《邮储软开》专题
-
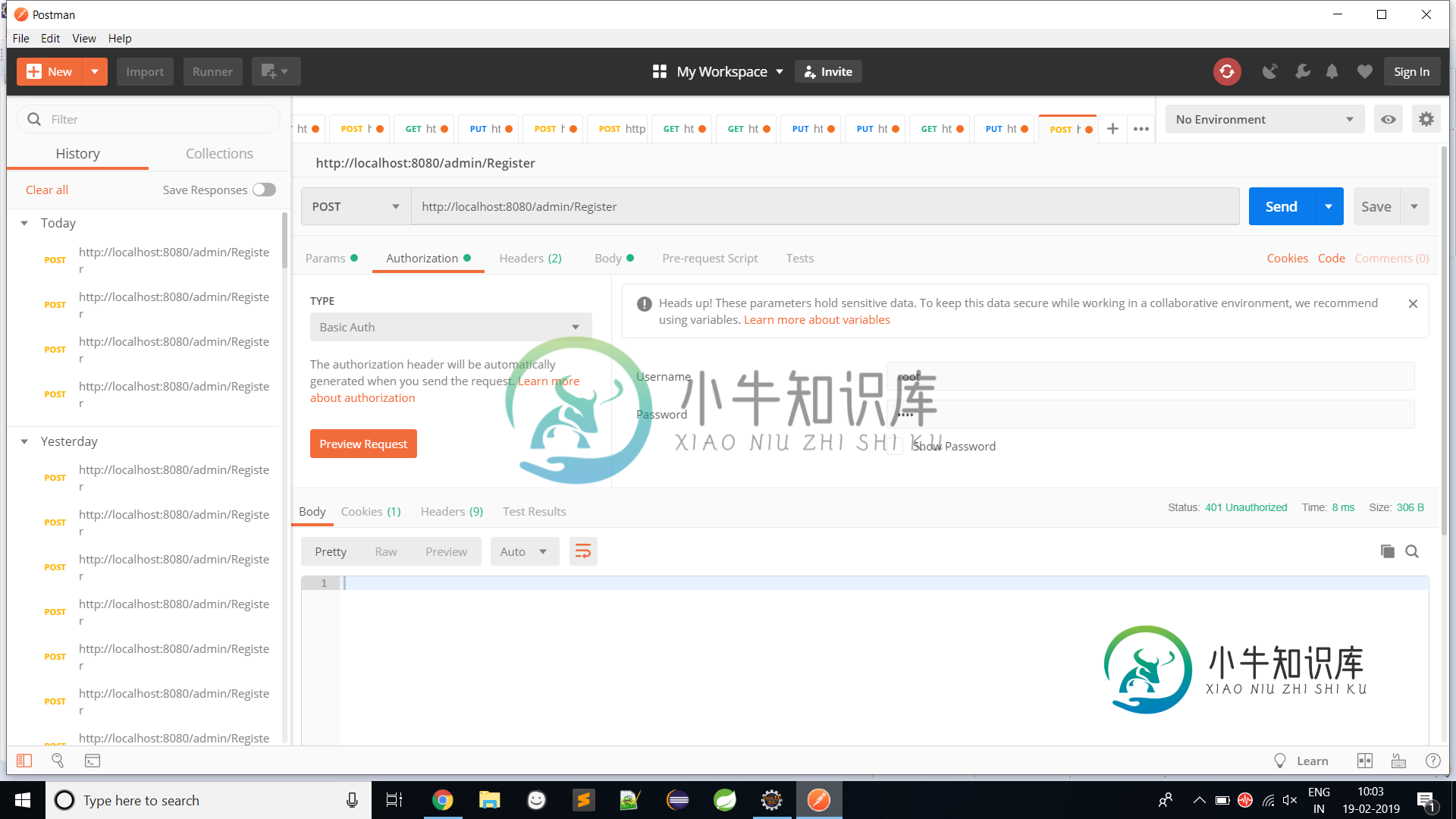 Spring开机安全-邮递员给401未经授权
Spring开机安全-邮递员给401未经授权我正在Spring Boot中开发rest API。我能够进行CRUD操作并且邮递员给出正确的响应,但是当我添加Spring Security用户名和密码时,邮递员给出了401未经授权。 我提供了spring boot安全用户名和密码,如下所示。 应用道具 我已经完成了基本的身份验证,用户名是root,密码是root。预览请求提供成功更新的标题消息: 编辑我已经删除了邮递员中的cookie,但仍然
-
存储MySQL GUID / UUID
问题内容: 这是将UUID()生成的MySQL GUID / UUID转换为二进制文件(16)的最佳方法: 然后将其存储在BINARY(16)中 我应该知道以这种方式进行操作有什么影响? 问题答案: 含义不多。它会稍微减慢查询速度,但是您几乎不会注意到它。 无论如何都存储为内部。 如果要将二进制文件加载到客户端中并在客户端进行解析,请注意,它可能具有除initial之外的其他字符串表示形式。 的函
-
事务存储器
本文向大家介绍事务存储器,包括了事务存储器的使用技巧和注意事项,需要的朋友参考一下 事务性内存起源于数据库理论,它为进程同步提供了另一种策略。 内存事务是原子的,是一系列内存读写操作。如果事务中的所有操作都已完成,则将提交内存事务。否则,必须中止操作并回滚。可以通过添加到编程语言中的功能来获得事务存储的便利性。考虑一个例子。假设我们有一个修改共享数据的函数。传统上,此功能将使用互斥锁(或信号量)编
-
存储Python字典
问题内容: 我习惯于使用.csv文件将数据导入和导出Python,但这存在明显的挑战。关于在json或pck文件中存储字典(或字典集)的简单方法有何建议?例如: 我想知道如何保存此内容,然后如何将其重新加载。 问题答案: 泡菜 保存: 有关该参数的其他信息,请参见pickle模块文档。 酸洗 负荷: JSON 保存: 提供额外的参数,例如或以获得漂亮的结果。参数 sort_keys 将按字母顺序对
-
MySQL查询转储
问题内容: 可以单身吗? 我的意思是转储 整个 数据库,就像导出到 问题答案: 不是mysqldump,而是mysql cli … 您可以根据需要将其重定向到文件中: 更新:原始帖子询问他是否可以通过查询从数据库中转储。他问的和他的意思是不同的。他真的只想mysqldump所有表。
-
MySQL存储函数
存储函数和存储过程一样,都是在数据库中定义一些 SQL 语句的集合。存储函数可以通过 return 语句返回函数值,主要用于计算并返回一个值。而存储过程没有直接返回值,主要用于执行操作。 在 MySQL 中,使用 CREATE FUNCTION 语句来创建存储函数,其语法形式如下: CREATE FUNCTION sp_name ([func_parameter[...]]) RETURNS ty
-
MySQL存储过程
我们前面所学习的 MySQL 语句都是针对一个表或几个表的单条 SQL 语句,但是在数据库的实际操作中,经常会有需要多条 SQL 语句处理多个表才能完成的操作。 例如,为了确认学生能否毕业,需要同时查询学生档案表、成绩表和综合表,此时就需要使用多条 SQL 语句来针对这几个数据表完成处理要求。 存储过程是一组为了完成特定功能的 SQL 语句集合。使用存储过程的目的是将常用或复杂的工作预先用 SQL
-
代号一存储
在无法让sqlite与我的解决方案一起工作后,我决定尝试一下存储类。我已经按照下面的说明进行了操作:https://www.codenameone.com/how-do-i----store-data-to-persistent-storageExternalization.html,并设法将我的数据放入持久存储中。现在我有以下问题: 谢谢
-
 OpenCV存储图像
OpenCV存储图像主要内容:Mat类,方法和描述,创建和显示矩阵,使用JavaSE API加载图像要拍摄图像,我们可使用相机和扫描仪等设备。 这些设备记录图像的数值(例如:像素值)。 OpenCV是一个处理数字图像的库,因此需要存储这些图像进行处理。 OpenCV库的类用于存储图像的值。它代表一个维数组,用于存储灰度或彩色图像,体素体积,矢量场,点云,张量,直方图等图像数据。 这个类包含两个数据部分:头部()和一个指针() 头部 - 包含大小,用于存储的方法和矩阵地址(大小不变)等信息。 指针
-
自定义存储
如果你需要提供自定义文件存储 – 一个普遍的例子是在某个远程系统上储存文件 – 你可以通过定义一个自定义的储存类来实现。你需要遵循以下步骤: 1. 你的自定义储存类必须是django.core.files.storage.Storage的子类: from django.core.files.storage import Storage class MyStorage(Storage):
-
从sqlalchemy转储csv
问题内容: 由于某些原因,我想以csv文件的形式从数据库(sqlite3)中转储表。我正在使用带有elixir的python脚本(基于sqlalchemy)来修改数据库。我想知道是否有任何方法可以转储用于csv的表。 我看过sqlalchemy序列化器,但这似乎不是我想要的。我做错了吗?我应该在关闭sqlalchemy会话以转储到文件后调用sqlite3 python模块 吗?还是我应该使用自制的
-
Git部分存储
本文向大家介绍Git部分存储,包括了Git部分存储的使用技巧和注意事项,需要的朋友参考一下 示例 如果您只想存储工作集中的一些差异,则可以使用部分存储。 然后以交互方式选择要存储的块。 从2.13.0版开始,您还可以避免使用交互模式,并使用新的push关键字使用pathspec创建部分存储。
-
Dapper.NET 存储过程
本文向大家介绍Dapper.NET 存储过程,包括了Dapper.NET 存储过程的使用技巧和注意事项,需要的朋友参考一下 示例 简单使用 Dapper完全支持存储的proc: 输入,输出和返回参数 如果您想要更精美的东西,可以执行以下操作: 表值参数 如果您有一个接受表值参数的存储过程,则需要传递一个数据表,该表的结构与SQL Server中的表类型相同。这是表类型和使用它的过程的定义: 要从c
-
Firebase存储构件
-
Firebase存储安全
所以我想知道,如果我将一个UUID作为后修复添加到文件路径(我现在这样做是为了唯一性,),它是否可以作为一种通过模糊来实现安全的方法呢?(这将是非常困难的野蛮猜测,使某种“私人”文件)。 我知道这不是很理想,但至少在Firebase为这种场景实现更好的解决方案之前,这是暂时的事情,并且能够在晚上睡得更好:p 我的想法是设置如下内容: null