《中国农业银行广州》专题
-
 广州Java某小厂电话面经
广州Java某小厂电话面经自我介绍 ==和equals()有什么区别? String变量直接赋值和构造函数赋值==比较相等吗? String一些方法? 抽象类和接口有什么区别? Java容器有哪些? List、Set还有Map的区别? 线程创建的方式? Runable和Callable有什么区别? 启动一个线程是run()还是start()? 介绍Spring IOC和Spring Aop? Spring框架使用到的设计模
-
 广州应届实习前端面经
广州应届实习前端面经大家觉得难度合适吗 #前端# #前端面经#
-
 广州——前端开发面试经历
广州——前端开发面试经历#我的实习求职记录# 面试题记录: 非技术相关: 说下js的数据类型 前端开发中有几种数据存储方式?各有什么区别? js数组方法的使用:用js代码以实现相应的功能? js中宏任务和微任务有哪些?分别怎么运行的?(js运行机制) TCP/IP协议的原理是什么?客户端与服务器怎么通信的?其过程中三次握手的每阶段含义是什么? Vue中的常用的几个方法有哪些? 比如:v-model/v-for等等? Vu
-
Django管理员内联中的“国家/州/城市”下拉菜单
问题内容: 我有一个按BusinessBranch模型输入的城市外键。我的城市模型还具有州和县模型的州和国家外键。我很难在BusinessBranchInline中显示州和国家/地区下拉菜单。实现这一目标的最佳方法是什么?如果下拉列表根据其父项的值过滤项目,那就太好了。 问题答案: 有了一点黑客,这是相当可行的。 在以下示例中,使用County代替State和Municipality代替City。
-
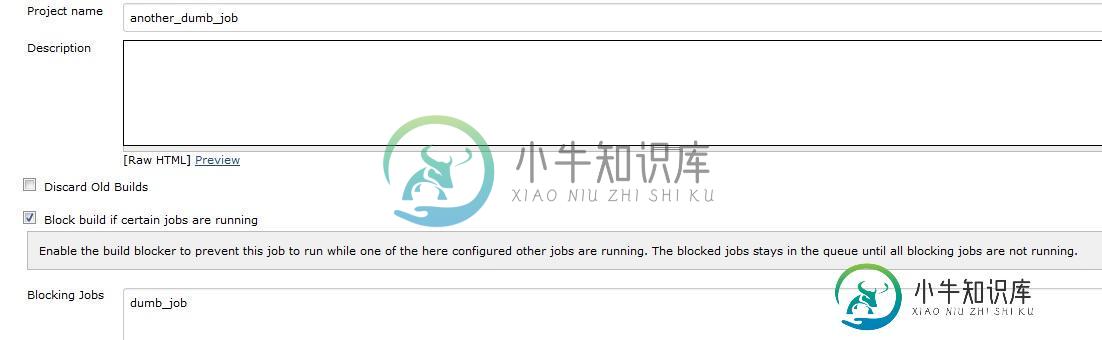 如果具有给定标签的给定节点正在/正在运行另一个作业,则阻止作业运行
如果具有给定标签的给定节点正在/正在运行另一个作业,则阻止作业运行在Jenkins中,如果作业B正在运行,我们可以使用Build blocker插件阻止作业a。 类似地或以某种方式,我希望一个作业,例如:another_dumb_job不运行/(等待并让它在队列中),如果有任何正在进行的作业在任何用户选择的从属上运行,直到这些从属再次空闲。 对于EX:我不想运行一个作业(这将删除一堆从机,无论是脱机还是联机--使用下游作业或通过调用一些Groovy/Script
-
使用插播广告格式作为奖励广告(Facebook Audience Network)
我在Play商店有一个普通的(非游戏)应用程序,它有一些高级功能,我目前已经实施了一个系统,在用户(非高级)同意观看广告后临时解锁上述功能。目前广告由AppLovin提供,但我的目标是切换到Facebook受众网络。 就我对FAN的理解而言;奖励视频广告格式仅适用于游戏应用程序,因此我在为我的应用程序创建位置时无法将其视为一种选择。 在政策上,为此目的使用间隙放置是否合适? 我已经阅读了https
-
 admob live广告未在ios上显示,但android广告显示(prod)
admob live广告未在ios上显示,但android广告显示(prod)我有一个离子型应用程序。我想实现cordova admob免费插件。我创建广告单元已经一个多月了。广告在android和ios上都能完美地运行。当我发布到商店时,android运行良好并显示广告,但ios广告不显示。有一个白色区域代替横幅广告。你可以在下面的照片中看到横幅广告。这张照片并不能完全理解,但广告应该出现在空白处。间隙广告和奖励广告根本不显示。此外,在我的admob帐户中,有许多ios请
-
链接选择框(国家,州,城市)
问题内容: 我有一个php页面,我想从国家,州和城市列表中选择一个位置。该页面包含用于用户注册的其他数据(名称,电子邮件等),因此在选择框刷新时,我不想刷新页面或其他任何内容。当前,每个选择框仅加载国家,州或城市的完整列表。我希望将它们链接起来,所以我没有重复的城市名称(不同州或国家/地区的名称相同)。 位置存储在数据库中,并在加载时传递到页面。然后将它们循环并添加到选择框中: 数据库结构非常简单
-
Java 关闭应用程序后,保持广播接收器运行
问题内容: 应用启动后,我需要一直保持广播接收器始终运行。 这是在应用程序中注册此接收器的代码 和接收器代码 问题答案: 你可以使用服务 在主应用中启动/停止服务 服务
-
Apache Spark:广播连接行为:过滤连接表和临时表
我需要在火花中连接2个表。但是我首先过滤掉第二个表的一部分,而不是完全连接2个表: 我想在这种情况下使用广播连接。 Spark有一个参数,用于定义广播连接的最大表大小:: 配置在执行联接时将广播到所有工作节点的表的最大大小(以字节为单位)。通过将该值设置为-1,可以禁用广播。请注意,当前统计信息仅支持已运行命令ANALYZE TABLE COMPUTE statistics noscan的配置单元
-
Spring批处理调度器:作业侦听器仅在作业第一次运行时工作
我当时正在开发一个Spring批处理应用程序,使用java配置执行两个批处理作业。最近,我添加了一个Spring调度程序来调度我编写的一个作业。侦听器在作业第一次完成时被调用,但在下一次执行后不会被调用。以下是我的作业配置代码: 下面是我的调度程序的代码: 我的听众如下: 以下是控制台输出: 请告诉我我做错了什么,为什么听者没有被执行后续尝试。
-
如果上游作业成功,如何将Jenkins作业配置为在特定时间运行?
我的使用案例: 作业 A 设置为在星期一到星期五的 18:00 运行。 作业 B 依赖于作业 A 是否成功,但应仅在周一至周五的 06:00 运行。(周一早上的跑步将取决于周五晚上的跑步)。我更喜欢设定的时间,而不是工作之间的延迟。 在任何给定的早晨,如果我看到作业A失败(因此作业B从未运行),我希望能够运行(修复)作业A,然后立即触发作业B。 到目前为止,我发现的只是这个用例的一部分。我修改了管
-
在Jenkins中将作业A的工作空间url传递给作业B
我有两个管道作业作业作业A和作业B。我需要通过作业A的工作空间url(比如 /var/lib/jenkins/workspace/JobA)被作业B使用。主要的想法是我试图复制由于maven构建而生成的目标文件夹的内容,但我不想使用复制工件插件或存档工件插件来实现同样的目的。 我尝试过使用“此作业已参数化”选项,其中作业A是作业B的上游,但我无法使用该选项。 有人能帮助实现同样的目标吗?
-
从Jenkins,如何获取JSON中当前正在运行的作业的列表?
问题内容: 我可以通过Remote API找到有关我的Jenkins服务器的所有信息,但不能找到当前正在运行的作业的列表。 这个, 要么 看起来似乎是最合乎逻辑的选择,但是他们没有说出(实际上是作业数)实际正在运行的作业。 问题答案: 我有一个使用“ 查看作业过滤器”插件定义的视图,该视图仅过滤当前正在运行的作业,然后您可以在视图页面上使用以查看正在运行的作业。我也有一个用于流产,不稳定等。 更新
-
如何在Jenkins脚本流水线中设置多行参数化cron作业?