
如果具有给定标签的给定节点正在/正在运行另一个作业,则阻止作业运行

在Jenkins中,如果作业B正在运行,我们可以使用Build blocker插件阻止作业a。
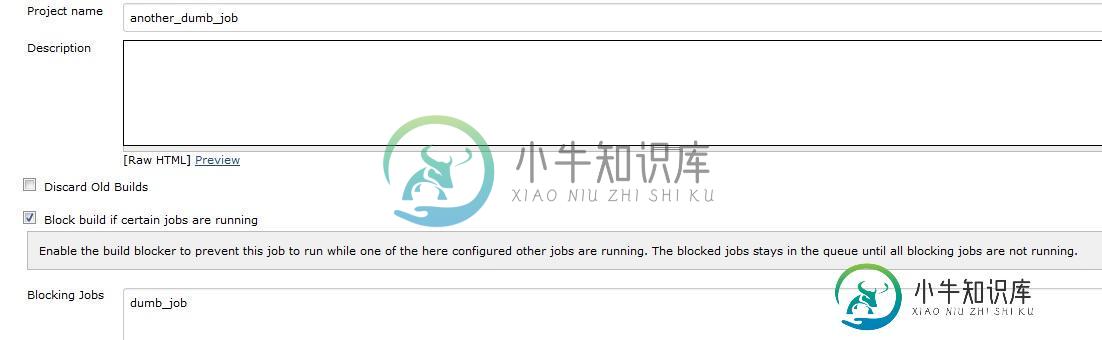
类似地或以某种方式,我希望一个作业,例如:another_dumb_job不运行/(等待并让它在队列中),如果有任何正在进行的作业在任何用户选择的从属上运行,直到这些从属再次空闲。
对于EX:我不想运行一个作业(这将删除一堆从机,无论是脱机还是联机--使用下游作业或通过调用一些Groovy/Scriptler脚本),直到其中任何一个从机都有活动的/正在进行的作业在它们上运行?
共有1个答案

要删除所有离线节点,请调整下面的脚本,并仅在isOffline()为true或isOnline()为false的从服务器上运行doDelete()。如果要删除所有节点(请小心),则不要使用以下If语句:
if ( aSlave.name.indexOf(slaveStartsWith) == 0) {
我也忽略了一个从属(如果你想总是忽略从属而不被删除的话)。可以对其进行增强,以使用要忽略的从机列表。
无论如何,下面的脚本将优雅地删除任何以给定名称开始的Jenkins节点从机(以便您有更多的控制权),并将标记为脱机(尽快),但仅在给定从机上的任何运行作业完成/完成后才删除它。我想我应该在这里分享。
/*** BEGIN META {
"name" : "Disable Jenkins Hudson slaves nodes gracefully for all slaves starting with a given value",
"comment" : "Disables Jenkins Hudson slave nodes gracefully - waits until running jobs are complete.",
"parameters" : [ 'slaveStartsWith'],
"core": "1.350",
"authors" : [
{ name : "GigaAKS" }, { name : "Arun Sangal" }
]
} END META**/
// This scriptler script will mark Jenkins slave nodes offline for all slaves which starts with a given value.
// It will wait for any slave nodes which are running any job(s) and then delete them.
// It requires only one parameter named: slaveStartsWith and value can be passed as: "swarm-".
import java.util.*
import jenkins.model.*
import hudson.model.*
import hudson.slaves.*
def atleastOneSlaveRunnning = true;
def time = new Date().format("HH:mm MM/dd/yy z",TimeZone.getTimeZone("EST"))
while (atleastOneSlaveRunnning) {
//First thing - set the flag to false.
atleastOneSlaveRunnning = false;
time = new Date().format("HH:mm MM/dd/yy z",TimeZone.getTimeZone("EST"))
for (aSlave in hudson.model.Hudson.instance.slaves) {
println "-- Time: " + time;
println ""
//Dont do anything if the slave name is "ansible01"
if ( aSlave.name == "ansible01" ) {
continue;
}
if ( aSlave.name.indexOf(slaveStartsWith) == 0) {
println "Active slave: " + aSlave.name;
println('\tcomputer.isOnline: ' + aSlave.getComputer().isOnline());
println('\tcomputer.countBusy: ' + aSlave.getComputer().countBusy());
println ""
if ( aSlave.getComputer().isOnline()) {
aSlave.getComputer().setTemporarilyOffline(true,null);
println('\tcomputer.isOnline: ' + aSlave.getComputer().isOnline());
println ""
}
if ( aSlave.getComputer().countBusy() == 0 ) {
time = new Date().format("HH:mm MM/dd/yy z",TimeZone.getTimeZone("EST"))
println("-- Shutting down node: " + aSlave.name + " at " + time);
aSlave.getComputer().doDoDelete();
} else {
atleastOneSlaveRunnning = true;
}
}
}
//Sleep 60 seconds
if(atleastOneSlaveRunnning) {
println ""
println "------------------ sleeping 60 seconds -----------------"
sleep(60*1000);
println ""
}
}
如果您的速度足够快,可以得到以下错误消息,这意味着您在作业中运行或调用了Scriptler脚本(如上所示),并限制该作业在非主或节点/从机器上运行。Scriptler脚本是SYSTEM Groovy脚本,即它们必须在Jenkins Master的JVM上运行才能访问所有Jenkins资源/调整它们。要解决以下问题,您可以创建一个作业(将其限制在主服务器上运行,即Jenkins master JVM),该作业只接受脚本程序脚本的一个参数,并从第一个作业调用该作业(作为触发项目/作业并阻止,直到作业完成):
21:42:43 Execution of script [disableSlaveNodesWithPattern.groovy] failed - java.lang.NullPointerException: Cannot get property 'slaves' on null objectorg.jenkinsci.plugins.scriptler.util.GroovyScript$ScriptlerExecutionException: java.lang.NullPointerException: Cannot get property 'slaves' on null object
21:42:43 at org.jenkinsci.plugins.scriptler.util.GroovyScript.call(GroovyScript.java:131)
21:42:43 at hudson.remoting.UserRequest.perform(UserRequest.java:118)
21:42:43 at hudson.remoting.UserRequest.perform(UserRequest.java:48)
21:42:43 at hudson.remoting.Request$2.run(Request.java:328)
21:42:43 at hudson.remoting.InterceptingExecutorService$1.call(InterceptingExecutorService.java:72)
21:42:43 at java.util.concurrent.FutureTask.run(FutureTask.java:266)
21:42:43 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
21:42:43 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
21:42:43 at java.lang.Thread.run(Thread.java:745)
21:42:43 Caused by: java.lang.NullPointerException: Cannot get property 'slaves' on null object
也就是说,如果在作业中运行Scriptler脚本构建步骤(该作业不在MASTER Jenkins Machine/JVM上运行),那么上述错误就会出现,为了解决它,创建一个作业“DisablesLavenodesStartsWith”,并限制它在MASTER(更安全的端)上运行,调用Scriptler脚本并向作业/脚本传递参数。
现在,从另一个工作中,调用这个工作:
-
问题内容: 我有这个独特的要求来检查给定的节点是否正在运行作业。我正在考虑使用groovy,因为它看起来是最简单的选择。 它使我能够找到从站是否在线。对我来说,下一步是检查它是否正在运行作业。 我正在考虑使用API函数setAcceptingTasks(false)来将slave标记为正在运行作业,以便下次当我使用isAcceptingTasks()查询时,我会得到false,因此不会在该slav
-
我有点困惑,因为当通过HTTP请求启动Spring Batch作业的执行时,如果我在作业执行时收到另一个HTTP请求来启动相同的作业,但参数不同,则正在执行的作业停止未完成并开始处理新作业。 我开发了一个API REST来加载和处理Excel文件的内容。web服务公开了两个endpoint,一个用于加载、验证和存储数据库中Excel文件的内容,另一个用于开始处理存储在数据库中的记录。 > POST
-
我正在kubernetes上试用最新版本的Flink1.5的flink工作。 我的问题是如何在上面的flink集群上运行一个示例应用程序。flink示例项目提供了如何使用flink应用程序构建docker映像并将该应用程序提交给flink的信息。我遵循了这个例子,只是把flink的版本改成了最新版本。我发现应用程序(example-app)提交成功,并且在kubernetes的pod中显示,但是f
-
在浏览了spring文档之后,在我的代码中。 我面临的问题是,有时工作的终止是发生在预期和其他时间终止工作是不发生的。实际上,每次调用joboperator上的stop时,它都在更新BATCH_JOB_EXECUTION表。当终止成功发生时,作业的状态将通过杀死批处理过程中的jobExecution更新为STOPPED。其他失败的时候,它会完成批处理的其他不同流,并将BATCH_JOB_EXECU
-
我的问题是我的pyspark作业没有并行运行。 代码和数据格式: 我的PySpark如下所示(显然是简化的): PySpark的全部要点是并行运行这个东西,显然不是这样。我在各种集群配置中运行了这些数据,最后一个配置是大量的,这时我注意到它是单一节点使用的。因此,为什么我的工作需要很长时间才能完成,而时间似乎与集群规模无关。 所有较小数据集的测试在我的本地机器和集群上都没有问题。我真的只是需要高档