《中银消费金融面经》专题
-
 渤海银行软件开发Java一面热经
渤海银行软件开发Java一面热经hr+3技术面试官 20min hr: base哪里 为啥不做算法 技术面: 1.JVM垃圾回收算法、如何判断对象存活、GCroots、JVM用的垃圾回收器 2.MySQL怎么调优、explain的执行计划怎么生成的(G)、数据库表结构什么filedate(G) 3.项目(数据库一致性、内部服务通信、熔断)
-
 招商银行总行信息技术部面经
招商银行总行信息技术部面经摆烂太久,已经忘得7788了,答得稀碎 实习的鉴权怎么做的,了解常用的鉴权方案吗 为什么考虑用kafka,不用其他的mq呢 怎么做消费幂等性的 tcp为什么两次握手,三次不行吗 https和http区别,https过程 java的io 同步和异步,阻塞和非阻塞的区别 java内存泄漏 微服务网关是做什么的 一致性哈希 rocketmq的死信队列做什么的 介绍几个常见的设计模式 了解开闭原则吗?结合
-
 招银网络科技数据研发岗面经
招银网络科技数据研发岗面经一面: 1.自我介绍, 2.询问了实习中的项目具体内容,提出了一个场景,问如何保证准确率 3.sql的执行顺序 4.数据库的索引类型 5.sql题 一道非常简单 还有一道要用到窗口函数 求连续三天登录 6.还有其他问题 有点记不清了 一面结束之后大概是隔天就收到了二面消息 二面: 1.自我介绍 2.问实习期间的项目 问了好几个小问题 3.问之前学习过程遇到的困难 怎么处理的 4.问MySQL和Or
-
 西安工商银行软开实习生面经
西安工商银行软开实习生面经1对4面试官 每人10-15min 先自我介绍 针对自我介绍会问几个问题 然后看简历让讲项目 无八股 最后是聊天,比如考不考研啥的
-
 兴业数金 热乎的测试工程师一面面经
兴业数金 热乎的测试工程师一面面经8.11号通知我预约一个面试时间,说是只有第二天下午,虽然感觉很急但是还是迎合头皮答应下来了 时间是下午两点腾讯会议,先加入进去等待邀请进入面试,但是差不多一点四十多就被邀请进去了 技术面问题:: 1. 自我介绍;2. 问了简历相关一些; 3. 最近半年里遇到的最大挑战?; 4. 说我笔试成绩很高,怎么做到的?可能也是排查一下是否有作弊行为?然后又问了一下对于笔试题有什么建议(笔试好像是8.5号还
-
 浙大金华研究院(CV算法实习一面面经)
浙大金华研究院(CV算法实习一面面经)1.自我介绍; 2.介绍一下做过的项目和论文; 3.用过哪些机器学习模型(XGBoost、LightGBM、RF、LR等),介绍他们的特点和区别; 5.深度学习用过哪些结构(MLP、CNN、RNN、Transformer、BERT等),介绍一下各自的特点和区别; 6.深度学习主要有哪些任务(分类和回归,分类可以使用有监督、无监督、半监督等方法,回归主要使用有监督方法); 7.了解CV吗,用过开源框
-
 蚂蚁金服Java后端开发工程师一面面经
蚂蚁金服Java后端开发工程师一面面经问题涉及技术架构、消息队列、Spring框架等多个方面 技术架构,以及为什么要这样设计 MQ是怎么保证不重复消费,可靠性投递,本身是怎么保证可用性的 Spring Cloud以及外部都有提供动态线程池,为什么还要自己写一套 Spring IOC的理解,底层的实现机制,用了什么设计模式 AOP的底层实现机制 动态代理和静态代理的区别,动态代理的实现方式,以及两种实现方式的区别 用过哪些设计模式 单例
-
 中信银行无锡分行信息科技岗初面
中信银行无锡分行信息科技岗初面不晓得为什么其他分行都是先笔试,无锡分行直接面试的,也不晓得是不是批次的原因。一个面试官六个人,先自我介绍,然后一个人面试官提了一个问题。最后又让我们每个人回答三个问题:1.爱好;2.对信息科技岗的理解;3.以后分的不是信息科技岗能接受吗。 在前面人的带偏下,第二个问题变成了对银行的理解,第三个变成了轮岗的看法 如果过了,后面还有笔试和二面三面,太繁琐了 #中信银行 #无锡分行 #信息科技#面经#
-
 中国银行厦门分行信息技术岗一面
中国银行厦门分行信息技术岗一面一面大概是在笔试过后的的三周左右,是在厦门分行的总部大楼里进行的,邮件里做了分组,到了直接坐在对应的组别里,我当时是三组,不问不知道,一问吓一跳,旁边都是985211的大佬,也有海外院校的,更有一个是厦门大学物理系博士,我当时感觉没戏了,直接开摆。 每个组对应一个面试间,每个人的先后顺序由抽签决定,我运气比较臭,抽了倒二个。进面试间,里面是三个面试官,其中一个是信息科技部的总经理(可能是这个部门吧
-
 中国银行厦门分行信息技术岗二面
中国银行厦门分行信息技术岗二面二面大概是一面过后三周,银行的面试间隔都很久,建议当作保底offer对待,当天面试的人都在会议厅,大概只有十几个人,我这次排到前几个,进面试间就两个面试官,一个是一面的信息科技部总经理,另一个是人力资源部的总经理,先是自我介绍,然后是提问环节,还是问的跟上次差不多的问题,不过这次不一样的是,问了做了哪些学校以外的项目,言外之意就是有没有在外面实习过,然后问了目前拿到几个offer,这个问题,我觉得
-
外行的Java 8供应商和消费者说明
问题内容: 作为学习Java的非Java程序员,我现在正在阅读和接口。而且我无法理解它们的用法和含义。什么时候以及为什么要使用这些接口?有人可以给我一个简单的外行例子吗?我发现Doc例子不够简洁,无法理解。 问题答案: 这是供应商: 这是消费者: 因此,用通俗易懂的术语来说,供应商是一种返回一些值(如返回值)的方法。而使用者是一种消耗一些值(如在方法参数中)并对其执行一些操作的方法。 这些将转变为
-
Java使用队列的生产者/消费者线程
问题内容: 我想创建某种线程应用程序。但是我不确定在两者之间实现队列的最佳方法是什么。 因此,我提出了两个想法(这两个想法可能都是完全错误的)。我想知道哪种更好,如果它们都烂了,那么实现队列的最佳方法是什么。我关心的主要是这些示例中队列的实现。我正在扩展一个内部类的Queue类,它是线程安全的。下面是两个示例,每个示例有4个类。 主班 消费阶层 生产者类别 队列类 要么 主班 消费阶层 生产者类别
-
python kafka 多线程消费者&手动提交实例
本文向大家介绍python kafka 多线程消费者&手动提交实例,包括了python kafka 多线程消费者&手动提交实例的使用技巧和注意事项,需要的朋友参考一下 官方文档:https://kafka-python.readthedocs.io/en/master/apidoc/KafkaConsumer.html 以上这篇python kafka 多线程消费者&手动提交实例就是小编分享给大家
-
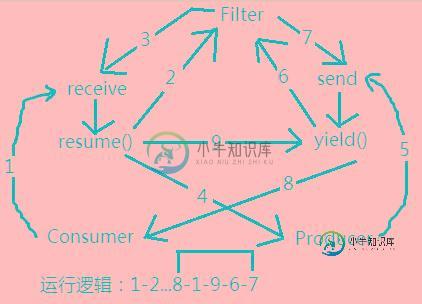 Lua编程示例(八):生产者-消费者问题
Lua编程示例(八):生产者-消费者问题本文向大家介绍Lua编程示例(八):生产者-消费者问题,包括了Lua编程示例(八):生产者-消费者问题的使用技巧和注意事项,需要的朋友参考一下 这个问题是比较经典的啦,基本所有语言的多线程都会涉及到,但是没想到Lua的这个这么复杂 抓狂 看了好长时间才算看明白,先上个逻辑图: 开始时调用消费者,当消费者需要值时,再调用生产者生产值,生产者生产值后停止,直到消费者再次请求。设计为消费者驱动
-
Springboot Kafka @Listener消费者暂停/恢复不起作用
我有一个Spring靴Kafka消费者 为了避免重新平衡,我尝试在KafkaContainer上调用pause()和resume(),但消费者总是在运行 我错过了什么吗?有人能指导我如何正确地达到要求的行为吗?