
Innodb表select查询顺序

今天知数堂一个学生反馈说在优化课中老师讲Innodb是以主键排序存储,读取的时间以主键为顺序读取,但发现个例外,如下:
CREATE TABLE zst_t1 ( uid int(10) NOT NULL AUTO_INCREMENT, id int(11) NOT NULL, PRIMARY KEY ( uid ), KEY idx_id ( id ) ) ENGINE=InnoDB;'
写入数据:
INSERT INTO zst_t1 VALUES (1,1),(12,1),(22,1),(23,1),(33,1),(2,2),(3,2),(10,2),(11,2),(4,4),(13,4),(14,4);
执行查询:
select * from zst_t1;
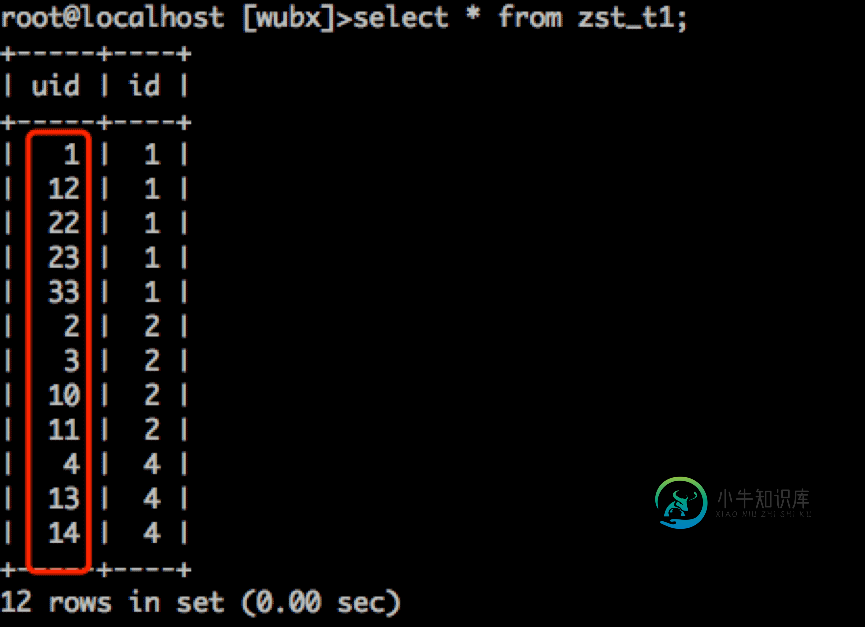
为什么这个顺序是乱的,不按顺序排列呢?难道Innodb表并不是全按主键存储?
使用innodb_ruby这个工具查看一下存储结构什么样
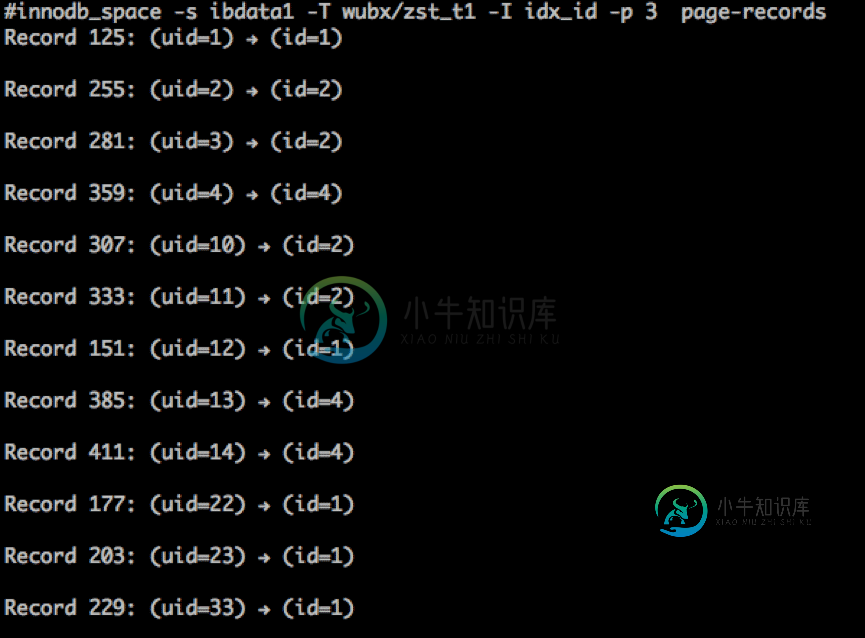
看样子存储还是按主键排序存储的。没毛病。
再来看一下该表的索引:
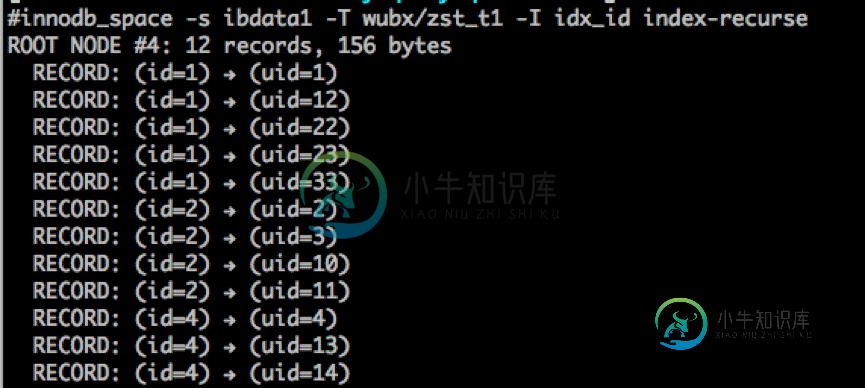
看到这里应该明白了怎么会事了吧,原来这个查询是走的索引覆盖,没有在进行回表读取原数据。另外,也在此说明,Innodb二索索引包含了主键存储。
来继续证明一下:

看到using index 吧,表示这个查询利用索引查询出来结果,不用读取原表。
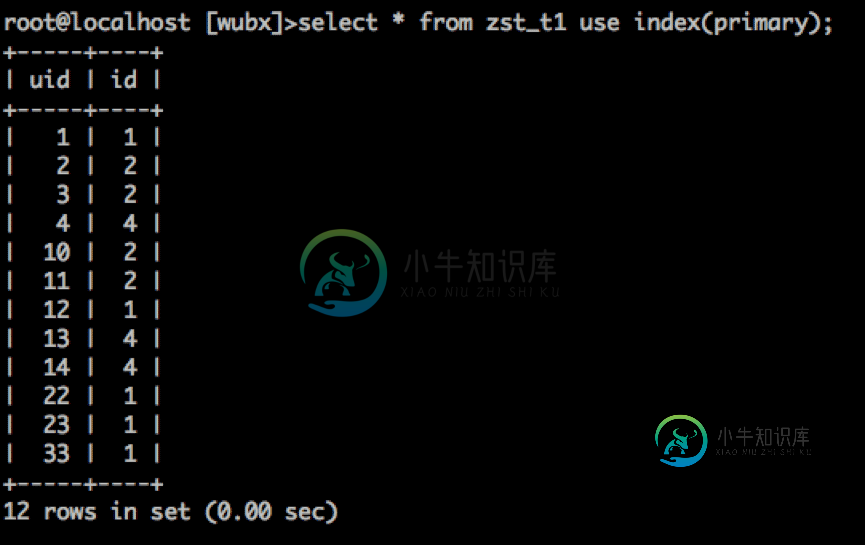
那么我们给造一个通过主键读取数据操作:
select * from zst_t1 use index(primary);

select * from zst_t1 use index(primary); #确认一下。
总结:
这个其实就是一个索引包含的查询案例。 如果静下来思考一下,也许很快就明白了。也不用这样去查问题。
技术在于折腾,多搞搞就明白了:)。
-
select 数据库查询select($table, $columns, $where) table [string] 表名. columns [string/array] 要查询的字段名. where (optional) [array] 查询的条件.select($table, $join, $columns, $where) table [string] 表名. join [array] 多
-
select 数据库查询select($table, $columns, $where) table [string] 表名. columns [string/array] 要查询的字段名. where (optional) [array] 查询的条件.select($table, $join, $columns, $where) table [string] 表名. join [array] 多
-
问题内容: 我从a取值并将其设置为内部条件 如 但这是行不通的。有什么建议? 问题答案: 尝试修剪字符串以确保没有多余的空格: 也可以使用@thinksteep之类的方法。
-
本文向大家介绍postgresql SELECT查询中的公用表表达式,包括了postgresql SELECT查询中的公用表表达式的使用技巧和注意事项,需要的朋友参考一下 示例 公用表表达式支持提取较大查询的部分。例如:
-
问题内容: 我需要检查(从同一张表)基于日期时间的两个事件之间是否存在关联。 一组数据将包含某些事件的结束日期时间,另一组数据将包含其他事件的开始日期时间。 如果第一个事件在第二个事件之前完成,那么我想将它们链接起来。 到目前为止,我有: 然后我加入他们: 然后,可以基于我的validation_check字段运行带有SELECT嵌套的UPDATE查询吗? 问题答案: 您实际上可以通过以下两种方式
-
问题内容: 我在名为“ cards”的INNODB表中大约有20,000行,因此FULLTEXT不是一种选择。 请考虑以下表格: 因此,假设用户搜索“ John”,我希望结果集按以下顺序排列: 请注意,我们只拉过一次“约翰·史密斯”,我们接过他的最新条目。根据我的数据,所有名称均指同一个确切的人,而无需担心两个名为John Smith的家伙。有想法吗?让我知道是否可以澄清任何事情。 问题答案: 版