《中银消费金融面经》专题
-
 腾讯金融科技测开,逆天
腾讯金融科技测开,逆天约的早上11.30面,等了半天不来,我肚子痛得很都忍住了,后面发邮件问面试官说忘记了,约了晚上7点 晚上刚吃完晚饭,6.30几,给我打电话喊我快点上线,我寻思你急**呢? 刚上线马上拉我,上来就感觉不对,问我对部门、地点有什么问题吗?说只有一个hc? 闲聊了几分钟,写了道算法,问了GC和TCP,没问题了 *********急着下班是吧? 反问:我问他对于测开前景得看法? 他突然急了,不知道为啥这么
-
 腾讯CDG金融科技测开挂
腾讯CDG金融科技测开挂3.30投递 4.9 一面(两小时,八股+部分项目提问+手撕默克尔树构建) 4.11 二面(一小时,项目拷打+场景题+项目提问+手撕最长无重复子串) 4.16 三面(一小时半,项目框架提问+自己的优化思考+三个思考题(二叉树,C结构体,线程)+手撕字符串相乘) 4.18 hr面(为什么想选测开+做了哪些努力+项目中如何和他人合作+零碎提问) 4.26 已挂 不知道还能有哪些公司可以投(测开岗),求
-
Kafka 消费者是否可以消费指定分区消息?
本文向大家介绍Kafka 消费者是否可以消费指定分区消息?相关面试题,主要包含被问及Kafka 消费者是否可以消费指定分区消息?时的应答技巧和注意事项,需要的朋友参考一下 Kafa consumer消费消息时,向broker发出fetch请求去消费特定分区的消息,consumer指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,customer拥有了offset的控制权,可
-
Spring cloud stream-Kafka消费者使用StreamListener消费重复消息
在我们的spring boot应用程序中,我们注意到Kafka消费者偶尔会在prod env中随机消费两次消息。我们在PCF中部署了6个实例和6个分区。我们发现在同一主题中收到两次具有相同偏移量和分区的消息,这会导致重复,对我们来说是业务关键。我们在非生产环境中没有注意到这一点,在非生产环境中很难复制。我们最近转向Kafka,但我们无法找到根本问题。 我们使用的是spring cloud stre
-
骆驼中程jpa消费者
我在JPA上遇到了以下问题,但这可能更像是一个关于骆驼的概念问题。 我需要一个基于cron的石英消费者。但如果触发了,我想选择JPA组件作为第一步。 但是如果我用“to”调用JPA组件,那么它被用作生产者,而不是消费者。我可以以某种方式使用JPA组件来处理这个问题吗,或者我必须遵循服务激活器(基于bean的)逻辑并将JPA组件留在后面? 提前谢谢你,葛格利
-
JMS-从一个消费者到多个消费者
问题内容: 我有一个JMS客户端,它正在生成消息并通过JMS队列发送到其唯一的使用者。 我想要的是不止一个消费者收到这些消息。我想到的第一件事是将队列转换为主题,以便现有用户和新用户都可以订阅并将相同的消息传递给他们。 显然,这将涉及在生产者和消费者方面修改当前的客户代码。 我还要查看其他选项,例如创建第二个队列,这样就不必修改现有的使用者。我相信这种方法有很多优点,例如(如果我错了,请纠正我)在
-
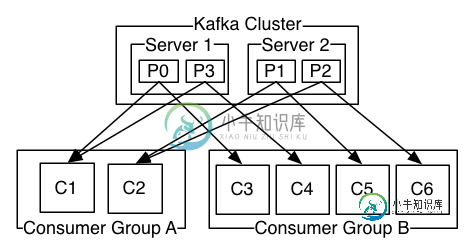 消费者和消费者组有什么关系?
消费者和消费者组有什么关系?本文向大家介绍消费者和消费者组有什么关系?相关面试题,主要包含被问及消费者和消费者组有什么关系?时的应答技巧和注意事项,需要的朋友参考一下 每个消费者从属于消费组。具体关系如下:
-
Kafka控制台消费者未从主题消费
我们有一个服务器,负责处理消息的生成和消费。我们有4台笔记本电脑,所有带有confluent的Mac都运行相同的命令行。。。 /kafka avro控制台使用者--从一开始--引导服务器0.0.0.0:9092,0.0.0.0:9092--主题主题名称--属性schema.registry.url=http://0.0.0.0:8081 4台笔记本电脑中有3台没有问题使用这些消息,但是第四台不会。
-
在Kafka中,当分区多于消费者时,消息是如何被消费的?
这是一个关于Kafka和信息如何被消费的非常基本的问题,但不幸的是,我在这一点上找不到任何答案。 假设我想过度分区,那么我将得到比消费者多10倍的分区。过度分区是必需的,因为我希望能够扩展(在未来并行处理更多的消息)。 1 个主题分为 1000 个分区,由 100 个使用者使用 =- 我的问题是: > 消息是如何为每个消费者消费的:它是以循环方式完成的吗?如果不是,分发是如何完成的? 有没有保证消
-
 宁波银行-永赢金租 一面 后端 10.10 30min
宁波银行-永赢金租 一面 后端 10.10 30min自我介绍 讲解一下自己熟悉的设计模式 讲解一下熟悉的线性表 线性表在Java集合的类的对应 讲解一下线程的六种状态,这个地方疏忽了,名字忘记了,说了一些最显著的区别。 JVM的内存区域,以及各自干什么的 元数据区里面存放的那些东西 递归调用没有返回值,会出现什么错误,为什么会出现这个错误 栈帧里面存放的数据 数据库的左右连接,出了一个题 Spring的常用注解 Springboot的自动装配原理
-
 【面经】兴业证券-金融科技暑期实习-前端方向
【面经】兴业证券-金融科技暑期实习-前端方向拿offer了,7.5面试,7.12下offer Base是福州(俺是福州人,兴业证券、银行也是福州这边发家的) 面试平台是腾讯会议,35min左右,无手写代码,大概4~5个面试官,听后面介绍是来自不同部门,有金融科技部也有信息技术部。 整体面试有点迷哈哈哈,我投的是纯前端方向的JD,但是面试完全不涉及 html、js、css 知识。兴业证券的信息比较少,来贡献一个面经,凭记忆回忆一下内容: 自我
-
 京东科技金融策略增长数分-24校招1面经
京东科技金融策略增长数分-24校招1面经开场互相自我介绍。 首先是10min盘问实习中的分析。主要围绕1、背景是什么;2、为什么这个问题需要分析; 3、发现了什么问题以及这个发现怎么去推动业务;几点展开询问。问的不深。还问了一些边角问题比如策略实施谁排版、和搜推团队如何合作、你觉得你们的业务有什么可以改进的点。主要考察业务了解。 接下来是案例题一整套。接下来让你说一个你常用的软件。分析他和竞品之间的优劣势,讲讲你认为怎么该从竞品中胜出。
-
Kafka消费绩效
我的Kafka集群有下一个配置。 Kafka版本集群(V1.1.0)3个代理 一个主题(“FARA”),包含5个分区和3个副本 每个分区中有10000000条消息。总共50.000.0000 我使用的是Kafka-Consumer-Perf,测试用的是下面使用ConsumerPerformance的decro。 null 我定期运行下面的命令 ./kafka-run-class.sh kafka.
-
Quarkus SQS消费者
我正在查看关于使用Quarkus从SQS消费的指南。 问题是我想在无休止的循环中执行它,例如每10秒获取一次新消息,并使用Hibernate Reactive从消息中插入一些数据到数据库中。 我创建了一个Quarkus调度程序,但由于它不支持返回Uni,我不得不阻止Hibernate Responsive的响应,因此出现了这个错误 使用Quarkus和reactive实现我所需的最佳方法是什么?
-
Kafka消费群体
我是Kafka的新手,正在学习Kafka内部知识。请根据需要随时更正我的理解。。 这是我的实时场景..感谢所有的回复: 我有一个接收数据文件的实时FTP服务器…比如索赔文件。 我将把这些数据发布到一个主题中.让我们把这个主题称为claims_topic(2个分区). 我需要订阅这个claims_topic,阅读消息并将它们写入Oracle和Postgres表。让我们将oracle表称为Otable