查看其详细信息。 序号 语句 说明 1 if语句 一个语句由一个布尔表达式,后跟一个或多个语句组成。 2 if…else语句 一个语句可