《中银消费金融面经》专题
-
如何处理vertx消费者异常?
我有代码: 处理消费者异常的最佳方法是什么?现在,如果异常引发,它将被吞没。。。
-
Kafka消费者困于反序列化
我创建了一个简单的生产者-消费者应用程序,使用自定义序列化器和反序列化器。 在我生成的Message类中添加了一个新方法之后,使用者开始在反序列化时被堆栈。我的生产者使用的是新类(有新方法),消费者使用的是旧类(没有方法)。 JSONSerializer/Deserializer可以处理这些类型的修复吗?如果我要使用JSONSerialzier,它应该只关心类的模式,对吗?
-
Kafka消费者信息提交问题
Kafka新手。 Kafka版本:2.3.1 我正在尝试使用Spring cloud使用来自两个主题的Kafka消息。除了kafka活页夹和下面的一些简单配置之外,我没有做太多配置。每当(组协调器lbbb111a.uat.pncint.net:9092(id:2147483641机架:null)不可用或无效时,将尝试重新发现)发生时,已经处理的一堆消息会再次被处理。不确定发生了什么。
-
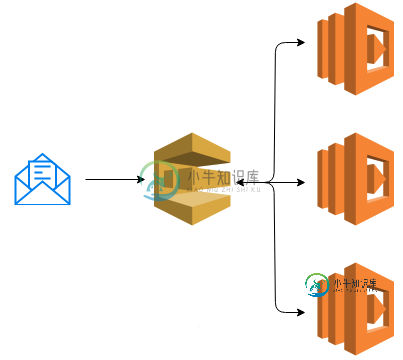 使用Amazon SQS的多个消费者
使用Amazon SQS的多个消费者我用java编写我所有的微服务。我想在Amazon SQS中使用多个消费者,但每个消费者在负载均衡器后面的AWS上有多个实例。 我使用SNS作为输入流 我在SNS之后使用SQS标准队列。 我在stackoverflow上发现了同样的问题(使用多个消费者的Amazon SQS) 此示例为 https://aws.amazon.com/fr/blogs/aws/queues-and-notificat
-
Flink Python数据流API Kafka消费者
我是pyflink的新手。我正在尝试编写一个python程序来从kafka主题读取数据并将数据打印到标准输出。我按照链接Flink Python Datastream API Kafka Producer Sink Serializaion进行了操作。但由于版本不匹配,我一直看到NoSuchMethod odError。我添加了https://repo.maven.apache.org/maven
-
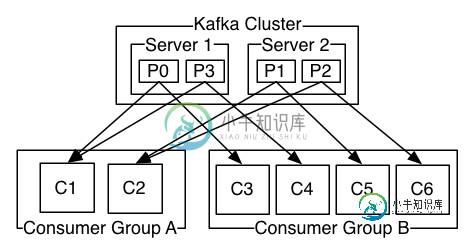 跨消费者的Kafka日志分布
跨消费者的Kafka日志分布apache kafka文档提到以下内容: 如果所有使用者实例具有相同的使用者组,那么记录将有效地在使用者实例上进行负载平衡。 如果所有的使用者实例都有不同的使用者组,那么每个记录都将广播给所有的使用者进程。
-
Kafka-消费者偏移自动复位
谢了。
-
Webflux生产者消费者问题(webClient)
我如何将电话限制在每5秒一次。注意:只能修改reallySlowApi。 编辑:我知道,但是如果Api变得更慢,它就不能解决问题。我需要使用的最佳方式。
-
Kafka消费者重新阅读信息
我看到一个问题,我的主题中的所有消息都被我的消费者重新阅读。我只有1个消费者,我在开发/测试时打开/关闭它。我注意到,有时在几天没有运行消费者之后,当我再次打开它时,它会突然重新阅读我的所有消息。 客户端 ID 和组 ID 始终保持不变。我显式调用提交同步,因为我的启用.我确实设置了 auto.offset.reset=最早,但据我所知,只有在服务器上删除了偏移量时,才应该启动。我正在使用 IBM
-
Kafka消费者会议计时结束
我们有一个应用程序,消费者读取一条消息,线程执行许多操作,包括在生成另一主题的消息之前访问数据库。在线程上消耗和生成消息之间的时间可能需要几分钟。一旦生成了指向新主题的消息,就会进行提交,以表明我们已经完成了对消费者队列消息的处理。自动提交因此被禁用。 我正在使用高级消费者,我注意到的是zoowatch和kafka会话超时,因为我们在消费者队列上做任何事情之前需要太长时间,所以kafka每次线程返
-
kafka java消费者不读取数据
我正在尝试编写一个简单的java kafka consumer,使用与中类似的代码读取数据https://github.com/bkimminich/apache-kafka-book-examples/blob/master/src/test/kafka/consumer/SimpleHLConsumer.java. 看起来我的应用程序可以连接,但它无法获取任何数据。请建议。 下面是我在ecli
-
如何检索Kafka消费者配置
我有几个连接到Kafka集群的消费者,但我无法控制。同时,我想了解这些消费者是如何配置的。 有没有一个API可以列出所有的消费者(如果有发布者的话,这是一个额外的好处),然后读取他们所有的配置?我说的是这些消费者设置: https://docs . confluent . io/current/installation/configuration/consumer-configs . html #
-
Apache Camel Restlet消费者和生产者
我想使用一个camel组件,它提供了使用和生成RESTful资源的能力。 对于这个例子,我想使用camel restlet组件。restlet组件一切正常,我已经使用REST DSL成功地实现了restlet consumer。然而,我有几个问题: 问题 1) 将restlet启用为异步是否安全?我读过restlet async可能会导致一些问题。这仍然正确吗?如何提高服务绩效?我应该改用码头吗?
-
Kafka消费者配置/性能问题
对于我的测试,我在队列中发布了700万条消息。我创建了一个包含30个消费者线程消费者组,每个分区一个。我最初的印象是,与通过SQS获得的相比,这将大大加快处理能力。不幸的是,情况并非如此。在我的例子中,数据处理是复杂的,平均需要1-2分钟才能完成,这导致了一系列分区重新平衡,因为线程不能按时运行。我在日志里看到一堆消息 组FULL_GROUP的自动偏移量提交失败:无法完成提交,因为该组已重新平衡并
-
KafkaSASL_PLAINSCRAM在Spring启动消费者失败
我尝试了kafka身份验证SASL_PLAINTEXT/SCRAM,但在Spring Boot中身份验证失败。 我尝试更改SASL_PLAINTEXT/PLAIN,它正在工作。但是SCRAM是身份验证失败SHA-512和SHA-256 做了很多不同的事情,但它不起作用……我该如何修复它? 代理日志 Spring启动日志 我的docker-compose.yml kaka服务器jaas.conf z