《埃克斯工业》专题
-
迪克斯特拉有一堆。如何在松弛后更新堆?
我正在尝试实现Dijkstra算法。 那么,在松弛中,我如何更新堆,使其具有正确的顺序?在该步骤中,我没有该节点的堆索引。这是否意味着我必须创建一个新的数组,如,以便我可以获得该节点的堆索引?但这似乎效率很低,因为我需要更新、函数。 C或JAVA代码也可以。
-
用石英立即解雇工作克朗
这是我用来立即激发job的代码:
-
克隆Mediaotor在WSO2 ESB 4.8.1中不工作
验证中介代码: 例外情况: 未捕获的异常{org.apache.axis2.transport.base.threads.nativeWorkerpool}java.lang.ClassCastException:org.apache.axiom.om.impl.llom.OmelementImpl不能在org.apache.axiom.soap.impl.llom.soapbodyImpl.ge
-
框架克星克星…需要克星码
问题内容: 假设您不希望其他网站将您的网站“框”为: 因此,您可以在所有页面中插入反框架,框架破坏JavaScript: 优秀的!现在,您可以自动“破坏”或突破包含iframe的任何内容。除了一个小问题。 事实证明, 您的框架破坏代码可以被破坏, 此代码执行以下操作: 每当浏览器尝试通过事件处理程序导航到当前页面之外时,都会增加一个计数器 设置一个计时器,通过触发每毫秒触发一次的计时器,如果看到计
-
大量埃拉托色尼筛c
就像这个问题一样,我也在厄拉多塞的筛子上工作。同样来自《c语言编程原理和实践》一书的第4章。我能够正确地实现它,并且它的功能完全符合练习的要求。 现在,我怎样才能在输入的中处理真正的大数字?类型应该允许我输入2^32=4,294,967,296的数字。但是我不能,我运行内存溢出。是的,我已经计算过了:存储2^32量的int,每个32位。所以32/8*2^32=16 GiB的内存。我只有4 GiB…
-
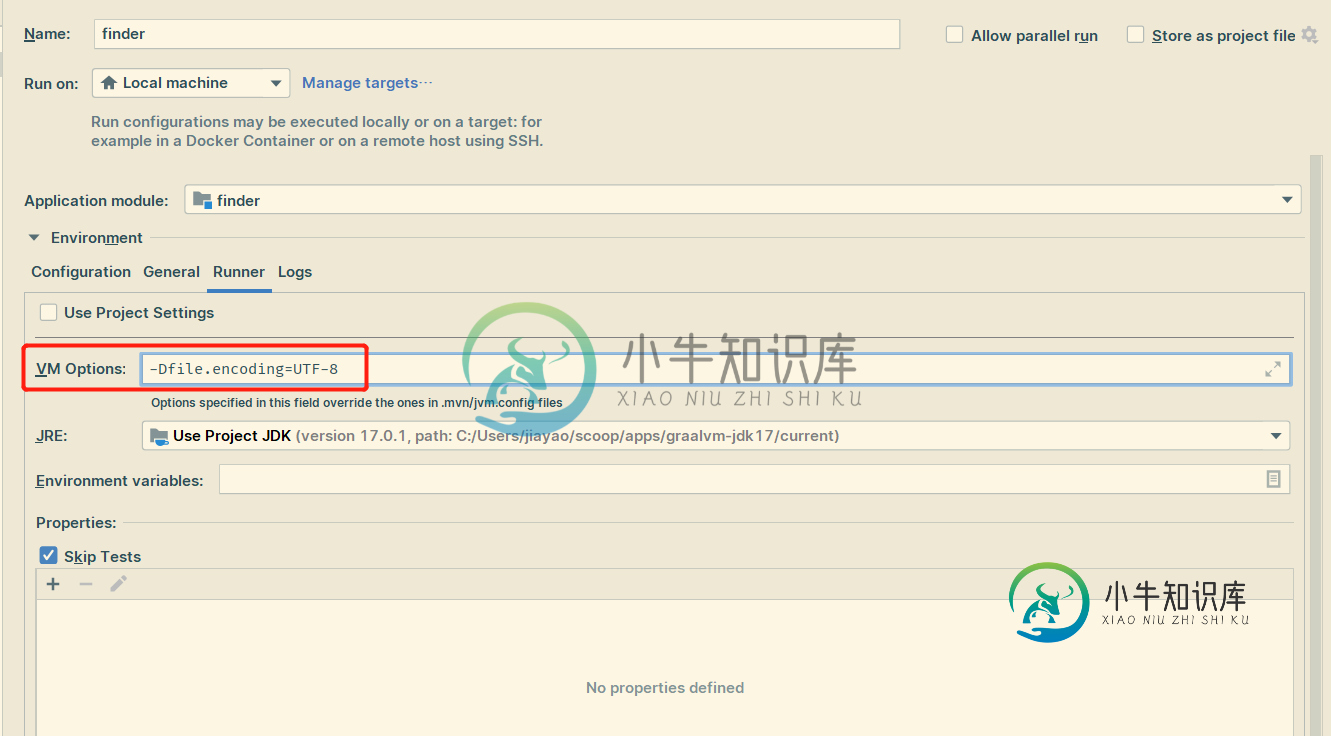 在IDEA中直接运行夸克斯时汉字显示不正确
在IDEA中直接运行夸克斯时汉字显示不正确在IDEA中直接运行quarkus时,汉字显示不正确。 IDEA版本:IntelliJ IDEA 2021.3(终极版) 当我用idea的run函数直接启动quarkus时,无论我的文件是什么。编码参数设置为UTF-8或GBK,无法正确显示汉字,如下图所示: 但是当我在终端中运行quakus: dev时,汉字显示正确,如图所示: 我不知道这个问题的原因是想法、quarkus工具或quarkus框架
-
谷歌云视觉API文本检测谷歌。加克斯。错误。RetryError:GaxError
我是谷歌API的新手。最近,我使用了Google Vision API,但遇到了以下问题: 我尝试了“创建服务帐户”的解决方案,以生成服务json键并在py中调用它。脚本,它将在几乎3~4个url中首先工作,但在下一个url中会出错。这是我的检测代码: 我在另一个py中调用“detect.py”。脚本:
-
转换蟒蛇 Lambda 函数而不将值返回到派斯帕克
我在Python中有一个有效的lambda函数,它计算dataset1中的每个字符串和dataset2中的字符串之间的最高相似度。在迭代过程中,它将字符串、最佳匹配和相似性以及一些其他信息写入bigquery。没有返回值,因为该函数的目的是向bigquery数据集中插入一行。这个过程需要相当长的时间,这就是为什么我想使用Pyspark和Dataproc来加速这个过程。 将熊猫的数据帧转换成spar
-
如何使用"IO String"作为一个HTTP响应在哈斯塔克?
我正在使用HDBC从数据库检索数据,然后尝试使用Happstack将这些数据发送到web客户端。 当我构建上面的代码我得到这个错误: 没有因使用“toResponse”而产生的(ToMessage(IO字符串))实例 我试了什么? 我尝试将转换为(例如使用)。 我试图在这里找到任何类似的问题。 我试图找到一个类似的例子在幸福堆栈速成班。 我谷歌了所有不同组合的相关关键词。 提前感谢。
-
尽早停止詹金斯管道工作
问题内容: 在我们的Jenkins Pipeline工作中,我们有两个阶段,我想要的是,如果其中任何一个阶段失败,那么停止构建,而不继续进行下一个阶段。 这是其中一个阶段的示例: 该脚本将失败,并且生成结果将更新,但是作业将继续进行到下一个阶段。发生这种情况时,我该如何中止或停止工作? 问题答案: 基本上,这就是该步骤的作用。如果不将结果捕获到变量中,则可以运行: 如果脚本生成非零的退出代码,则将
-
 我如何安排詹金斯的工作?
我如何安排詹金斯的工作?我在詹金斯增加了一份新工作,我想定期安排。 在配置作业中,我选中了“定期构建”复选框,并在计划文本字段中添加了以下表达式: 15 13*** 但它不会在预定时间运行。 安排工作是正确的程序吗? 作业应在凌晨4:20运行,但未运行。
-
允许晋升詹金斯管道工作
我有一个詹金斯管道,负责大约5个阶段(构建和几个不同的测试)。我正在从Jenkins1.xx(没有管道)迁移到Jenkins2,我希望尽可能地复制我的过程。我在J2上设置的管道作业处理的一切都完全相同,除了使用JenkinsFile。唯一的问题是,管道插件似乎不支持特定构建的推广,就像你可以做的自由式工作一样。有人找到办法了吗?
-
Flink工作部署在库伯内特斯
我正在尝试在Kubernetes集群(Azure AKS)中部署Flink作业。作业群集在启动后立即中止,但任务管理器运行正常。 docker镜像创建成功,没有任何异常。我可以运行docker镜像,也可以SSHdocker镜像。 我已经按照以下链接中提到的步骤: https://github.com/apache/flink/tree/release-1.9/flink-container/kub
-
约克
背景:我正在使用jOOQ访问Firebird数据库。Firebird 2. x的行大小限制为64KB。我以前从未达到过限制,但是这个特定的数据库使用UTF8,这意味着限制缩小到大约16K个字符。 以下是我使用jOOQ的方式: > 根据需要加载或创建POJO(已生成)。例如。: 根据需要使用book对象。 如果用户保存更改,则将其存储回记录。 步骤3在方法上失败,因为jOOQ不知何故正在将所有空的字
-
spring克朗vs普通克朗?
我正试图在一个遗留的Java/spring/冬眠项目中工作一个cron作业,所以我决定使用spring调度器。 我想让MyTask.DoStuff在每个月的第一个星期天12点运行。 在application-context.xml中,我对任务调度程序进行了如下配置: 问题cron表达式本身是:0 0 12?1/1太阳#1* 而是一个bean,它有一个名为的方法,当从单元测试运行时,该方法可以很好地