《顺丰同城》专题
-
Stream.forEach是否遵守顺序流的遇到顺序?
问题内容: Javadoc 表示(重点是我): 该操作的行为明确地是不确定的。 对于并行流管道,此操作不能保证遵守流的遇到顺序 ,因为这样做会牺牲并行性的好处。对于任何给定的元素,可以在库选择的任何时间和线程中执行操作。如果操作访问共享状态,则它负责提供所需的同步。 Java 9 Early Access Javadoc中提供了相同的文本。 第一句话(“明确地不确定”)表明(但未明确说明)此方法未
-
先按字母顺序,然后按数字顺序
问题内容: 我在mysql排序中寻找一些调整,我通常从表中选择记录,然后按Name(varchar)ASC排序记录, 但编号始终是第一位的 这是我的问题的一些示例( 注意。mysql首先用0-9排序记录 ) 我想要的是字母顺序,然后是数字 所需的输出 问题答案: 使用以下子句:
-
Stream.foreach是否尊重顺序流的相遇顺序?
的Javadoc表示(强调是我的): 此操作的行为显式不确定。对于并行流管道,此操作不能保证尊重流的相遇顺序,因为这样做会牺牲并行性的好处。对于任何给定的元素,操作可以在库选择的任何时间和线程中执行。如果操作访问共享状态,则它负责提供所需的同步。 同样的文本也出现在Java9早期访问Javadoc中。 如果forEach不保留遭遇顺序,则会引入bug。在报告针对NetBeans的bug之前,我想知
-
为什么我会得到不同的答案以不同的顺序乘以三个双倍值?[副本]
我正在java中执行以下代码,但对于数学上应该是相同的数字,我得到了两个不同的答案。 输出:
-
为什么打印时Go的地图迭代顺序会有所不同?
问题内容: 上面的go代码仅打印一次map [string] string三次。 我希望它具有固定的输出,但它显示如下: 变了! 而在python中: 输出: 问题答案: 您不能依靠获得密钥的顺序。语言规范说: “一个映射是一组无序的元素”,后来又说: “未指定映射的迭代顺序,并且不能保证每次迭代之间都相同。”
-
Java8流的顺序执行和并行执行产生不同的结果?
问题内容: 在Java8中运行以下流示例: 产量: 当然-这并不奇怪。由于http://docs.oracle.com/javase/8/docs/api/index.html?overview- summary.html ,流是顺序执行还是并行执行都没有关系: 除了标识为明确不确定的操作(例如findAny())之外,流是顺序执行还是并行执行都不应该更改计算结果。 AFAIK 是确定性的并且是关
-
Maven:如何在同一阶段按特定顺序多次执行目标
我希望我的“预集成测试”阶段是以下目标的执行,按照这个特定的顺序。 阶段:预集成测试 获取一个Spring Bootjar(maven-依赖-插件:复制) get-a-port(build-helper-maven-plugin:保留网络端口) 显示端口(maven-antrun-plugin:运行#1) 启动服务器(exec-maven-plugin) 等待启动(maven-antrun-plu
-
JUnit~断言list以任意顺序包含具有相同值的对象
要抽象出来,请考虑以下示例: 我正在寻找一个断言方法,该方法在比较上述任何与时通过,但在比较上述任何与时失败。 目前,我最接近的是: 值得注意的是,以下操作也将失败,因为Apples虽然包含相同的值,但不是相同对象的实例: 在JUnit中有没有一种简单的方法来做出这样的断言?我知道我可以为对象的迭代编写一个自定义断言方法,但不知何故,这似乎是一个常见的用例,应该有一个预定义的断言方法,该方法会引发
-
中返回值和返回promise时,执行顺序有何不同。然后?
原文是这样的: 这确实令人惊讶,但最终明白了(嗯,至少我想我明白了)为什么会这样发生。 现在,我将第二个更改为: 如果我遗漏了一些明显的东西,或者我的问题是愚蠢的,让我提前说声对不起。还有谢谢你!
-
从ssh命令以创建命令的相同顺序记录stdout和stderr
问题内容: 简短版本: 是否可以将sdout和stderr记录在通过ssh远程执行的命令的本地端上,其顺序与在远程主机上输出的顺序相同?如果是这样,怎么办? 长版: 我试图记录远程执行的SSH命令(使用Jsch)的标准和错误输出,其顺序与远程命令的输出顺序相同。换句话说,如果远程命令将“ a”写入stdout,然后将“ b”写入stderr,然后将“ c”写入stdout,则我希望客户端(本地)端
-
weka“测试分割预测”未按与数据相同的顺序列出
考虑以下虚构的arff文件: 使用WEKA 3-8,在Explorer中打开上述ARFF。单击分类。选择J48分类器,保留所有默认设置。在“测试选项”下,选择“百分比分割=50%”。单击“更多选项”,选择“输出预测”- 点击开始 您将看到以下输出: //跳过报告的其余部分... 注意输入arff文件中的最后五个实例是按顺序排列的 双赢-输-赢 然而,实际输出“测试分割预测”的顺序是:输赢赢赢 为什
-
从3个线程按顺序打印3个不同的数字范围
采访中问 有三条线。第一条线打印100到199个数字。第二个线程打印200到299之间的数字。第三条线从300到399。执行的顺序是
-
断言两个列表按一定顺序具有相同的子类型
我想检查两个列表(比方说,ArrayList)是否有完全相同的实例类,基于预期的列表。为此,我构建了下一个方法,但我想知道是否有另一种使用某些库的奇特方法,比如assertJ。 任何建议都是非常受欢迎的。谢谢
-
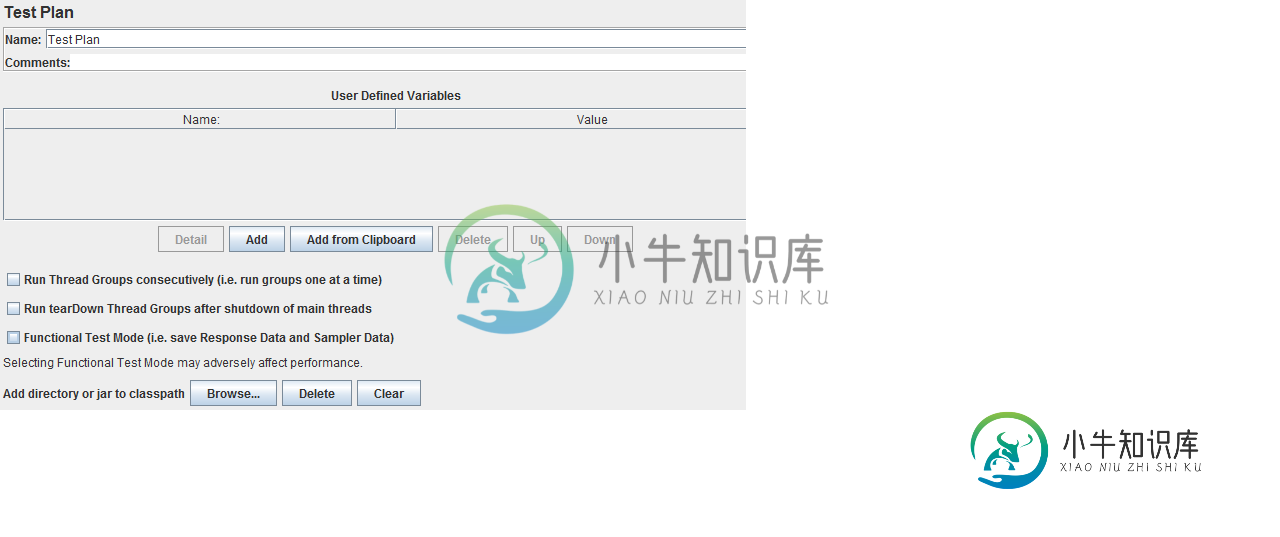 JMeter-并行和顺序线程组在同一测试计划中执行
JMeter-并行和顺序线程组在同一测试计划中执行我的jmeter测试计划如下所示, 并且我的测试计划配置设置为并行运行所有线程组 在这里,我想依次执行线程组1,然后执行线程组2,同时执行相同的线程组3,然后执行线程组4,但是线程组1和线程组3并行执行
-
设置数据表“(组,-值.1)”的显示顺序,同时保留键“id”
是否可以在保留其键的同时存储 行? 假设我有下面的虚拟表: 我想存储此表,以便行按排序,并按按递减顺序排序,即: 显然,我可以将它保存为一个新变量,但是我还想将< code>id列作为我的主键。 Arun对“在data.table中设置键的目的是什么?”建议这可以通过巧妙使用< code>setkey来实现,因为它按照键的顺序对data.table进行排序(尽管没有将键设置为降序的选项): 但是,