《中银消费金融面经》专题
-
Spring Boot Kafka消费者未消费,Kafka Listener未触发
我试图构建一个简单的spring boot Kafka Consumer来消费来自Kafka主题的消息,但是由于KafkaListener方法没有被触发,所以没有任何消息被消费。 Java类: start.java: kafkaConsumerConfig.java:
-
Kafka消费者可以从所有分区消费吗
我有一个多分区主题,由多个使用者(同一组)使用。我的目标是最大化消费处理,即任何消费者都可以消费来自任何分区的消息。 我知道这看起来是不可能的,因为只有一个消费者可以从一个分区中消费。 有没有可能使用REST代理来实现这一点?例如,轮询所有代理消费者实例。 谢了。
-
 中信银行hr面
中信银行hr面信息科技岗(数据分析) 1.自我介绍 2.基本信息(本科和研究生成绩排名,获奖情况,兴趣爱好,家庭情况等) 3.户口和期望薪资 hr面后需要泡池子排序,还会刷很大比例希望有个好运吧
-
 永赢金融-科技定向-前端-2.23
永赢金融-科技定向-前端-2.23(记不太清楚了 自我介绍+项目 项目负责的部分 同源策略 看代码说输出(flex布局,解构赋值,还有一个忘了QAQ) 提了一下ES6新特性 Git本地缓存的使用 React类组件编程和函数式编程的区别 常用的Hooks? 介绍一下useEffect 闭包
-
 腾讯cdg金融科技秋招前端
腾讯cdg金融科技秋招前端更新:秒挂 8.29一面结束: 开局问我看你项目全是pc端,有了解h5和小程序吗,俺说妹有,感觉变KPI面 全程八股,算法是两个单链表求相同节点,秒 但是感觉是KPI面
-
 中信银行设计面经
中信银行设计面经面试内容二选一做设计作业,在这三天后技术面试 1、每个人十五分钟答辩加面试 2、面试问题完全是围绕专业和设计作业提问的,一点银行方面的都没有 3、设计的时候对色彩选择的理由 4、平时怎么学习 5、这次PC端的设计是如何学习的 6、情感化设计用的元素为什么这么简单 7、字体如果用户没有下载怎么办 8、图标为什么颜色丰富但是整体视觉风格用色单一 9、交互和视觉哪个更擅长 10、视觉能力比较强但是为什么
-
消费者 映射类 在HashMap中
问题内容: 我想创建一个。基本上,我想使用一种说明该类型的方法来映射一个类型。 我希望能够动态地说出对象X,执行Y。我可以 但它很烂,因为然后我必须在使用它时将对象投射到兰巴中。 例: 我想做的是 但这似乎是不允许的。有没有办法做到这一点 ?使用此类型的方法映射类型的最佳解决方法是什么? 问题答案: 本质上,这与Joshua Bloch所描述 的类型安全的异构容器类似,只是您不能使用来强制转换结果
-
Tomcat中的Kafka消费者关闭
我们正在tomcat服务器中部署kafka消费者。消费者是使用Spring-Kafka2.1.7构建的。每个tc容器可以有多个属于同一个使用者组的使用者(使用ConcurrentKafkaListenerContainerFactory)。作为一般模式,在我的使用案例中,使用者以事务性的方式从一个主题读取并生产到另一个主题。tc服务器由通常的启动和关闭shell脚本启动和停止。如果要优雅地关闭co
-
在Kafka中生产和消费JSON
我们将在项目中部署Apache Kafka2.10,并通过JSON对象在生产者和消费者之间进行通信。 到目前为止,我想我需要: 实现自定义序列化程序以将JSON转换为字节数组 实现自定义反序列化器,将字节数组转换为JSON对象 生成消息 读取消费者类中的消息 然而,到目前为止,有问题的2-4分。我在自定义反序列化程序中尝试了这样的操作: 在我的消费者身上,我试着: 我以为这将生成一个正确的原始js
-
 拼多多消费者服务运营管培一面面经
拼多多消费者服务运营管培一面面经10分钟结束 自我介绍 实习经历深挖 为啥想到电商工作 最印象深刻的实习或者学生干部经历 为啥印象深刻 反问 具体工作内容感觉没问出来啥 需要轮岗三个月,做客服,最后分配部门并非想去哪个去哪个。 hr联系我两次推迟面试时间。。。 #运营##拼多多求职进展汇总#
-
 中信银行软件中心一面面经
中信银行软件中心一面面经有点离谱,之前给我打过电话,但是我不想去外地不想面了,就说放弃。然后昨天来了个面试邮件,我以为是西安的,没注意软件中心,我就直接接了 结果面试的时候面试官说是成都的总行。。还问我为什么想去成都,我都想说我以为是西安的面试。。。 14:00开始,等到了15:00进入面试 面经如下: 在华为是吧,哪里实习,成研所?(西研所)为什么想来成都(我不知道啊,我以为是西安) 成绩怎么样 期望方向是什么 会什么
-
消费者/生产者AWS SQS akka scala与synchrone消费者
我的应用程序有一个生产者和一个消费者。我的生产者不定期地生成消息。有时我的队列会是空的,有时我会有一些消息。我想让我的消费者监听队列,当有消息在其中时,接受它并处理这条消息。这个过程可能需要几个小时,如果我的消费者没有完成处理当前消息,我不希望他接受队列中的另一条消息。 我认为AKKA和AWS SQS可以满足我的需求。通过阅读文档和示例,akka-camel似乎可以简化我的工作。 我在github
-
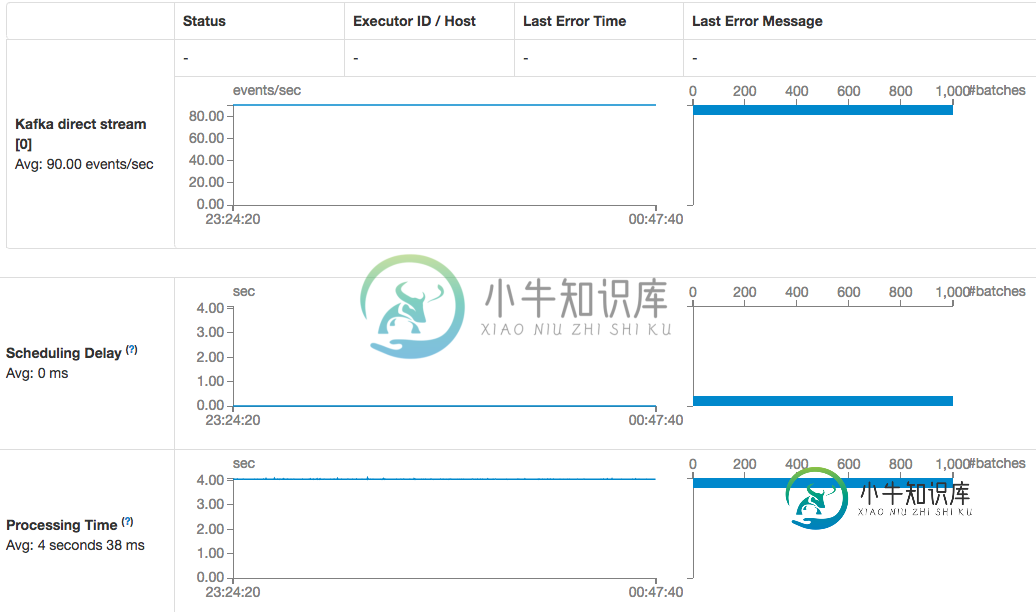 火花流Kafka直接消费者消费速度下降
火花流Kafka直接消费者消费速度下降我使用的是运行在AWS中的spark独立集群(spark and spark-streaming-kafka version 1.6.1),并对检查点目录使用S3桶,每个工作节点上没有调度延迟和足够的磁盘空间。 没有更改任何Kafka客户端初始化参数,非常肯定Kafka的结构没有更改: 也不明白为什么当直接使用者描述说时,我仍然需要在创建流上下文时使用检查点目录?
-
未调用Kafka侦听器方法。消费者不消费。
这是创建ListenerContainerFactory的类 这是我用@KafKalistener注释的Listener类 这是KafkaListenerConfig类,它接受引导服务器、主题名称等。
-
如何为Java中的消费者组获取消费者偏移(存储在kafka中)?
我有多个Kafka消费者和制作人,主题不同。使用独立应用程序,我想监控Kafka消费者的延迟。 我使用Kafka0.10.0.1,因为Kafka现在存储消费者偏移Kafka本身,所以我怎么能读到相同的。 我能够读取每个分区的主题偏移量。