《天融信》专题
-
 Java保融科技线上一面
Java保融科技线上一面下午5.20开始面试,5点面试官就进入面试间了。还好我提前到了。 1.自我介绍 2.SpringBoot的优点 3.常用的集合的特征 4.Redis应用场景,之前在哪里使用过 5.创建线程的方式 6.使用线程池的好处 7.线程池的核心参数 8.线程的状态 面试官长得很帅气,态度也很好。 忘记问还有没有下一轮技术面试了 #23届找工作求助阵地##春招##校招#
-
 保融科技Java二面面经
保融科技Java二面面经3.1 下午5.20面试 晚上8点就收到二面的通知,不得不感叹效率是真的快 3.2 早上10:30面试开始 1、惯例自我介绍 2、介绍项目,根据项目进行提问,介绍过程中会有针对性地进行提问,考验对实际情况的处理能力。 3、介绍大学生活 4、学习、知识总结的方法 5、聊家常、规划 6、反问 全程35分钟,面试官人很好,很耐心。提出的问题都是比较有针对性和在日常开发过程中需要注意的。 总的来说收获挺多
-
Spring Cloud Alibaba和Dubbo融合实现
本文向大家介绍Spring Cloud Alibaba和Dubbo融合实现,包括了Spring Cloud Alibaba和Dubbo融合实现的使用技巧和注意事项,需要的朋友参考一下 服务提供者 创建一个名为 hello-dubbo-nacos-provider 的服务提供者项目 POM 该项目下有两个子模块,分别是 hello-dubbo-nacos-provider-api 和 hello-d
-
Drools融合:自动生成规则
我正在使用drools fusion,我想根据实现的规则数测试这个cep系统的性能。现在,我有了一个简单的规则文件。drl扩展。我想动态生成大约1000条规则。那么,如何在不让他们在中创建一对一的情况下自动完成此操作呢。drl文件?
-
Spring Kafka Json Schema注册表融合
合流模式注册表当前支持json模式。spring kafka是否支持json模式? 使用此配置,带有spring kafka的Avro运行良好 但如何配置spring kafka以使用json模式汇合模式注册表?
-
融合表:无法完成导入
我断断续续使用融合表已经有一年了。今天,在尝试上传一个156 kb的文件时,它会出现“无法完成导入”。 我试着缩小文件的大小,然后意识到我上传的大多数其他文件都比较大,所以出于好奇,我尝试上传一个以前上传的文件(已经存储为融合表)。这也失败了。我尝试在另一个帐户上上传,但同样的消息也失败了。 有没有无论如何检查,看看是否有一个问题与融合表?我已经阅读了以前的问题,那些与大小无关的问题提到了融合表的
-
融合表kml导入不完整
我正在将一个KML文件导入到fusion表中,发现缺少行—我只得到前4行。我在Google Earth中检查了该文件,所有多边形都显示得很好,因此我确信KML文件没有损坏。 当我第一次在GoogleDrive表中打开该文件时,它有一个注释,其中有17%是导入的,但随后就消失了。似乎导入没有完成。该文件为20MB。 任何提示或建议。我环顾四周,没有发现类似的问题。感谢指导员! PS:如果您对以下问题
-
在Keras中实施后期融合
我正在研究一个包含图像和文本的多模式分类器。我已经开发并成功地实现了两个模型,一个是用于图像的CNN模型,另一个是基于BERT的文本模型。这两个模型的最后一层都是密集的,有n个单元和softmax激活(其中n是类的数量)。Keras提供了不同的合并层,用于合并这些模型的输出向量(https://keras.io/api/layers/merging_layers/)然后就有可能创建一个新的网络,但
-
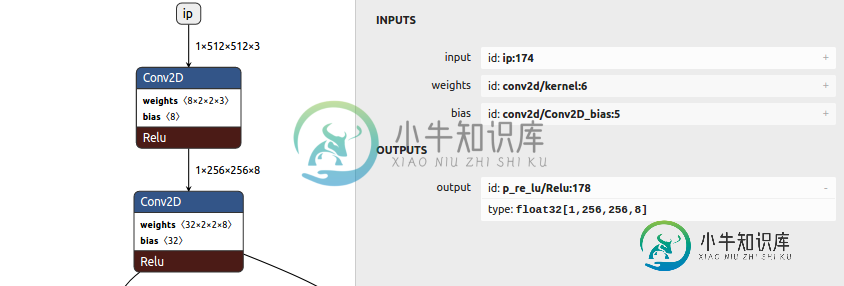 Tensorfow-lite预融合和TransposeConv偏置
Tensorfow-lite预融合和TransposeConv偏置当我们用tf 1.15用PReLU转换tf.keras模型时,PReLU层变成了ReLU,似乎与以前的运算符融合在一起。结果,28 MB的keras h5文件变成了1.3 MB的大小。看起来参数的数量明显减少,因为我没有使用PReLU的份额权重轴选项。那么,这种转换工作正常,没有任何精度损失吗?PReLU的重量是否完全丢弃?同样,融合也考虑到转置卷积层的偏置(偏置在netron中不作为输入属性提及
-
如何融化火花数据帧?
在PySpark中或者至少在Scala中,Apache Spark中是否有与Pandas Melt函数等价的函数? 到目前为止,我一直在用Python运行一个示例数据集,现在我想对整个数据集使用Spark。
-
Protege中两个本体的融合
我对使用Protege还不熟悉。我正在使用两个小的owl文件,都包含一个超级类和两个子类。除了类名之外,这两个本体完全相同。我将这两个文件导入到一个新文件中,并使用refactor菜单将一个本体合并到另一个本体。我使用“等效”来映射本体的相应类,并对属性进行了同样的操作。我希望SPARQL查询从两个本体中获取结果。我该如何进行?
-
 招联金融-数据岗-面经
招联金融-数据岗-面经笔试(10.11) 岗位是数据开发,一道编程,几十道选择。难度不大,但涉及面挺广。 一面(10.15) 笔试完,隔天约面,效率很高。 项目介绍,自己的分工 特征选择方法 数据挖掘中对于缺失值的处理方案 说一下Python(pandas)中常用的数据处理算子。 Spark的原理,分布式是怎么搭建的。 Sql中union和union all的区别 数据行转列怎么操作 xgboost和gbdt的区别 x
-
 10.12花旗金融面试记录
10.12花旗金融面试记录部门:个人银行部 岗位:面试官说的只有应用开发岗,然后我是数分,尴尬 面试过程: 一位leader+2位同事。 英语部分—— 英语自我介绍、爱好、职业方向。 我说我想找数分的,然后他就英语问我他们部门只有开发的,跟我的职业方向不匹配,我能不能接受。 笔试题拷打—— 紧接着,他打开了我的笔试题。。。 首先问我错的题目为什么选错了,然后让我描述一下我的编程题的思路,逻辑,时间复杂度,以及代码内部的一些
-
 中邮消费金融 Java 一面
中邮消费金融 Java 一面这个面试是AI面和笔试之后的第一个面试。两个面试官,一个开摄像头,一个不开 自我介绍 项目是实习的还是练手的 项目里面DDD架构是怎么分领域的?自己设计的还是公开文档分好的 使用了Dubbo,里面是怎样一个服务注册和调用情况 对RPC了解多少,和HTTP那些有什么不同 用了什么MQ消息中间件,Kafka,是怎么保证消息可靠性的 分库分表里面是怎么做多表里面数据排序等,用ES 项目的最大难点和项目中
-
 中邮消费金融java一面
中邮消费金融java一面1.自我介绍 2.说一说java中的异常 3.说一下java如何访问数据库 4.说一下jdbc(这个没背) 5.说一下spring的优势(不太清楚,随便说的) 6.说一下事务 7.说一个团队合作案例,如果产生不同意见如何处理 8.学习或者工作上你的一个难点 9.反问 项目一个没问,5,3,4都答得不好,感觉凉凉