
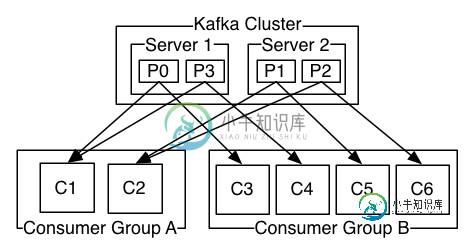
跨消费者的Kafka日志分布

apache kafka文档提到以下内容:
如果所有使用者实例具有相同的使用者组,那么记录将有效地在使用者实例上进行负载平衡。
如果所有的使用者实例都有不同的使用者组,那么每个记录都将广播给所有的使用者进程。
共有1个答案

这是否意味着每个组中的每个消费者将读取所有分区中的所有记录?!!
该语句假定每个组都有一个消费者(如“如果所有消费者实例都有不同的消费者组”所示)。
所以你的总体理解是正确的。如果您有多个消费者组,将向每个组发送一次消息。
-
我正在阅读Kafka常见问题解答,他们如下所示。 •每个分区不会被每个使用者组中的多个使用者线程/进程使用。这允许每个进程以单线程方式使用,以保证分区内的使用者的顺序(如果我们将有序消息分割成一个分区并将它们传递给多个使用者,即使这些消息是按顺序存储的,它们有时也会被无序地处理)。 有没有可能,
-
是否有一种方法以编程方式访问和打印使用者滞后偏移,或者说使用者读取的最后一条记录的偏移与某个生产者写入该使用者分区的最后一条记录的偏移之间的位置差。 要知道我的最终目标是将这个值发送到prometheus进行监视,我应该在上面添加哪些语句来得到滞后偏移值?
-
Flink kafka消费者有两种类型的消费者,例如: 这两个消费者层次结构扩展了相同的类。我想知道维护编号类背后的设计决策是什么?我们什么时候应该使用其中一种? 我注意到带有数字后缀的类有更多的特性(例如ratelimiting)。 https://github.com/apache/flink/blob/master/flink-connectors/flink-connector-kafka
-
我刚接触Kafka,很少阅读教程。我无法理解使用者和分区之间的关系。 请回答我下面的问题。 > 消费者是否由ZK分配到单个分区,如果是,如果生产者将消息发送到不同的分区,那么其他分区的消费者将如何使用该消息? 我有一个主题,它有3个分区。我发布消息,它会转到P0。我有5个消费者(不同的消费者群体)。所有消费者都会阅读P0的信息吗?若我增加了许多消费者,他们会从相同的P0中阅读信息吗?如果所有消费者
-
我知道kafka将一个主题的数据安排在许多分区上,一个消费者组中的消费者被分配到不同的分区,从那里他们可以接收数据: 我的问题是: 术语,它们是由主机/IP标识的,还是由客户端连接标识的? 换句话说,如果我启动两个线程或进程,使用相同的消费者组运行相同的Kafka客户端代码,它们被认为是一个消费者还是两个消费者?
-
null 我在这一页上读到以下内容: 使用者从任何单个分区读取,允许您以与消息生成类似的方式扩展消息消耗的吞吐量。 也可以将使用者组织为给定主题的使用者组-组内的每个使用者从唯一分区读取,并且组作为一个整体使用来自整个主题的所有消息。 如果使用者多于分区,则某些使用者将空闲,因为它们没有可从中读取的分区。 如果分区多于使用者,则使用者将从多个分区接收消息。 如果使用者和分区的数量相等,则每个使用者