《顺丰同城》专题
-
顺时针旋转数组
假设我有这样的多维数组:
-
定位顺风CSS文件
这里有人使用tailwindcss吗?作为一个无知的新手,有人能告诉我你如何访问显示更改的基本css文件吗。我正在使用vite、POSTSS和自动刷新器。 或者我如何建造它?
-
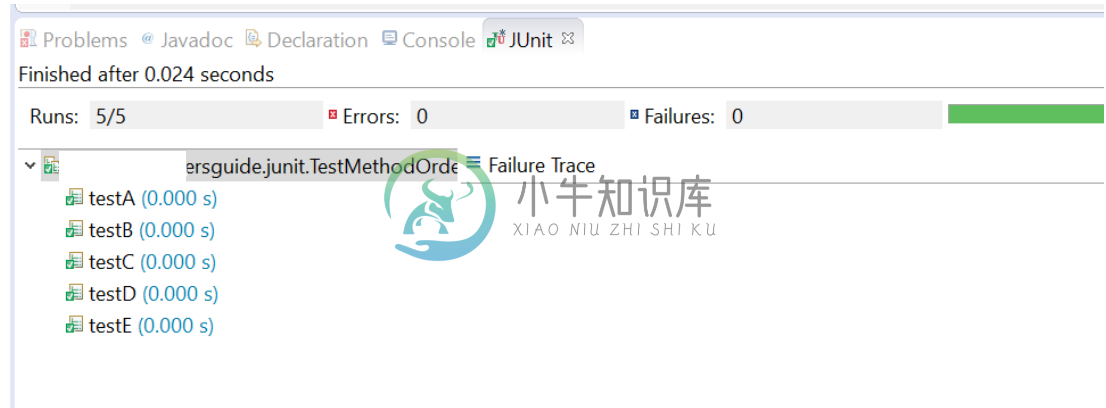 Junit4 执行顺序测试
Junit4 执行顺序测试主要内容:1 概述,2 测试执行顺序,3 例子,4 结论1 概述 在本指南中,我们将学习如何按顺序执行测试。默认情况下,JUnit以任何顺序执行测试。 2 测试执行顺序 要更改测试执行顺序,只需使用@FixMethodOrder注释测试类并指定可用的MethodSorters之一: @FixMethodOrder(MethodSorters.JVM):按照JVM返回的顺序保留测试方法。此顺序可能因运行而异。 @FixMethodOrder(Method
-
python unittest的执行顺序
问题内容: 我需要为测试设置执行顺序,因为我需要先验证一些数据。可以下订单吗? 谢谢 问题答案: 最好不要这样做。 测试应该是独立的。 要做您最想做的就是将代码放入测试调用的函数中。 像那样: 甚至拆分测试类,并将断言放入setUp函数中。 当我拆分班级时,我经常编写更多更好的测试,因为测试被拆分,并且在应该测试的所有情况下我都能看到更好的结果。
-
顺序运行NPM脚本
问题内容: 假设我有 我可以运行什么NPM命令以使所有这些脚本按顺序启动。当我使用前/后修复时,它们顺序启动,但是它们不等待父脚本完成才执行。我假设唯一的解决方案是:在async.series辅助函数中触发shell命令时,如何使Gulp任务依次触发??我知道可以使用Gulp做到这一点,但我现在想坚持使用NPM来探索其功能。谢谢你的帮助! 问题答案: 通过npm run调用这些脚本,并用双“&”号
-
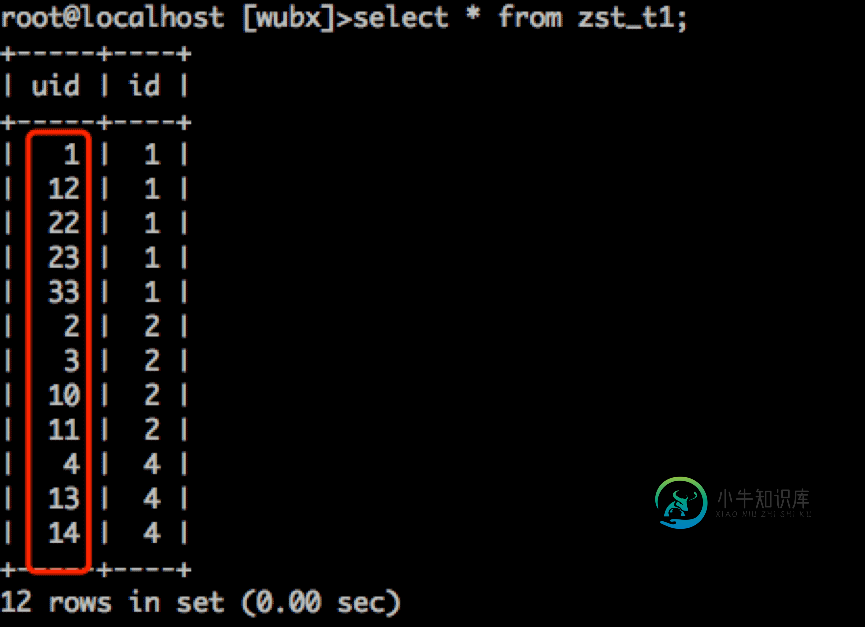 Innodb表select查询顺序
Innodb表select查询顺序本文向大家介绍Innodb表select查询顺序,包括了Innodb表select查询顺序的使用技巧和注意事项,需要的朋友参考一下 今天知数堂一个学生反馈说在优化课中老师讲Innodb是以主键排序存储,读取的时间以主键为顺序读取,但发现个例外,如下: 写入数据: 执行查询: select * from zst_t1; 为什么这个顺序是乱的,不按顺序排列呢?难道Innodb表并不是全按主键存储? 使
-
字典中的键顺序
问题内容: 我有一本字典 但是,我需要字典的顺序不同: 做这个的最好方式是什么? 问题答案: 字典 没有顺序 。因此,没有办法做到这一点。 如果您使用的是python2.7 +,则可以使用-在这种情况下,您可以使用检索项目列表,然后将其反向并从反向列表中创建一个新项: 如果您使用的是旧版python,则可以从http://code.activestate.com/recipes/576693/获得
-
定义类型的顺序
将变量定义为和或其他类型时,是否有优先顺序/惯例/规则? e、 g.是 和一样 功能有什么不同吗?在上面,a是可变的。
-
顺序增量跳过数
我在PostgreSQL中有类似的设置。(如果有区别的话,我使用的是运行Mojave的mac)。 我还有几个专栏,但问题是ID专栏。这被设置为连续的,所以使用Express我将其插入到DB中。 问题是,即使插入失败,它也会在每次插入时增加ID<代码>信息定义为唯一的,因此尝试插入现有的信息会返回错误。但是ID仍然是递增的。 例如,如果插入2行,则id为1 我是否可以设置Postgres,使其不会在
-
点燃的数据->顺序
我使用codeigniter与数据,我想按一列选择。 我该怎么做? 谢谢
-
在node.js中顺序执行
问题内容: 我有类似的代码 它没有在node.js中按顺序执行,因此在执行结束时得到一个空数组。问题是它将先执行然后执行 我的代码中是否有任何错误或执行此操作的任何其他方式?谢谢! 问题答案: 您可能已经知道,事情在node.js中异步运行。因此,当您需要使事物按特定顺序运行时,您需要利用控件库或基本上自己实现。 我强烈建议您看一下async,因为它可以轻松地使您执行以下操作: 在这里看到的主要内
-
JavaScript setTimeout,操作顺序,clearTimeout
本文向大家介绍JavaScript setTimeout,操作顺序,clearTimeout,包括了JavaScript setTimeout,操作顺序,clearTimeout的使用技巧和注意事项,需要的朋友参考一下 示例 setTimeout 等待指定的毫秒数后执行功能。 用于延迟执行功能。 语法: setTimeout(function, milliseconds)或window.setTi
-
顺序图逆向工程
问题内容: 我正在寻找一种将Java反向工程为序列图的工具,但BUT还提供了过滤出对某些库的调用的功能。 例如,Netbeans IDE在这方面做得很出色,但它包含对String或Integer的所有调用,这些调用使图表混乱到无法使用的地步。 任何帮助是极大的赞赏!!!!!!! 问题答案: 我认为jtracert是您想要的。它从正在运行的Java程序生成序列图。同样,由于其输出是图表的文本描述(采
-
打印的执行顺序
问题内容: 该程序输出- 它不应该提供输出- 因为首先ai应该打印1,然后执行a.getI()并应该打印A 2 问题答案: 在此表达式中: 首先评估对的调用,然后通过连接加号形成字符串
-
定义列表的顺序
问题内容: 我有以下问题。我有三个类,A,B和C。A包含一个与B:s相关的一对一列表。B包含与C的ManyToOne关系。C包含一个名为“名称”的字段,B也包含一个名为“名称”的字段。我要完成的工作是让A列表中的项目主要按C的名称排序,然后按B的名称排序- 问题是我不知道该怎么做。可能吗? 我使用EclipseLink作为我的JPA提供程序。 编辑是,我尝试了不同的变体,例如@OrderBy(“