《实习与准备秋招该如何平衡》专题
-
与(int)一样取消对void*的引用--标准实践?
我试图打印线程的返回值,发现我仍然对双空指针的概念感到困惑。 我的理解是,空格*是指向任何数据类型的指针,这些数据类型可以通过适当的强制转换来解除引用,但是否则引用的“级别”会像常规类型的指针一样保留下来(也就是说,你不能期望得到与放入 **(int**)Depth2通过像 那样只取消引用一次。)。 然而,在我为线程返回打印而拼凑的代码(如下)中,当我只是将空指针强制转换为(int)时,似乎根本没
-
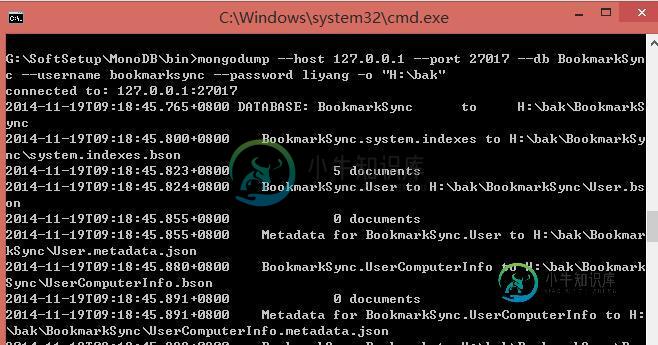 Mongodb数据库的备份与恢复操作实例
Mongodb数据库的备份与恢复操作实例本文向大家介绍Mongodb数据库的备份与恢复操作实例,包括了Mongodb数据库的备份与恢复操作实例的使用技巧和注意事项,需要的朋友参考一下 写在前面 本文已经假设你已经安装好了Mongodb(2.6),并且已经开启了auth。 用户 首先我们添加备份和恢复数据所需的用户,这个用户需要有readWrite和userAdmin权限 备份 注:此命令是在控制台中执行 我们使用mongodump来进行
-
C#实现的SQL备份与还原功能示例
本文向大家介绍C#实现的SQL备份与还原功能示例,包括了C#实现的SQL备份与还原功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C#实现的SQL备份与还原功能。分享给大家供大家参考,具体如下: 更多关于C#相关内容感兴趣的读者可查看本站专题:《C#常见控件用法教程》、《C#窗体操作技巧汇总》、《C#数据结构与算法教程》、《C#面向对象程序设计入门教程》及《C#程序设计之线程使用技
-
消费组与分区重平衡
本文向大家介绍消费组与分区重平衡相关面试题,主要包含被问及消费组与分区重平衡时的应答技巧和注意事项,需要的朋友参考一下 当有新的消费者加入到消费者组时,原本的分区就需要重新分配;比如一个topic有30个分区,原本只有两个消费者,每人负责15个分区,当新加入一个消费者时,并没有分区可以给他消费,只能是将30个分区重新分配。 每个消费者组都会有一个broker负责协调(称为group coordin
-
1.3.1. 平衡风险与可用性
1.3.1. 平衡风险与可用性 用户操作的友好性与安全措施是一对矛盾,在提高安全性的同时,通常会降低可用性。在你为不合逻辑的使用者写代码时,必须要考虑到符合逻辑的正常使用者。要达到适当的平衡的确很难,但是你必须去做好它,没有人能替代你,因为这是你的软件。 尽量使安全措施对用户透明,使他们感受不到它的存在。如果实在不可能,就尽量采用用户比较常见和熟悉的方式来进行。例如,在用户访问受控信息或服务前让他
-
字符串实习在Java 7+中如何工作?
问题内容: 因此,我意识到我要问的问题与一个又一次被折磨致死的话题有关,但是,即使阅读了所有我能找到的答案和文档,我仍然对此感到困惑字符串实习。也许是由于我对JVM缺乏了解;可能是由于Java 7中引入的更改使上述许多答案和文档贬值了。无论哪种方式,我都被困住了,希望有人可以帮助我更清楚地理解这个概念… 在上面的示例中,我知道将创建两个String对象。我也明白,内存中将只有一个包含序列的char
-
如何使JTextPane水平滚动
问题内容: 我有一个,当行太多时,会出现滚动条,但是当行太长时,该行会分成两行,而不是出现水平滚动条,如何使水平条出现而不是分成两行,我的添加如下: 问题答案: 正如我们自己的Rob Camick 在这里介绍的那样,您可以尝试使用类似… 这将停止行/自动换行
-
如何平滑缩放画布?
问题内容: 如何才能平滑地为画布创建缩放动画?GWT提供了一种获取滚轮数量的方法和。 这里的问题是,每个车轮运动都会执行此方法,并且如果我在该方法本身中调用画布重绘,事情会变得很滞后。 因此,我想到了以某种方式制作缩放动画的方法。但是如何? 我考虑过创建一个,但没有真正的主意,因为只有mousewheelevent作为起点,而用户没有完成用滚轮缩放的终点… 问题答案: 这是我用来缩放图像的可伸缩图
-
如何找到最大平均
问题内容: 我试图显示最高平均工资;但是,我似乎无法使其正常工作。 我可以得到要显示的平均薪水清单: 但是,当我尝试显示具有以下项的最大平均薪水列表时: 它没有运行。我收到“无效标识符”错误。如何使用每个工人的平均工资来找到每个工人的最高平均工资? 谢谢。 问题答案: 由聚合函数(例如avg)产生的列通常获得任意名称。只需为其使用别名,然后在其上进行选择:
-
如何展平多维数组?
问题内容: 在PHP中,是否可以在不使用递归或引用的情况下展平(双向/多维)数组? 我只关心的值,这样的键可以忽略不计,我想在的线和。 问题答案: 您可以使用标准PHP库(SPL) “隐藏”递归。 版画
-
如何检查价值平等?
问题内容: 我是Java入门者,所以请忍受这个。 我有一堂课: 我创建两个实例: 我想检查这两点是否在同一位置。明显的方法无效,因为这似乎是“ 对象是否 相等?” 一种测试,这不是我想要的。 我可以做到,但是那种解决方案感觉不好。 如何以优雅的方式获取两个Point对象并测试它们是否相等,协调一致? 问题答案: 标准协议是要实现的方法: 然后就可以使用了。 请注意,完成此操作后,还需要实现该方法。
-
SQLite-如何获得平均值?
问题内容: 我的表中有一列具有FLOAT类型的值。如何获得此列中所有元素的平均值? 问题答案: 这将平均所有行。要平均子集,请使用子句。要平均每个组(某物),请使用by子句。
-
如何让RecyclerView平滑滚动?
-
如何水平翻转图像
HiI想知道如何水平翻转和成像,对于一个practce任务,我得到了一个读取图像的代码,将其反转为指示亮度从0到5的图像,我必须翻转图像。 我得到一个错误
-
PDFBox:如何“展平”PDF表单?
如何使用PDFBox“展平”PDF表单(删除表单字段,但保留字段文本)? 这里回答了同样的问题: 一个快速的方法是从acrofrom中删除字段。 为此,您只需要获取文档曲库,然后是acroform,然后从该acroform中删除所有字段。 图形表示与注释链接并保留在文档中。 所以我写了这段代码: