《工商银行四川省分行》专题
-
仅将某些行与GROUP BY分组
问题内容: 施玛 我在MySQL数据库中进行了以下设置: 问题 我需要选择: *具有该值的 *所有 项目都具有价值, 并且 *每个组中的 *一项以 最低的 价格确定。 预期成绩 可能的解决方案1: 两个查询 但是,不希望有两个查询,因为子句中的条件会更复杂,而且我需要对最终结果进行排序。 可能的解决方案2: 关于表达式(参考) 解决方案2似乎更快速,更易于使用,但是我想知道在性能方面是否有更好的方
-
SQL Server 2008分区表和并行性
问题内容: 我的公司正在迁移到SQL Server 2008 R2。我们有一个包含大量存档数据的表。使用该表的大多数查询在where语句中使用DateTime值。例如: 查询1 我假设分区是在CreatedDate上创建的,并且每个分区都分布在多个驱动器上,我们有8个CPU,数据库中有5亿条记录平均分布在2008年1月1日之间的日期中到2011年2月24日(38个分区)。该数据也可以分成一年的四分
-
在运行时动态分配ng-controller
问题内容: 我有一种需要动态更改控制器的情况,以便相应地影响范围变量。总体结构: 我在这里看到它可以在一个。可以在外面做吗?换句话说,我可以告诉angular将其读取为变量而不是字符串文字吗? 问题答案: 正如评论中所讨论的那样,具有用于处理这些情况的强大 功能/库 - (具有强大的 Wiki ) 。 这是需要开发功能块- 状态 的答案,而不是在视图/ URL中进行思考 (从首页引用) : Ang
-
Python:区分行向量和列向量
问题内容: 有没有一种很好的方法来区分python中的行向量和列向量?到目前为止,我正在使用numpy和scipy,到目前为止,我看到的是,如果我要给一个向量,说 他们无法说天气,我的意思是行或列向量。此外: 在“现实世界”中哪一个根本是不正确的。我意识到上述模块中向量上的大多数功能都不需要区分。例如,或者我想为自己的方便而与众不同。 问题答案: 您可以通过向数组添加另一个维度来明确区分。 现在将
-
用Order By计算分区中的行
问题内容: 我试图通过编写一些示例查询来了解postgres中的PARTITION BY。我有一个运行查询的测试表。 当我运行以下查询时,我得到了预期的输出。 但是,当我将ORDER BY添加到分区时, 我的理解是,COUNT是在属于分区的所有行中计算的。在这里,我按 num 对行进行了分区。不论是否带有ORDER BY子句,分区中的行数都是相同的。为什么输出会有所不同? 问题答案: 当您将an添
-
Spring集成拆分器任务执行
我正在开发一个Spring集成应用程序。 我有一个入站通道适配器,用于读取目录,然后是一个拆分器,用于将文件拆分为行,最后是一个udp出站通道适配器,用于发送行 我想每秒钟发一封信 我可以通过定义自己的拆分器并在每次读取一行时等待1s来做到这一点,但我想知道是否可以在xml文件中尽可能简单地完成它。 提前谢谢
-
Python代码行太长,需要拆分
如果可能的话,我如何用更少的代码将下面所示代码的结尾部分移到另一行或修改文本,以实现所需的结果。我键入了以下代码: 我试图实现的是显示以下数据:-仅显示,仅显示Dakota Spitfire和Hurricane或Dakota和Spitfire或Dakota和两个Spitfire,如果它们显示在数据表明细表中,则完整代码如下。需要编辑的是从Southport=开始的行: 当我运行代码时,我得到以下回
-
grep 仅打印行的匹配部分
本文向大家介绍grep 仅打印行的匹配部分,包括了grep 仅打印行的匹配部分的使用技巧和注意事项,需要的朋友参考一下 示例
-
使用Python Pandas进行数据分析
本文向大家介绍使用Python Pandas进行数据分析,包括了使用Python Pandas进行数据分析的使用技巧和注意事项,需要的朋友参考一下 在本教程中,我们将看到使用Python pandas库进行的数据分析。图书馆的熊猫都是用C语言编写的。因此,我们在速度上没有任何问题。它以数据分析而闻名。我们在熊猫中有两种类型的数据存储结构。它们是Series和DataFrame。让我们一一看。 1.
-
tensorflow 1.0用CNN进行图像分类
本文向大家介绍tensorflow 1.0用CNN进行图像分类,包括了tensorflow 1.0用CNN进行图像分类的使用技巧和注意事项,需要的朋友参考一下 tensorflow升级到1.0之后,增加了一些高级模块: 如tf.layers, tf.metrics, 和tf.losses,使得代码稍微有些简化。 任务:花卉分类 版本:tensorflow 1.0 数据:flower-photos
-
Python-将行拆分为列-csv数据
正在尝试从csv文件中读取数据,将每行拆分为各自的列。 但是,当某个列本身带有逗号时,我的正则表达式就失败了。 例如:a, b, c,"d, e, g,", f 我想要的结果是: 也就是5列。 下面是用逗号分隔字符串的正则表达式am ,(?=(?:“[^”]?(?:[^”])*)),(?=[^”](?:,),$) 但是它对少数字符串失败,而对其他字符串有效。 我想要的是,当我使用pyspark将c
-
使用DynamoDBMapper Java AWS SDK进行分页
从API文档来看,dynamo db确实支持扫描和查询操作的分页。这里的关键是将当前请求的设置为上一个请求的的值,以获得下一组(逻辑页面)结果。 我试图实现同样的功能,但我使用的是,它似乎有很多优点,比如与数据模型紧密耦合。因此,如果我想做上述工作,我假设我会做如下工作: 我希望我的上述理解是正确的分页使用DynamoDBMapper。其次,我怎么知道我已经达到了结果的终点。如果我使用以下api,
-
执行子项目的分级任务
我知道我能做到 但这也会得到projA和projB,我只想在c,d,E上运行任务...请让我知道实现这一点的最佳方法。
-
将数据分组后筛选行[duplicate]
我有下面的数据 我必须根据(a)列对数据进行分组,然后我必须删除具有相同(b)值的行。下面我展示了它应该是什么样子, 熊猫有什么简单的方法可以做到这一点吗?
-
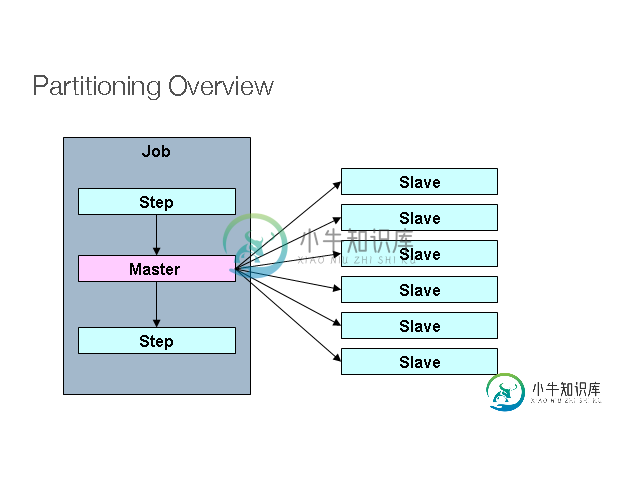 多步并行的Spring批量分区?
多步并行的Spring批量分区?我不确定使用spring Batch是否可行。任何想法或我都无法实现它。谢谢。