《Keep内推》专题
-
如何删除内联/内联块元素之间的空间?
问题内容: 鉴于此HTML和CSS: 结果,SPAN元素之间将有4像素宽的空间。 我知道为什么会发生这种情况,而且我也知道可以通过删除HTML源代码中SPAN元素之间的空白来摆脱该空间,如下所示: 但是,我希望找到一种不需要篡改HTML源代码的CSS解决方案。 我知道如何使用JavaScript解决此问题-通过从容器元素(该段)中删除文本节点,如下所示: 但是,仅靠CSS就能解决这个问题吗? 问题
-
Java内部类应用之静态内部类应用示例
本文向大家介绍Java内部类应用之静态内部类应用示例,包括了Java内部类应用之静态内部类应用示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Java内部类应用之静态内部类。分享给大家供大家参考,具体如下: 一 点睛 如果使用static来修饰一个内部类,则这个内部类就属于外部类本身,而不属于外部类的某个对象。因此使用static修饰的内部类被称为类内部类,也称为静态内部类。 stat
-
在内存中加载大字典的内存使用量大
问题内容: 我的磁盘上只有168MB的文件。这只是一个逗号分隔的单词,id的列表。该单词的长度可以为1-5个字符。有650万行。 我在python中创建了一个字典,将其加载到内存中,因此我可以针对该单词列表搜索传入的文本。当python将其加载到内存中时,它显示已使用的1.3 GB RAM空间。知道为什么吗? 假设我的word文件如下所示… 然后再加上650万。然后,我遍历该文件并创建一个字典(p
-
Matplotlib错误会导致内存泄漏。如何释放内存?
问题内容: 我正在运行django应用程序,其中包括matplotlib,并允许用户指定图形的轴。这可能会导致 “溢出错误:超出了Agg复杂度” 发生这种情况时,最多会占用100MB的RAM。通常,我会使用,和释放该内存,但是与该错误关联的内存似乎与该绘图对象无关。 有谁知道我该如何释放记忆? 谢谢。 这是一些给我Agg复杂度错误的代码。 问题答案: 我假设您可以至少运行一次您发布的代码。该问题仅
-
使用Vert. x WebClient支持内容编码和内容解码
当我向请求添加accept编码头时。 垂直方向。x-WebClient/3.9.5忽略此标头,并且我从服务器收到的响应没有“内容编码”标头选项。 相反,它的标题为“传输编码”:“分块”。 如何传递accept encoding=gzip并用Vert解压缩从服务器得到的响应。x-WebClient/3.9.5
-
Nginx正在提供默认内容而不是我的内容
我有一个运行在上。 我使用来提供静态文件,即生成的包,但这是不相关的。 我想要实现的是: 关于我想提供。我能做到。 在我想为。 在我想提供。 最后两个,我做不到。当我进入或我收到了默认的nginx页面。 为了使事情更加混乱被完全注释掉。 此外,如果在的块中,我将替换为,我将获得该特定项目的服务,但是我将无法为另一个服务。 下面,我将向您展示我的nginx配置 谢谢你的帮助! 编辑 我找到的解决方案
-
混合内容问题-内容必须用作HTTPS | | Lumen | | Swagger API
混合内容:页面位于'https://api.xyz.com/api/documentation'已通过HTTPS加载, 但是请求了一个不安全的样式表'http://api.xyz.com/swagger-ui-assets/swagger-ui.css?v=26ec363936a21921c9fec290e551e3eb'. 此请求已被阻止;内容必须通过HTTPS提供。 我知道如何在Laravel
-
Java进程使用的内存比VisualVM显示的内存多
我的java应用程序工作了大约1天,(我使用不同的库来处理照片,比如ffmpeg、javacv、javacpp),然后我看到我的应用程序使用了9,5GB的RAM。 I set-XMX6G 在VisualVM中,我看到堆空间大小为188M visualVM中的堆空间 编辑: 是的,我的应用程序有时会出现异常Java.lang.outofmemoryerror:Java堆空间
-
C语言内嵌汇编API内存搜索引擎实例
本文向大家介绍C语言内嵌汇编API内存搜索引擎实例,包括了C语言内嵌汇编API内存搜索引擎实例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C语言内嵌汇编API内存搜索引擎的方法,分享给大家供大家参考。具体实现方法如下: 希望本文所述对大家的C程序设计有所帮助。
-
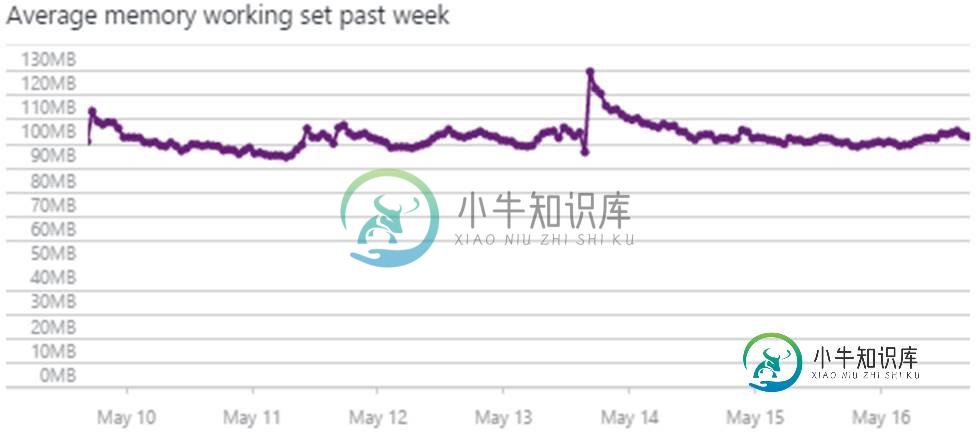 Azure中的平均内存工作集和内存工作集
Azure中的平均内存工作集和内存工作集我在Azure中有一个应用程序服务。它显示了两个称为“平均内存工作集”(Average Memory Working Set)和“内存工作集”(Memory Working Set)的度量。现在,内存工作集被定义为进程中线程最近接触到的内存页集。门户中显示的这两个图形如下所示: 现在,我有三个问题: > 如何找出我的服务的专用最大内存是多少?一旦达到限制会发生什么? 内存工作集是进程中的线程最近接
-
从内部DialogFragment内的主片段调用方法时出错
我想从AlertDialog的setPositiveButton()方法内部的片段调用一个方法,该方法用于返回DialogFragment的对话框,但不能这样做。 我在一个名为Test的类中有doSomething()方法,该类扩展了Fragment。在这个类中,我有一个扩展DialogFragment的内部类。在方法onCreateDialog中,问题就发生在这里。查看代码: 对话片段和片段来自
-
Tensorflow CPU内存问题(分配超过系统内存的10%)
我使用Keras/Tensorflow在python中创建了一个程序。我对数据的创建和训练没有任何问题。但是,当我想评估我的模型时,我有以下错误: 这似乎是一个内存分配问题。我缩小了模型的尺寸,缩小了所有参数,但没有任何变化。我不知道如何解决这个问题。
-
For循环内,而循环内要求用户输入条件
我正在编写一个python游戏,它有以下功能可以向用户询问。 最多可以有4名玩家(最少1名玩家,最多4名玩家) 它会问玩家的名字。如果名称已存在,程序将提示“名称已在列表中”,并要求再次输入名称 如果播放器在播放器名称输入中输入空字符串,它将退出。 它会询问玩家想要玩多少n个随机数字(使用randint(开始,停止)。最多只允许3位数字 我知道我必须使用
-
了解JVM内存分配和Java内存不足:堆空间
我想真正了解内存分配在JVM中是如何工作的。我正在编写一个内存不足的应用程序:堆空间异常。 我知道我可以传入VM参数,如Xms和Xmx,以增加JVM为正在运行的进程分配的堆空间。这是一个可能的解决方案,或者我可以检查我的代码内存泄漏并修复那里的问题。 我的问题是: 1)JVM实际上如何为自己分配内存?这与OS如何将可用内存传递给JVM有什么关系?或者更一般地说,为任何进程分配内存实际上是如何工作的
-
Apache Tika无法使用文件内容检测内容类型
我一直试图仅使用文件内容检测MIME类型,使用Apache Tika Core和Apache Tika Parser1.23 jars。下面是用于相同内容的代码: Tika无法检测扩展名为。tmp(text/plain file)和iso-8859-1字符集的文件的内容类型,内容如下: èé 通过以下方式正确检测具有相同配置和以下内容的文件: 000000000000000000000000000